
Qwen-Image-i2L: Crea un artista de IA personalizado con una sola imagen: Guía completa para la creación de imágenes personalizadas
Qwen-Image-i2L: Crea tu propio artista IA con una sola imagen, Guía completa para la creación de imágenes personalizadas
¿Alguna vez has deseado que la IA aprenda tu estilo de ilustración favorito, pero te has frustrado por no tener docenas de materiales y costoso poder computacional? Ahora, una sola imagen es suficiente. Qwen-Image-i2L, de código abierto del laboratorio Tongyi de Alibaba, es precisamente una herramienta revolucionaria que te permite personalizar tu propio artista IA "como si construyeras un Lego" con solo una imagen.
Este artículo te guiará desde cero para que domines rápidamente el uso de esta "varita mágica de estilos".
I. Primeros pasos con i2L: ¿Qué es y por qué es tan poderoso?
Qwen-Image-i2L es una herramienta de transferencia de estilo personalizada. Su núcleo es "Image to LoRA", lo que significa que descompone y "comprime" las características clave de estilo de una imagen de entrada en un módulo adaptador LoRA (Low-Rank Adaptation) ligero.
Principio fundamental: El "arte de descomponer estilos" que simplifica lo complejo
Las IA tradicionales necesitan grandes cantidades de datos y tiempo de entrenamiento para aprender nuevos estilos. La innovación de i2L radica en su mecanismo de descomposición de imágenes: descompone inteligentemente una imagen en "piezas" aprendibles como "tono de color", "trazos de textura", "elementos de composición", etc. Estas piezas se encapsulan en un archivo LoRA de solo unos pocos GB, que luego se puede cargar como un complemento en modelos de generación de imágenes a partir de texto como Stable Diffusion para generar innumerables nuevas obras del mismo estilo.

En resumen, su flujo de trabajo se puede resumir en los siguientes tres pasos:
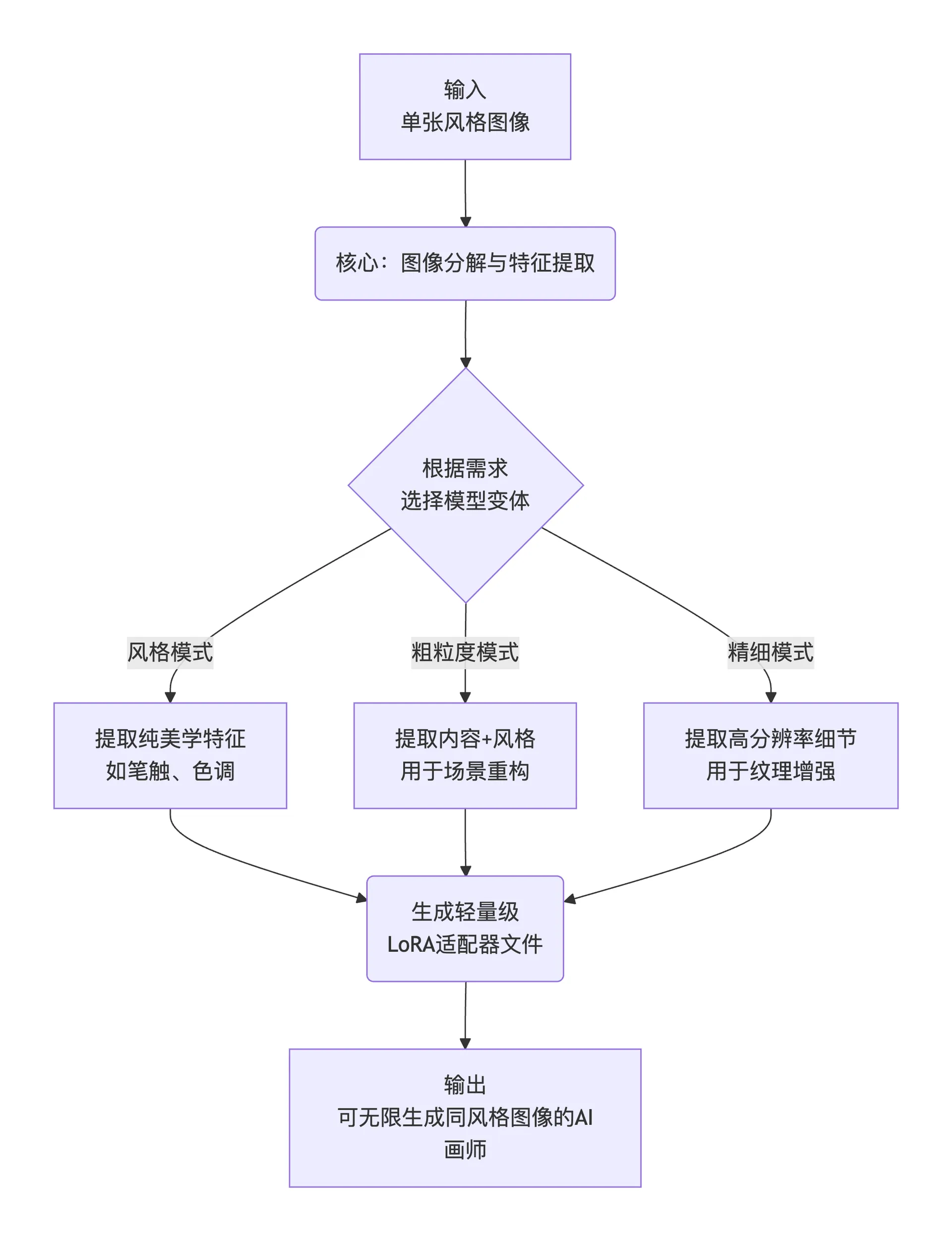
flowchart TD
A[Entrada<br>Imagen de estilo única] --> B(Núcleo: descomposición y extracción de características de imagen)
B --> C{Según las necesidades<br>seleccionar variante del modelo}
C -- Modo de estilo --> D1[Extraer características puramente estéticas<br>como trazos, tonos]
C -- Modo de granularidad gruesa --> D2[Extraer contenido + estilo<br>para reconstrucción de escenas]
C -- Modo fino --> D3[Extraer detalles de alta resolución<br>para mejora de texturas]
D1 & D2 & D3 --> E(Generar archivo adaptador<br>LoRA ligero)
E --> F[Salida<br>Artista IA que puede generar infinitas imágenes del mismo estilo]
Análisis profundo de los principios
El núcleo del modelo es el pipeline de conversión de imagen a LoRA: la imagen de entrada primero pasa por un codificador (como SigLIP2 para extraer semántica, DINOv3 para capturar patrones visuales, Qwen-VL para procesar detalles de alta resolución) para convertirlos en vectores incrustados, luego estos vectores se mapean directamente a matrices LoRA (matrices de bajo rango A y B). LoRA es esencialmente un "parche" para el modelo base (como Qwen-Image), que actualiza solo unos pocos parámetros (generalmente <1%), logrando una inyección eficiente.
Las cuatro variantes están diseñadas para diferentes necesidades:
- Style (2.4B): Se especializa en extracción de estilo, con preservación de débil detalle pero fuerte captura de estilo. Codificador: SigLIP2 + DINOv3.
- Coarse (7.9B): Extiende Style, captura inicialmente el contenido, pero los detalles no son perfectos. Agrega Qwen-VL (resolución 224x224) al codificador.
- Fine (7.6B): Actualización incremental de Coarse, eleva a resolución 1024x1024, se enfoca en detalles. Debe usarse combinado con Coarse.
- Bias (30M): LoRA estático, corrige la desviación de estilo entre las imágenes generadas y el modelo base Qwen-Image (como preferencias de color).
La siguiente figura es un diagrama de arquitectura LoRA general, Qwen-Image-i2L agrega una capa de entrada de imagen sobre esta base:
![]()
Las limitaciones incluyen generalización insuficiente (una sola imagen difícilmente puede capturar la lógica 3D) y pérdida de detalles (texturas complejas pueden requerir múltiples imágenes de entrada). La investigación muestra que el uso de Bias puede mejorar la compatibilidad en un 20-30% (basado en comparaciones de ejemplos).
¿Por qué prestarle atención? Cuatro ventajas principales
- Umbral extremadamente bajo: Adiós al proceso tradicional que requiere 20+ imágenes y clústeres GPU, una imagen y una computadora común son suficientes.
- Eficiencia extremadamente alta: Desde la preparación hasta generar un modelo de estilo utilizable, el tiempo se reduce de varias horas a pocos minutos.
- Calidad excepcional: El LoRA generado puede capturar con precisencia la esencia de la imagen original, integrándose perfectamente en los flujos de trabajo de pintura IA principales.
- Uso flexible: Ya sea aplicar el estilo de "La noche estrellada" a edificios modernos o迁移 el estilo anime a fotos reales, puedes probar rápidamente.
II. Guía práctica: Usando i2L desde cero
1. Preparación del entorno
Al igual que al usar el modelo base Qwen-Image, necesitas un entorno Python. Dado que i2L se desarrolló basándose en el poderoso Qwen-Image (arquitectura MMDiT de 20 mil millones de parámetros), tiene ciertos requisitos de hardware.
Aquí tienes una referencia de configuración recomendada:
| Hardware | Requisito mínimo | Configuración recomendada |
|---|---|---|
| GPU | NVIDIA GTX 1080 Ti (8GB) | NVIDIA RTX 4090 D o superior |
| Memoria | 16GB | 32GB o más |
| Almacenamiento | 50GB espacio disponible | 100GB SSD |
2. Elige tu "varita mágica": Cuatro variantes de modelo
i2L no es una solución única, ofrece cuatro modelos optimizados para diferentes escenarios, y debes elegir según tus objetivos de creación:
| Variante del modelo | Escala de parámetros | Uso principal | Escenarios adecuados |
|---|---|---|---|
| Modo de estilo | 2.4B | Especializado en migración de estética pura | Aprender trazos de acuarela, texturas de óleo, tonos de filtros específicos |
| Modo de granularidad gruesa | 7.9B | Capturar contenido y estilo, para reconstrucción de escenas | Transformar escenas urbanas en ciberpunk, paisajes en mundos de hadas |
| Modo fino | 7.6B | Generar detalles de alta resolución 1024x1024 | Cuando se necesita resaltar detalles como pelaje animal, ladrillos de edificios, texturas de tela, etc. |
| Modo de sesgo | 30M | Asegurar que la salida sea consistente con el estilo nativo de Qwen-Image | Para unificar el estilo visual de materiales promocionales empresariales, evitar que la marca "se desvíe" |
Sugerencia para principiantes: Comienza con el modo de estilo o el modo de granularidad gruesa, pueden manejar la mayoría de las necesidades comunes.
3. Pasos principales: Entrenando tu LoRA con una sola imagen
Aquí tienes un flujo de trabajo operativo simplificado, para el código específico consulta el repositorio oficial de GitHub del proyecto.
Paso 1: Obtener el modelo
Todos los modelos están de código abierto, puedes buscar "Qwen-Image-i2L" en las plataformas Hugging Face o ModelScope y descargarlos gratuitamente.
Paso 2: Prepara tu imagen de estilo
- Elige una imagen que represente claramente el estilo que deseas.
- Asegúrate de que la imagen tenga alta calidad, con elementos clave claros.
- (Opcional) Si quieres aprender un sujeto específico (como un gato específico), intenta usar una imagen donde el sujeto sea prominente.
Paso 3: Ejecutar el script de entrenamiento
El proceso de entrenamiento generalmente requiere solo un comando. Debes especificar la ruta de la imagen de entrada, la ubicación de guardado del LoRA de salida, y seleccionar el tipo de modelo correspondiente de la tabla anterior.
# Comando de ejemplo (solo como referencia, consulta la documentación oficial)
python train_i2l.py \
--input_image "tu_imagen.webp" \
--model_type "style" \ # Seleccionar "modo de estilo" aquí
--output_lora "./mi_estilo_lora.safetensors"
Paso 4: Usar el LoRA generado para crear
Una vez completado el entrenamiento, obtendrás un archivo .safetensors. En Stable Diffusion WebUI (como Automatic1111) o ComfyUI:
- Coloca el archivo LoRA en la carpeta de modelos correspondiente.
- Al generar imágenes, llama a ese LoRA a través de sintaxis específica (como
<lora:mi_estilo_lora:1>) en el prompt. - Ingresa tu descripción de contenido y podrás generar nuevas imágenes que fusionan el estilo personalizado.

4. Técnicas de ajuste de parámetros y prompts
- Los prompts son clave: Los modelos de la serie Qwen son conocidos por su poderosa capacidad de comprensión y renderizado de texto. Al generar la imagen final, combinar prompts de contenido claros con LoRA produce mejores resultados. Por ejemplo: "
<lora:van Gogh_starry_night:0.8>, un rascacielos moderno, cielo nocturno, estrellas en forma de remolino, pinceladas de óleo." - Controlar la intensidad de LoRA: Generalmente, se puede ajustar el peso en la sintaxis de llamada (por ejemplo, cambiar
:1a:0.7), cuanto menor es el peso, más débil es la influencia del estilo y la fusión con el contenido es más natural. - Usar prompts negativos: Excluir elementos no deseados, como "blurry, deformed, ugly" para mejorar la calidad de la imagen.
5. Código de inferencia recomendado oficialmente
Instalar DiffSynth-Studio:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
Qwen-Image-i2L-Style
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
# Load models
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Style.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
# Load images
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/style/1/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/style/1/0.webp"),
Image.open("data/examples/assets/style/1/1.webp"),
Image.open("data/examples/assets/style/1/2.webp"),
Image.open("data/examples/assets/style/1/3.webp"),
Image.open("data/examples/assets/style/1/4.webp"),
]
# Model inference
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
save_file(lora, "model_style.safetensors")
Qwen-Image-i2L-Coarse、Qwen-Image-i2L-Fine、Qwen-Image-i2L-Bias
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from diffsynth.utils.lora import merge_lora
from diffsynth import load_state_dict
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
Cargar modelos
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Coarse.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Fine.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
Cargar imágenes
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/lora/3/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/lora/3/0.webp"),
Image.open("data/examples/assets/lora/3/1.webp"),
Image.open("data/examples/assets/lora/3/2.webp"),
Image.open("data/examples/assets/lora/3/3.webp"),
Image.open("data/examples/assets/lora/3/4.webp"),
Image.open("data/examples/assets/lora/3/5.webp"),
]
Inferencia del modelo
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
lora_bias = ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Bias.safetensors")
lora_bias.download_if_necessary()
lora_bias = load_state_dict(lora_bias.path, torch_dtype=torch.bfloat16, device="cuda")
lora = merge_lora([lora, lora_bias])
save_file(lora, "model_coarse_fine_bias.safetensors")
#### Usar el LoRA generado para crear imágenes
```py
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
vram_config = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": torch.bfloat16,
"onload_device": "cpu",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors", **vram_config),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
pipe.load_lora(pipe.dit, "model_style.safetensors")
image = pipe("a cat", seed=0, height=1024, width=1024, num_inference_steps=50)
image.save("image.webp")
6. Ejemplos oficiales
Estilo
El modelo Qwen-Image-i2L-Style se puede utilizar para generar rápidamente LoRA de estilo, simplemente ingresando algunas imágenes con estilo uniforme. A continuación se muestran los resultados que generamos, con una semilla aleatoria de 0 en todos los casos.
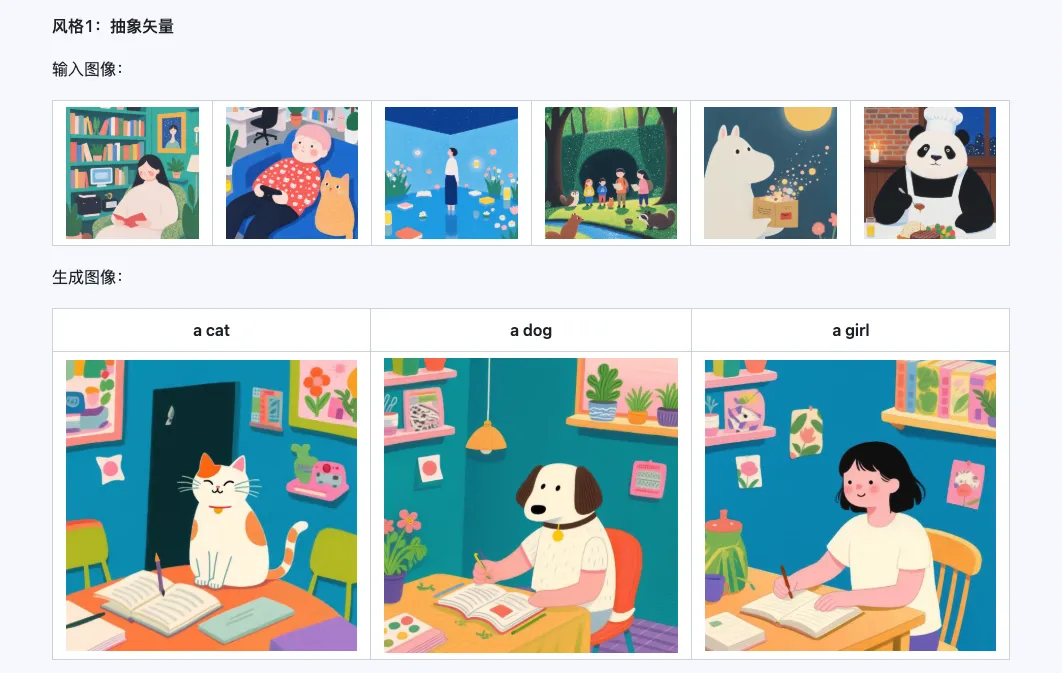
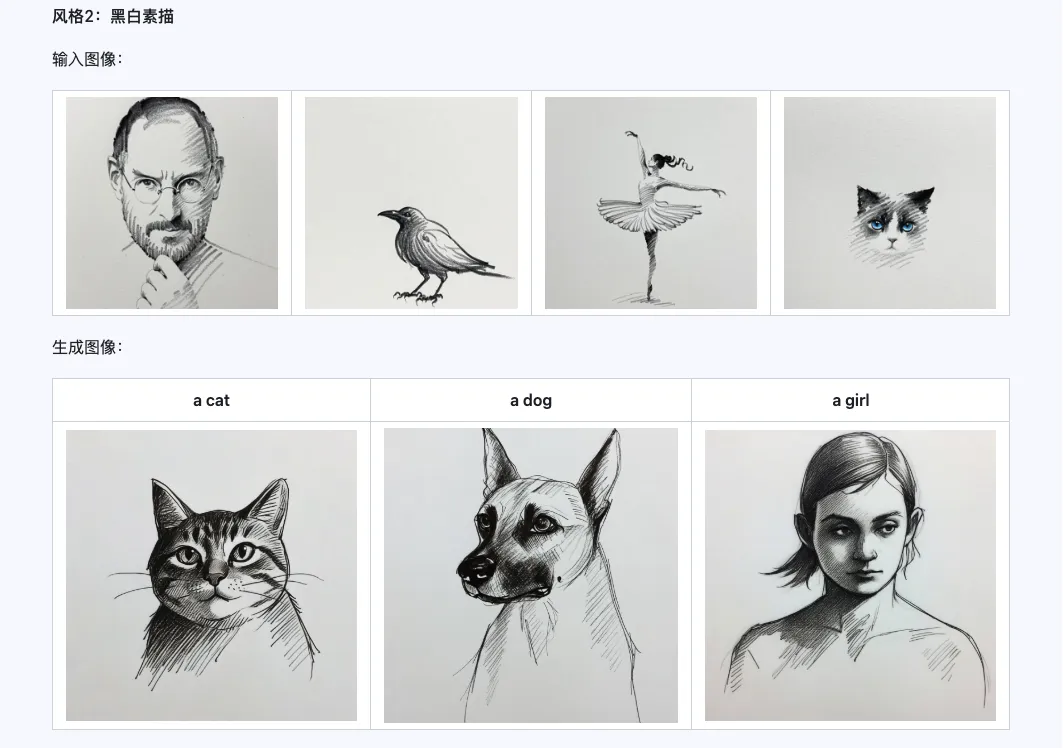
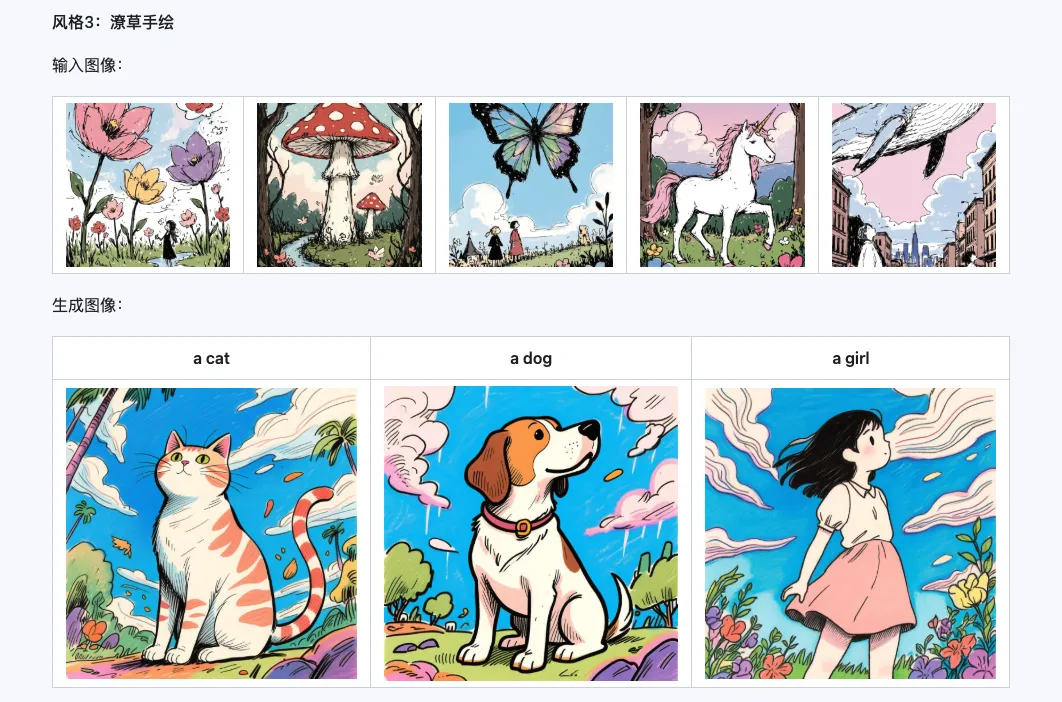
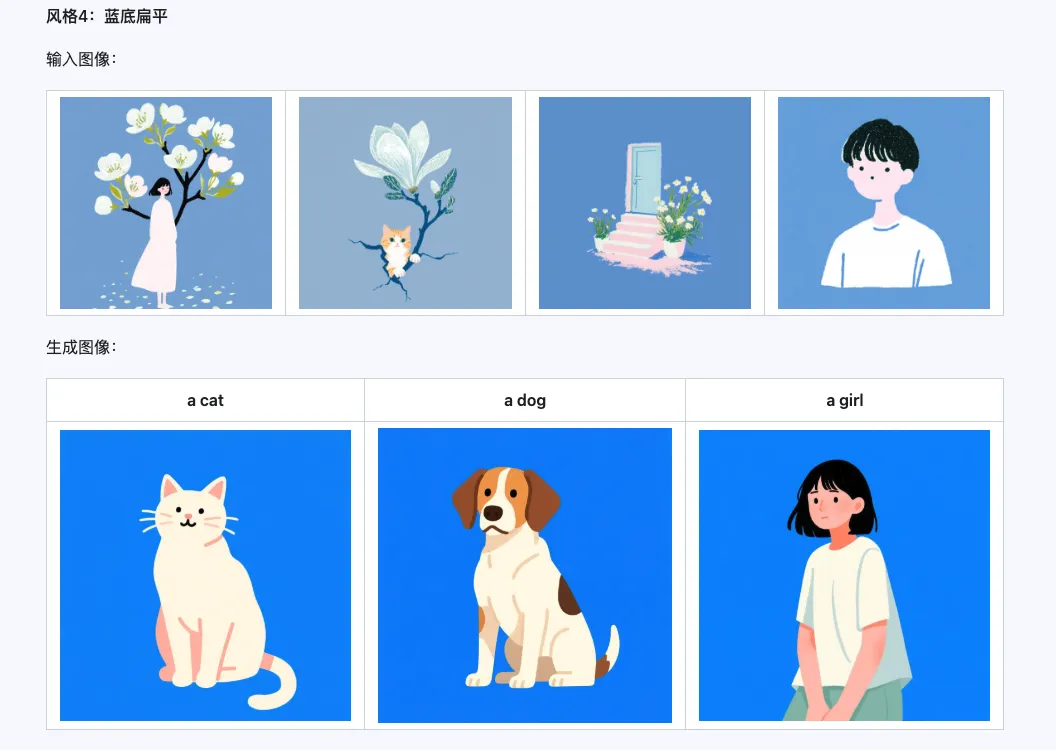
Grueso + Fino + Sesgo
La combinación de Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine y Qwen-Image-i2L-Bias puede generar pesos de LoRA que conservan el contenido y la información detallada de la imagen. Este conjunto de pesos como pesos de inicialización para el entrenamiento de LoRA puede acelerar la velocidad de convergencia.
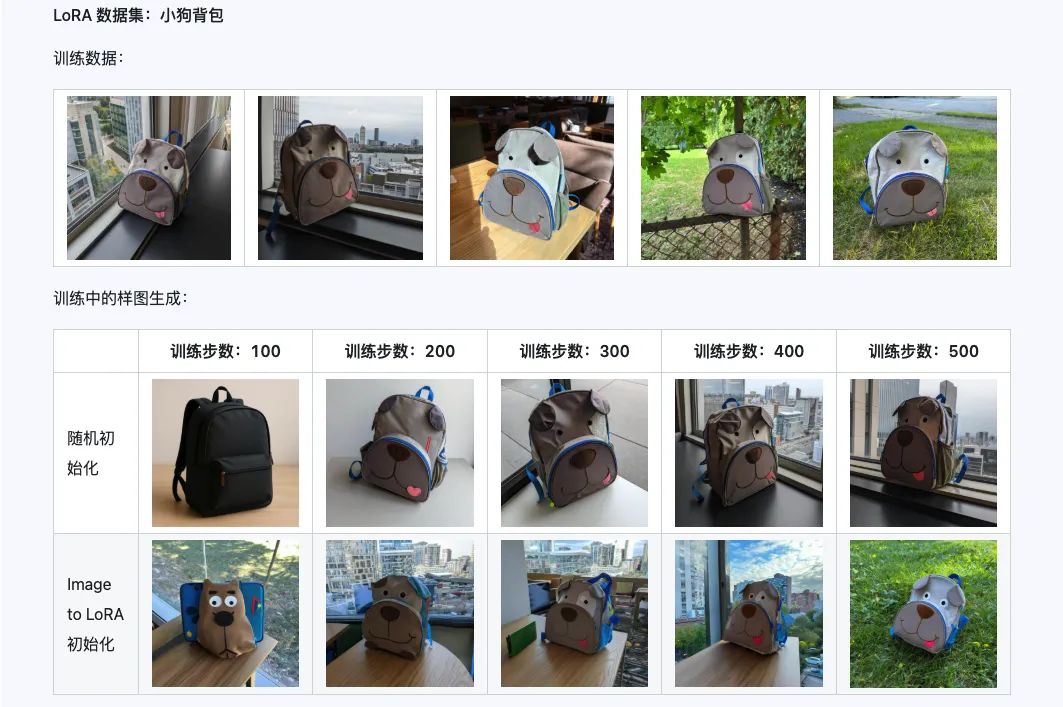
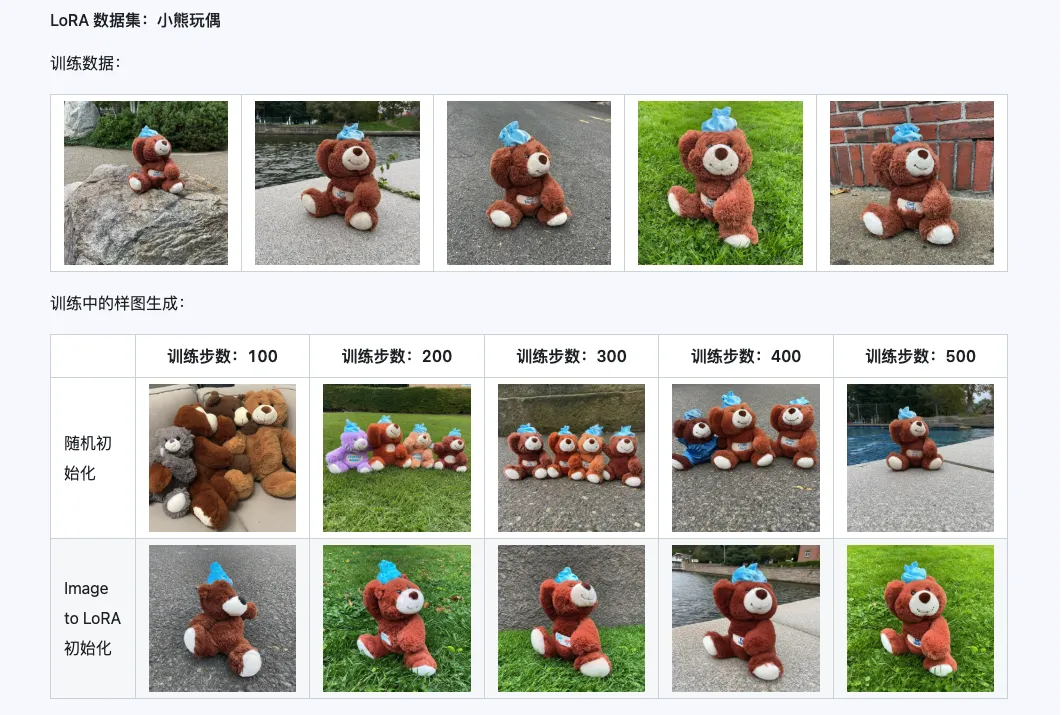

Tres, Escenarios de aplicación: Tu acelerador de creatividad
- Creación artística personal: Prueba rápidamente diversos estilos de maestros o establece un estilo coherente para tu portafolio.
- E-commerce y marketing: Generar rápidamente imágenes promocionales de estilo uniforme pero con diferentes contenidos para diversas líneas de productos, reduciendo significativamente los costos de fotografía y diseño.
- Conceptos para juegos y cine: Transferir rápidamente el estilo de un arte original a múltiples escenas y diseños de personajes, generando eficientemente conceptos visuales.
- Gestión visual de marca: Utilizar el "modo de sesgo" para garantizar que todos los materiales de marketing generados por IA cumplan estrictamente con las especificaciones de identidad visual de la marca.
Cuatro, Consideraciones y futuro
- Limitaciones actuales: Existen desafíos al derivar la lógica 3D a partir de una sola imagen 2D. Por ejemplo, al entrenar con una imagen de "un gato en el sofá", las imágenes generadas pueden mostrar objetos flotando o deformados en otros ángulos. Para estilos tridimensionales complejos, preparar imágenes desde múltiples ángulos sigue siendo la mejor opción.
- Desarrollo futuro: i2L marca la entrada de la generación de imágenes de IA en la era de la "personalización instantánea". Se puede prever que en el futuro surgirán más aplicaciones como "generar con un clic viñetas de cómic" o "diseñar personajes con un clic", haciendo que la creación personalizada con IA sea más accesible.
¡Ahora, encuentra la imagen que mejor represente la estética de tu corazón y comienza a crear tu propio artista de IA personalizado!
Esta guía de operación se basa en la documentación técnica de código abierto de Qwen-Image-i2L y las prácticas de la comunidad. Los métodos de uso específicos del modelo pueden actualizarse, por lo que se recomienda consultar también las páginas principales del proyecto en z-image.me, Hugging Face o ModelScope para obtener la información más reciente.