
Qwen-Image-i2L:單圖打造專屬AI畫師,個性化圖像創作全攻略
Qwen-Image-i2L:單圖打造專屬AI畫師,個性化圖像創作全攻略
你是否曾希望AI能學會你最喜歡的插畫風格,但苦於沒有幾十張素材和昂貴的算力?現在,一張圖就夠了。阿里通義實驗室開源的 Qwen-Image-i2L 正是這樣一款革命性工具,它讓你像"拼樂高"一樣,用單張圖片就能定制出屬於自己的AI畫師。
本文將帶你從零開始,快速掌握這個"風格魔法棒"的使用方法。
一、初識i2L:它是什麼,為何強大?
Qwen-Image-i2L 是一個個性化風格遷移工具。它的核心是 "Image to LoRA",意為將一張輸入圖像的關鍵風格特徵,分解並"壓縮"成一輕量級的LoRA(Low-Rank Adaptation)適配器模組。
核心原理:化繁為簡的"風格拆解術"
傳統AI學習新風格需要海量數據和長時間訓練。i2L的創新在於其圖像分解機制:它像拆解盲盒一樣,智能地將一張圖片分解為"顏色基調"、"紋理筆觸"、"構圖元素"等可學習的"零件"。這些零件被封裝進一個僅有幾GB大小的LoRA文件裡,之後就可以像插件一樣,加載到Stable Diffusion等主流文生圖模型中,生成無數張同風格的新作品。

簡單來說,其工作流程可以概括為以下三步:
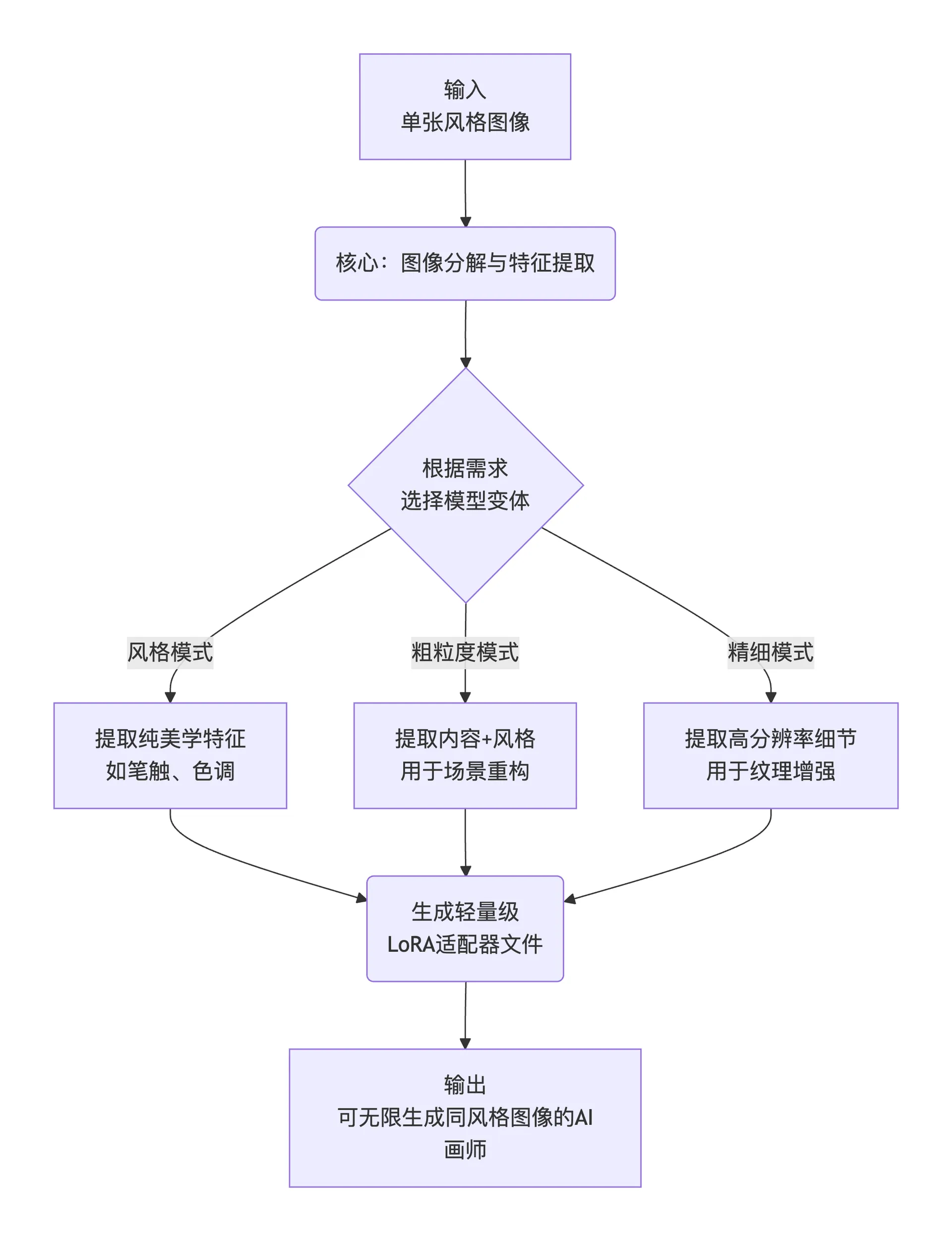
flowchart TD
A[輸入<br>單張風格圖像] --> B(核心:圖像分解與特徵提取)
B --> C{根據需求<br>選擇模型變體}
C -- 風格模式 --> D1[提取純美學特徵<br>如筆觸、色調]
C -- 粗粒度模式 --> D2[提取內容+風格<br>用於場景重構]
C -- 精細模式 --> D3[提取高分辨率細節<br>用於紋理增強]
D1 & D2 & D3 --> E(生成輕量級<br>LoRA適配器文件)
E --> F[輸出<br>可無限生成同風格圖像的AI畫師]
深入原理剖析
模型的核心是圖像到LoRA的轉換管道:輸入圖像先通過編碼器(如SigLIP2提取語義、DINOv3捕捉視覺模式、Qwen-VL處理高分辨率細節)轉化為嵌入向量,然後這些向量直接映射到LoRA矩陣(低秩矩陣A和B)。LoRA本質上是基礎模型(如Qwen-Image)的"補丁",只更新少量參數(通常<1%),實現高效注入。
四個變體設計針對不同需求:
- Style (2.4B): 專注風格提取,細節保存弱,但風格捕捉強。編碼器:SigLIP2 + DINOv3。
- Coarse (7.9B): 擴展Style,初步捕捉內容,但細節不完美。編碼器添加Qwen-VL (224x224分辨率)。
- Fine (7.6B): Coarse的增量升級,提升到1024x1024分辨率,專注細節。必須與Coarse結合使用。
- Bias (30M): 靜態LoRA,修正生成圖像與Qwen-Image底模的風格偏差(如顏色偏好)。
下圖是一個通用LoRA架構示意圖,Qwen-Image-i2L在這基礎上添加圖像輸入層:
![]()
局限性包括泛化不足(單圖難以捕捉3D邏輯)和細節丟失(複雜紋理可能需多圖輸入)。研究顯示,使用Bias可提升兼容性達20-30%(基於示例比較)。
為何要關注它?四大核心優勢
- 門檻極低:告別需要20張以上圖片和GPU集群的傳統流程,一張圖加普通電腦即可。
- 效率極高:從準備到生成可用的風格模型,耗時從數小時縮短至幾分鐘。
- 品質出色:生成的LoRA能精準捕捉原圖精髓,無縫融入主流AI繪畫流程。
- 用途靈活:無論是將《星月夜》的風格用現代建築上,還是把動漫風遷移到真人照片,都能快速嘗試。
二、實戰指南:從零開始使用i2L
1. 環境準備
與使用基礎的Qwen-Image模型類似,你需要一個Python環境。由於i2L基於強大的Qwen-Image(200億參數MMDiT架構) 開發,因此對硬件有一定要求。
以下是推薦的配置參考:
| 硬件 | 最低要求 | 推薦配置 |
|---|---|---|
| GPU | NVIDIA GTX 1080 Ti (8GB) | NVIDIA RTX 4090 D或更高 |
| 內存 | 16GB | 32GB 或以上 |
| 存儲 | 50GB 可用空間 | 100GB SSD |
2. 選擇你的"魔法棒":四款模型變體
i2L並非一刀切,它提供了四款針對不同場景優化的模型,你需要根據創作目標進行選擇:
| 模型變體 | 參數規模 | 核心用途 | 適合場景 |
|---|---|---|---|
| 風格模式 | 2.4B | 專攻純美學風格遷移 | 學習水彩筆觸、油畫質感、特定濾鏡色調 |
| 粗粒度模式 | 7.9B | 捕捉內容與風格,進行場景重構 | 把街景變賽博朋克,把風景變童話世界 |
| 精細模式 | 7.6B | 生成1024x1024高分辨率細節 | 需突出動物毛髮、建築磚塊、織物紋理等細節時 |
| 偏見模式 | 30M | 確保輸出與Qwen-Image原生風格一致 | 企業統一宣傳圖視覺風格,防止品牌"跑偏" |
新手建議:從風格模式或粗粒度模式開始嘗試,它們能處理大多數常見需求。
3. 核心步驟:單圖訓練你的LoRA
以下是一個簡化的操作流程,具體代碼請以項目官方GitHub倉庫為準。
第一步:獲取模型
所有模型均已開源,你可以在 Hugging Face 或 ModelScope 平台搜索"Qwen-Image-i2L"並免費下載。
第二步:準備你的風格圖像
- 選擇一張能清晰代表你所需風格的圖片。
- 確保圖片品質較高,重點元素清晰。
- (可選)如果想學習特定主體(如某隻貓),盡量使用主體突出的圖片。
第三步:運行訓練腳本
訓練過程通常只需一條命令。你需要指定輸入圖片路徑、輸出LoRA的保存位置,以及選擇上表中對應的模型類型。
# 示例命令(僅供參考,請以官方文檔為準)
python train_i2l.py \
--input_image "你的圖片.webp" \
--model_type "style" \ # 此處選擇"風格模式"
--output_lora "./my_style_lora.safetensors"
第四步:使用生成的LoRA進行創作
訓練完成後,你會得到一個 .safetensors 文件。在Stable Diffusion WebUI(如Automatic1111)或ComfyUI中:
- 將LoRA文件放入對應的模型文件夾。
- 在生成圖片時,在提示詞中通過特定語法(如
<lora:my_style_lora:1>)調用該LoRA。 - 輸入你的內容描述,即可生成融合了自定義風格的新圖像。

4. 調參與提示詞技巧
- 提示詞是關鍵:Qwen系列模型以強大的文本理解和渲染能力著稱。在生成最終圖像時,結合清晰的內容提示詞和LoRA,效果更佳。例如:"
<lora:van Gogh_starry_night:0.8>, 一座現代摩天大樓,夜空,漩渦狀的星光,油畫筆觸。" - 控制LoRA強度:通常可以在調用語法中調整權重(如將
:1改為:0.7),權重越低,風格影響越弱,與內容的融合更自然。 - 使用負向提示詞:排除不想要的元素,如"blurry, deformed, ugly"來提升畫面質量。
5. 官方推薦推理代碼
安裝 DiffSynth-Studio:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
Qwen-Image-i2L-Style
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
# 載入模型
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Style.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
# 載入圖像
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/style/1/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/style/1/0.webp"),
Image.open("data/examples/assets/style/1/1.webp"),
Image.open("data/examples/assets/style/1/2.webp"),
Image.open("data/examples/assets/style/1/3.webp"),
Image.open("data/examples/assets/style/1/4.webp"),
]
# 模型推理
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
save_file(lora, "model_style.safetensors")
Qwen-Image-i2L-Coarse、Qwen-Image-i2L-Fine、Qwen-Image-i2L-Bias
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from diffsynth.utils.lora import merge_lora
from diffsynth import load_state_dict
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
載入模型
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Coarse.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Fine.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
載入圖像
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/lora/3/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/lora/3/0.webp"),
Image.open("data/examples/assets/lora/3/1.webp"),
Image.open("data/examples/assets/lora/3/2.webp"),
Image.open("data/examples/assets/lora/3/3.webp"),
Image.open("data/examples/assets/lora/3/4.webp"),
Image.open("data/examples/assets/lora/3/5.webp"),
]
模型推論
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
lora_bias = ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Bias.safetensors")
lora_bias.download_if_necessary()
lora_bias = load_state_dict(lora_bias.path, torch_dtype=torch.bfloat16, device="cuda")
lora = merge_lora([lora, lora_bias])
save_file(lora, "model_coarse_fine_bias.safetensors")
#### 使用生成的 LoRA 生成圖像
```py
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
vram_config = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": torch.bfloat16,
"onload_device": "cpu",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors", **vram_config),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
pipe.load_lora(pipe.dit, "model_style.safetensors")
image = pipe("a cat", seed=0, height=1024, width=1024, num_inference_steps=50)
image.save("image.webp")
6. 官方範例
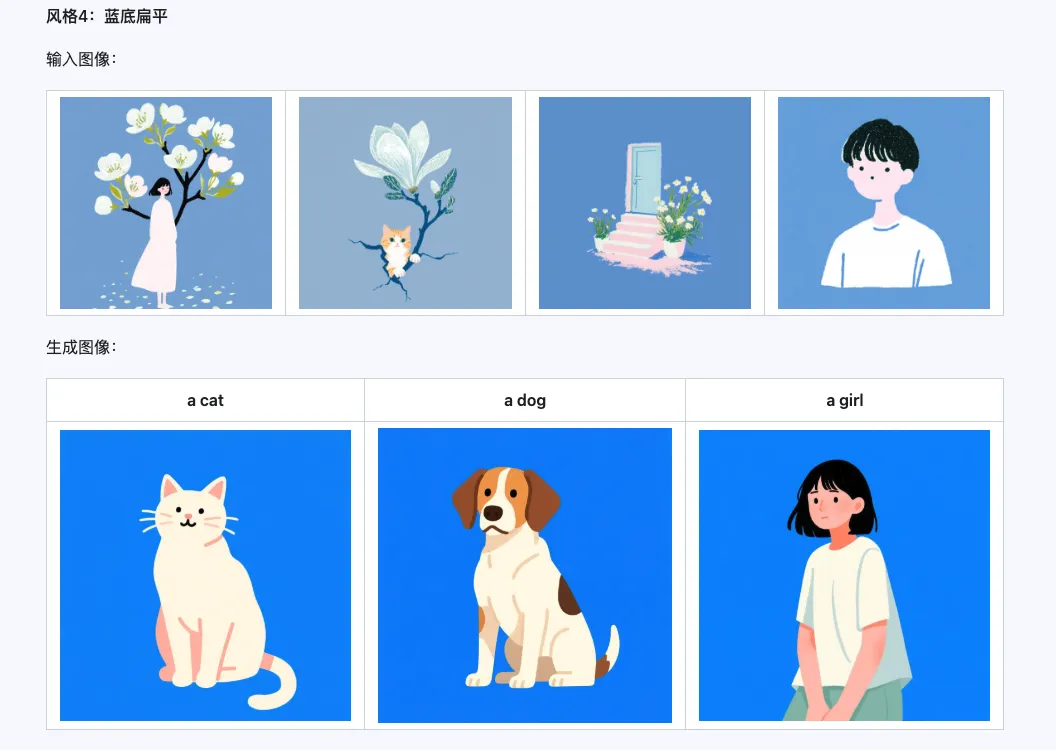
風格
Qwen-Image-i2L-Style 模型可用於快速生成風格 LoRA,只需輸入幾張風格統一的圖像。以下是我們生成的結果,隨機種子都是 0。
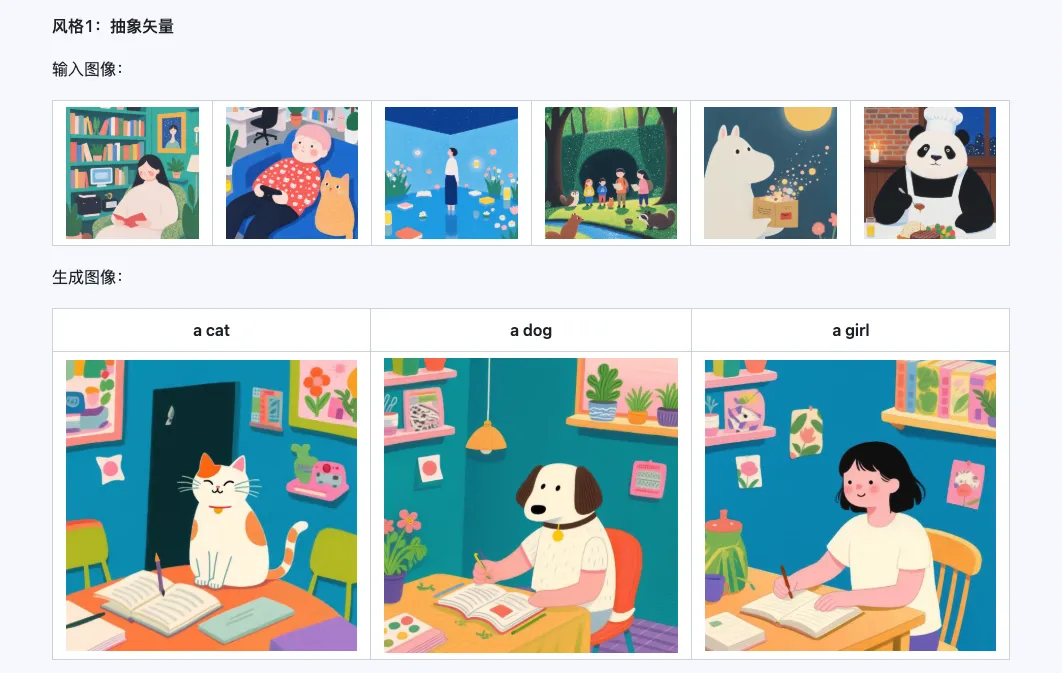
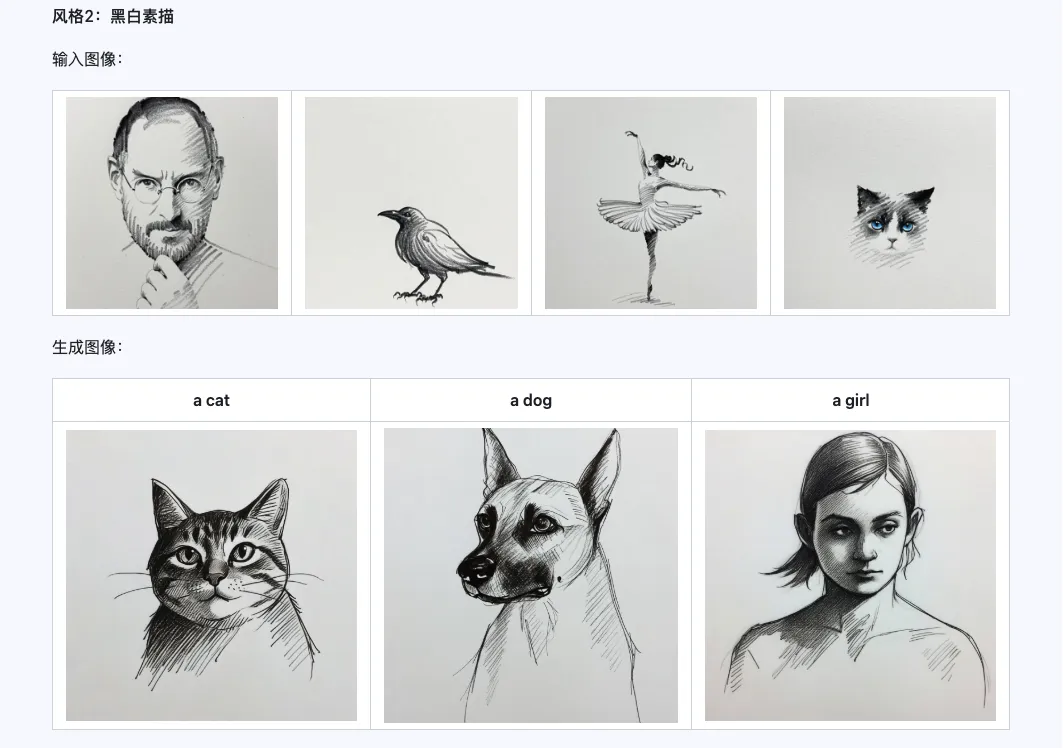
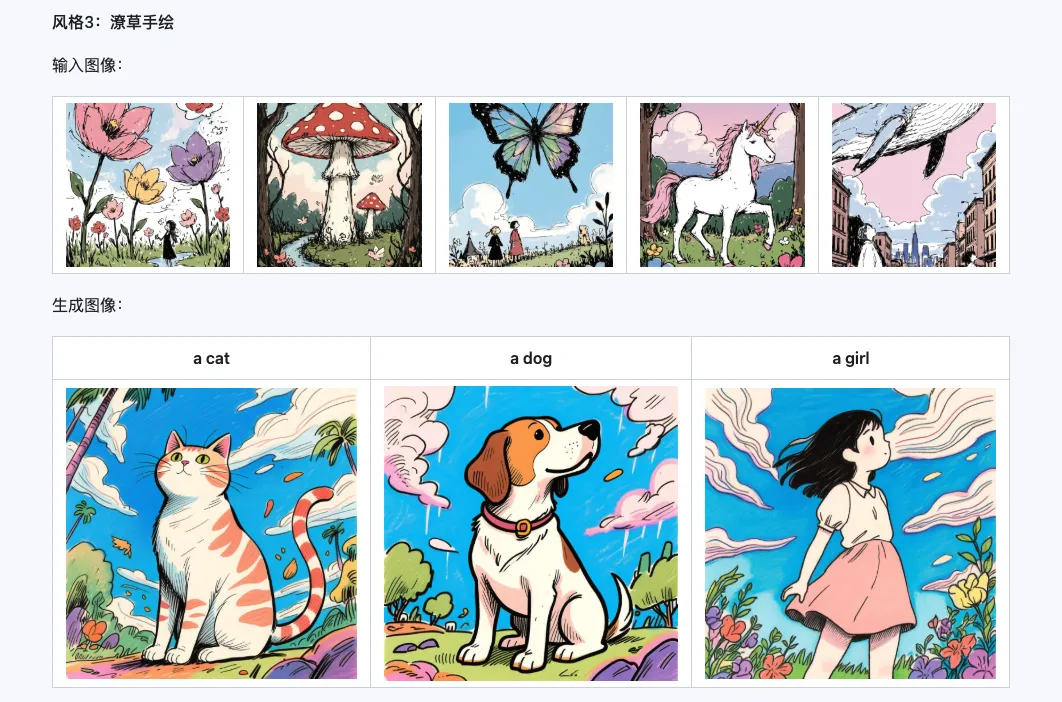
粗粒度 + 細粒度 + 偏差
Qwen-Image-i2L-Coarse、Qwen-Image-i2L-Fine、Qwen-Image-i2L-Bias 三者組合後可以生成保留圖像內容和細節資訊的 LoRA 權重,這組權重作為 LoRA 訓練的初始化權重能夠加速收斂速度。
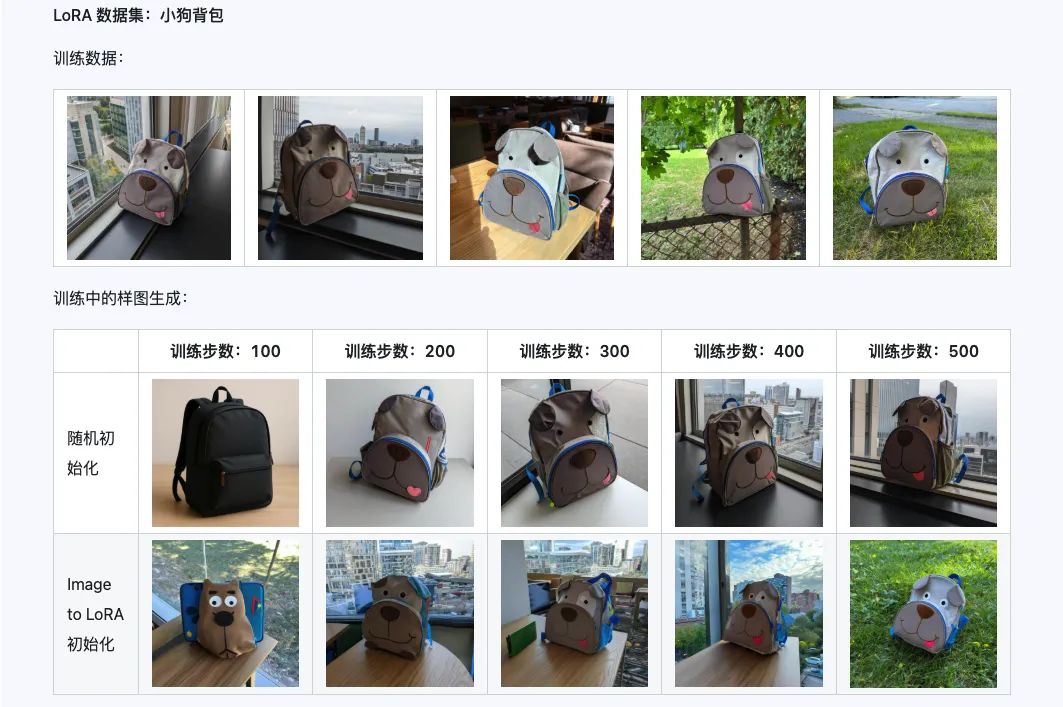
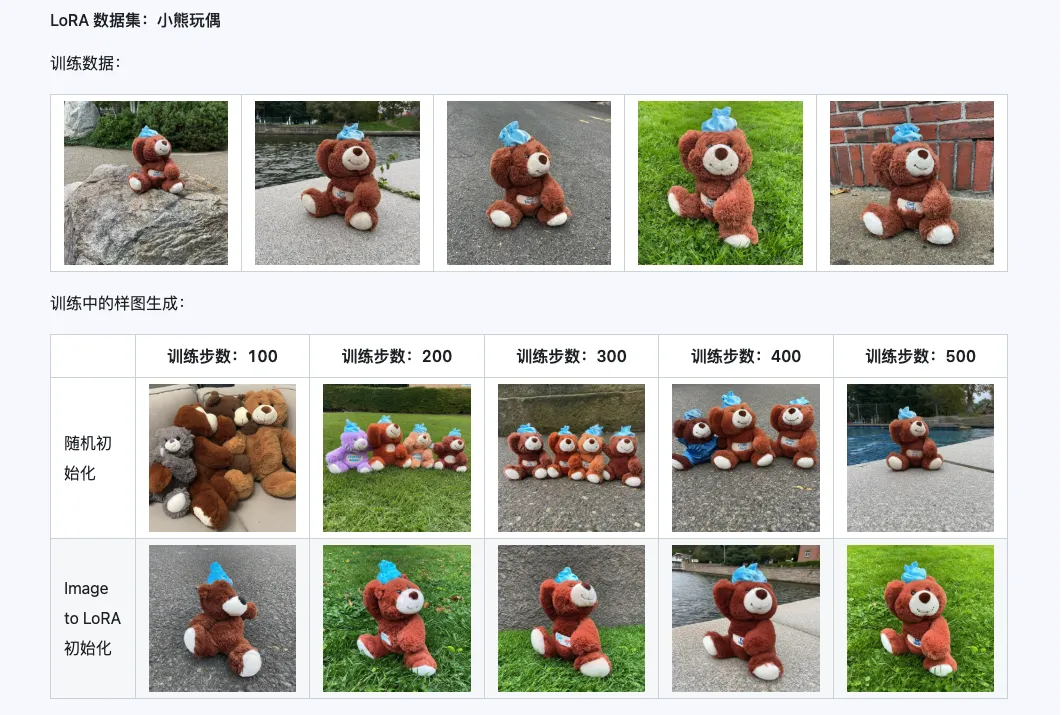

三、應用場景:你的創意加速器
- 個人藝術創作:快速嘗試多種大師畫風,或為自己的作品集建立統一風格。
- 電商與行銷:為不同產品線快速生成統一風格、不同內容的宣傳圖,大幅降低拍攝和設計成本。
- 遊戲與影視概念:快速將一張原畫風格遷移到多個場景、角色設計中,高效產出概念圖。
- 品牌視覺管理:使用"偏見模式",確保所有AI生成的行銷素材嚴格符合品牌VI規範。
四、注意事項與未來
- 當前局限:從單張2D圖片推導3D邏輯存在挑戰。例如,訓練一張"貓在沙發上"的圖片,生成的圖可能在其它角度出現物體懸空或變形。對於複雜三維風格,準備多角度圖片仍是更好選擇。
- 未來發展:i2L標誌著AI圖像生成進入 "即時定制"時代。可以預見,未來會有更多"一鍵生成漫畫分鏡"、"一鍵設計角色"等應用湧現,讓個性化AI創作更加普及。
現在,就找一張最能代表你心中美學的圖片,開始打造你的專屬AI畫師吧!
本文操作指南基於 Qwen-Image-i2L 開源技術文檔及社群實踐。模型具體使用方法可能更新,建議同時查閱 z-image.me、Hugging Face 或 ModelScope 上的專案主頁獲取最新資訊。