
Qwen-Image-i2L:1枚の画像で専用AIアーティストを創造、パーソナライズド画像制作完全ガイド
Qwen-Image-i2L:単一画像でパーソナルAIアーティストを作成、パーソナライズド画像生成完全ガイド
あなたはかつて、AIがお気に入りのイラストスタイルを学んでほしいと思ったことはありますか?しかし、数十枚の素材と高価な計算リソースに悩まされたことはありませんか?今、一枚の画像で十分です。阿里通義研究所がオープンソースで提供しているQwen-Image-i2Lはまさにそのような革新的なツールで、あなたが「レゴを組み立てるように」、単一の画像で自分専用のAIアーティストをカスタマイズできるようにします。
この記事では、ゼロから始めて、この「スタイル魔法の杖」の使い方を迅速にマスターする方法を案内します。
一、初めてのi2L:それは何であり、なぜ強力なのか?
Qwen-Image-i2Lはパーソナライズドスタイル転送ツールです。その核心は**「Image to LoRA」**で、入力画像の重要なスタイル特徴を分解して「圧縮」し、軽量のLoRA(Low-Rank Adaptation)アダプタモジュールにするというものです。
核心原理:化繁为简的"风格拆解术"
従来のAIが新しいスタイルを学ぶには、膨大なデータと長時間のトレーニングが必要でした。i2Lの革新点はその画像分解メカニズムにあります:それは「ブラインドボックスを分解するように」、一枚の画像を「カラートーン」、「テクスチャの筆触」、「構図要素」などの学習可能な「部品」にスマートに分解します。これらの部品は数GBサイズのLoRAファイルにパッケージ化され、その後プラグインのようにStable Diffusionなどの主流のテキストから画像生成モデルにロードして、無数の同スタイルの新しい作品を生成できます。

簡単に言えば、そのワークフローは以下の3ステップで要約できます:
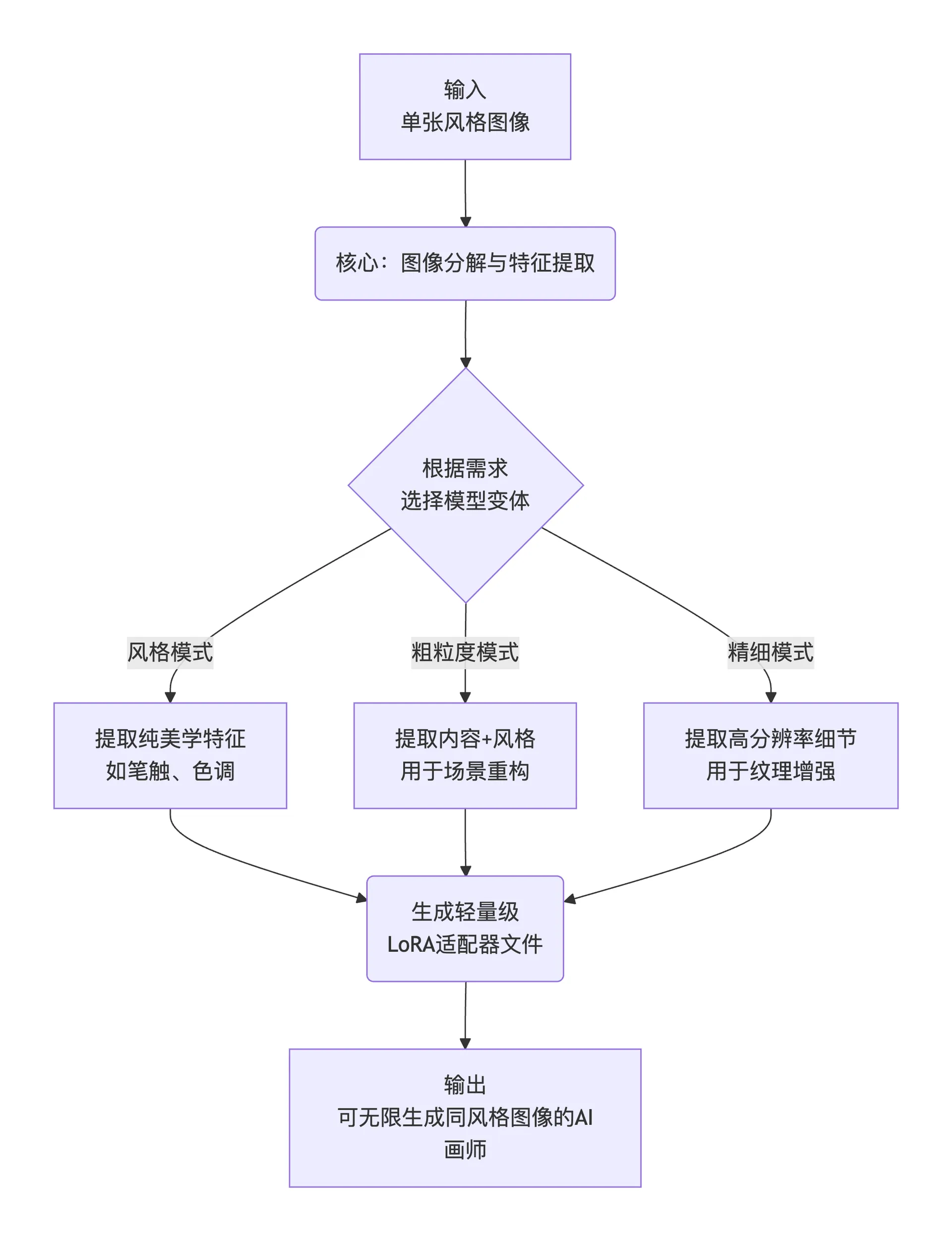
flowchart TD
A[入力<br>単一のスタイル画像] --> B(核心:画像分解と特徴抽出)
B --> C{要件に基づき<br>モデルバリアントを選択}
C -- スタイルモード --> D1[純粋な美学特徴を抽出<br>筆触、トーンなど]
C -- 粗粒度モード --> D2[内容+スタイルを抽出<br>シーン再構築用]
C -- 精細モード --> D3[高解像度の詳細を抽出<br>テクスチャ強化用]
D1 & D2 & D3 --> E(軽量な<br>LoRAアダプタファイルを生成)
E --> F[出力<br>同スタイルの画像を無限に生成できるAIアーティスト]
深入原理剖析
モデルの核心は画像からLoRAへの変換パイプラインです:入力画像はまずエンコーダ(SigLIP2で意味論を抽出、DINOv3で視覚パターンを捕捉、Qwen-VLで高解像度の詳細を処理)を通じて埋め込みベクトルに変換され、次にこれらのベクトルは直接LoRA行列(低ランク行列AとB)にマッピングされます。LoRAは本質的に基礎モデル(Qwen-Imageなど)の「パッチ」であり、少数のパラメータ(通常<1%)のみを更新して効率的に注入を実現します。
4つのバリアント設計は異なるニーズに対応しています:
- Style (2.4B): スタイル抽出に特化、詳細保存は弱いがスタイル捕捉は強い。エンコーダ:SigLIP2 + DINOv3。
- Coarse (7.9B): Styleを拡張、内容を捕捉するが詳細は不完全。エンコーダにQwen-VL (224x224解像度)を追加。
- Fine (7.6B): Coarseのインクリメンタルアップグレード、1024x1024解像度に向上、詳細に特化。Coarseと必ず組み合わせて使用する必要があります。
- Bias (30M): 静的LoRA、生成画像とQwen-Imageベースモデルのスタイル偏差(カラープリファレンスなど)を修正します。
以下は一般的なLoRAアーキテクチャの図示です、Qwen-Image-i2Lはこれに画像入力層を追加したものです:
![]()
制限事項には汎化不足(単一画像では3Dロジックを捉えきれない)と詳細の欠落(複雑なテクスチャには複数画像の入力が必要な場合がある)が含まれます。研究によると、Biasを使用すると互換性が20-30%向上することが示されています(例比較に基づく)。
为何要关注它?四大核心优势
- 非常に低いハードル:20枚以上の画像とGPUクラスターを必要とする従来のプロセスに別れを告げ、一枚の画像と普通のコンピュータで十分です。
- 非常に高い効率:準備から利用可能なスタイルモデルの生成までの時間が数時間から数分に短縮されます。
- 優れた品質:生成されたLoRAは元の画像の本質を正確に捉え、主流のAI绘画プロセスにシームレスに統合できます。
- 柔軟な用途:『星月夜』のスタイルを現代建築に適用したり、アニメ風を実写写真に転送したりする場合でも、迅速に試すことができます。
二、実践ガイド:ゼロからi2Lを使用する
1. 環境準備
基本的なQwen-Imageモデルを使用するのと同様に、Python環境が必要です。i2Lは強力なQwen-Image(200億パラメータMMDiTアーキテクチャ) をベースに開発されているため、ハードウェアには一定の要件があります。
以下は推奨される設定の参考です:
| 硬件 | 最低要求 | 推荐配置 |
|---|---|---|
| GPU | NVIDIA GTX 1080 Ti (8GB) | NVIDIA RTX 4090 Dまたはそれ以上 |
| 内存 | 16GB | 32GB またはそれ以上 |
| 存储 | 50GB 利用可能な空間 | 100GB SSD |
2. あなたの"魔法の杖"を選択:4つのモデルバリアント
i2Lはワンサイズ fits all ではなく、異なるシーンに最適化された4つのモデルを提供しており、創作目標に基づいて選択する必要があります:
| 模型变体 | 参数规模 | 核心用途 | 适合场景 |
|---|---|---|---|
| スタイルモード | 2.4B | 純粋な美学スタイルに特化 | 水彩の筆触、油絵の質感、特定のフィルタートーンを学習 |
| 粗粒度モード | 7.9B | 内容とスタイルを捉え、シーン再構築 | ストリートシーンをサイバーパンクに、風景を童話の世界に |
| 精細モード | 7.6B | 1024x1024高解像度の詳細を生成 | 動物の毛、建物のレンガ、織物のテクスチャなどを強調する必要がある場合 |
| バイアスモード | 30M | 出力がQwen-Imageのネイティブスタイルと一致することを確保 | 企業の統一されたプロモーション画像の視覚スタイル、ブランドの"逸脱"防止 |
初心者向けアドバイス:スタイルモードまたは粗粒度モードから試してみてください。これらはほとんどの一般的なニーズに対応できます。
3. 核心步骤:单图训练你的LoRA
以下は簡略化された操作手順です、具体的なコードはプロジェクトの公式GitHubリポジトリを参照してください。
第一步:获取模型
すべてのモデルはオープンソースで提供されており、Hugging FaceまたはModelScopeプラットフォームで「Qwen-Image-i2L」を検索して無料でダウンロードできます。
第二步:准备你的风格图像
- お目当てのスタイルを明確に表現できる画像を選択します。
- 画像の品質が高く、重要な要素がはっきりしていることを確認します。
- (オプション)特定の主体(例えば特定の猫)を学習したい場合、主体が際立つ画像を使用してください。
第三步:运行训练脚本
トレーニングプロセスは通常、1つのコマンドで完了します。入力画像のパス、出力LoRAの保存場所、および上記の対応するモデルタイプを指定する必要があります。
# 例のコマンド(参考まで、公式ドキュメントを参照してください)
python train_i2l.py \
--input_image "あなたの画像.webp" \
--model_type "style" \ # ここで"スタイルモード"を選択
--output_lora "./my_style_lora.safetensors"
第四步:使用生成的LoRA进行创作
トレーニングが完了すると、.safetensorsファイルが得られます。Stable Diffusion WebUI(Automatic1111など)またはComfyUIで:
- LoRAファイルを対応するモデルフォルダーに配置します。
- 画像を生成する際に、特定の構文(例:
<lora:my_style_lora:1>)を使用してそのLoRAを呼び出します。 - 内容の説明を入力するだけで、カスタムスタイルを融合した新しい画像を生成できます。

4. 調整とプロンプトテクニック
- プロンプトが鍵:Qwenシリーズモデルは強力なテキスト理解とレンダリング能力で知られています。最終的な画像を生成する際には、明確なコンテンツプロンプトとLoRAを組み合わせることで、より良い効果が得られます。例:「
<lora:van Gogh_starry_night:0.8>、 現代的な摩天楼、夜空、渦巻き状の星、油絵のタッチ。」 - LoRA強度の制御:通常、呼び出し構文で重みを調整できます(例:
:1を:0.7に変更)。重みが低いほど、スタイルの影響は弱まり、コンテンツとの融合がより自然になります。 - ネガティブプロンプトの使用:「blurry, deformed, ugly」など、望ましくない要素を除外して画面品質を向上させます。
5. 公式推奨推論コード
DiffSynth-Studioのインストール:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
Qwen-Image-i2L-Style
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
# モデルの読み込み
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Style.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
# 画像の読み込み
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/style/1/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/style/1/0.webp"),
Image.open("data/examples/assets/style/1/1.webp"),
Image.open("data/examples/assets/style/1/2.webp"),
Image.open("data/examples/assets/style/1/3.webp"),
Image.open("data/examples/assets/style/1/4.webp"),
]
# モデル推論
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
save_file(lora, "model_style.safetensors")
Qwen-Image-i2L-Coarse、Qwen-Image-i2L-Fine、Qwen-Image-i2L-Bias
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from diffsynth.utils.lora import merge_lora
from diffsynth import load_state_dict
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
モデルの読み込み
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Coarse.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Fine.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
画像の読み込み
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/lora/3/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/lora/3/0.webp"),
Image.open("data/examples/assets/lora/3/1.webp"),
Image.open("data/examples/assets/lora/3/2.webp"),
Image.open("data/examples/assets/lora/3/3.webp"),
Image.open("data/examples/assets/lora/3/4.webp"),
Image.open("data/examples/assets/lora/3/5.webp"),
]
モデル推論
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
lora_bias = ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Bias.safetensors")
lora_bias.download_if_necessary()
lora_bias = load_state_dict(lora_bias.path, torch_dtype=torch.bfloat16, device="cuda")
lora = merge_lora([lora, lora_bias])
save_file(lora, "model_coarse_fine_bias.safetensors")
#### 生成された LoRA を使用して画像を生成
```py
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
vram_config = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": torch.bfloat16,
"onload_device": "cpu",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors", **vram_config),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
pipe.load_lora(pipe.dit, "model_style.safetensors")
image = pipe("a cat", seed=0, height=1024, width=1024, num_inference_steps=50)
image.save("image.webp")
6. 公式の例
スタイル
Qwen-Image-i2L-Style モデルは、スタイルが統一された数枚の画像を入力するだけで、迅速にスタイル LoRA を生成できます。以下に生成した結果を示します。乱数シードはすべて 0 です。
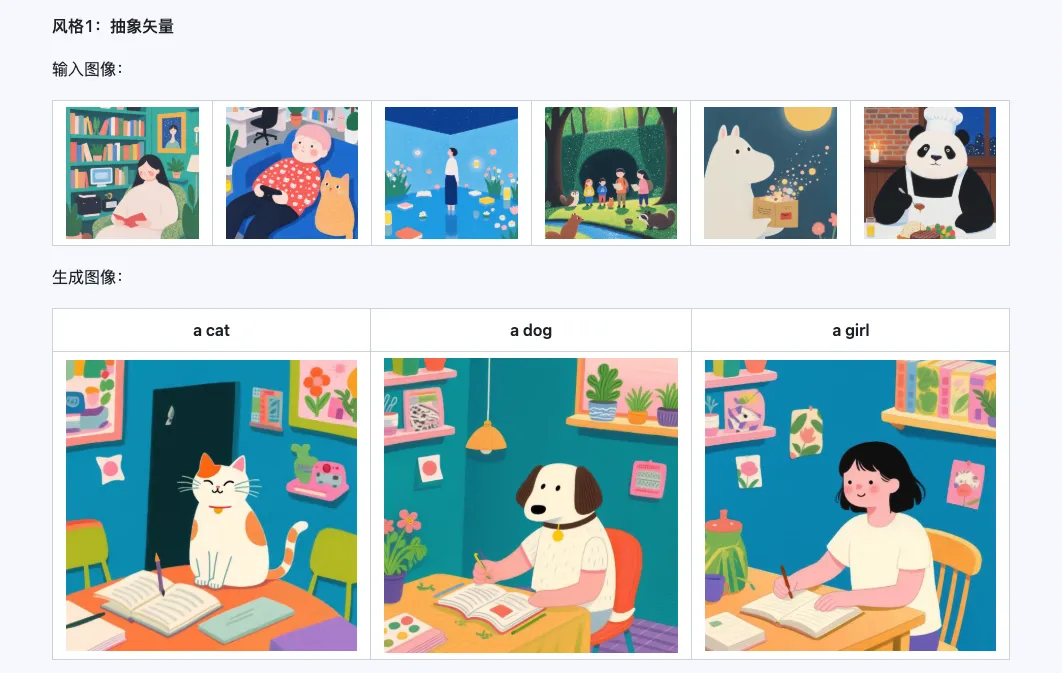
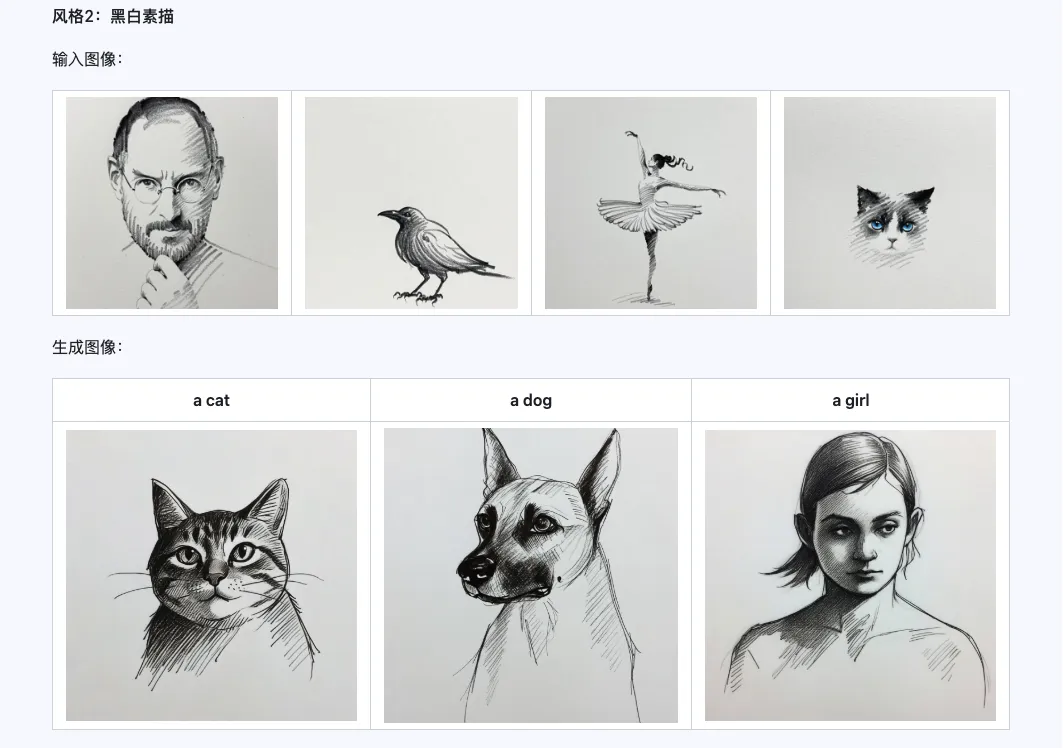
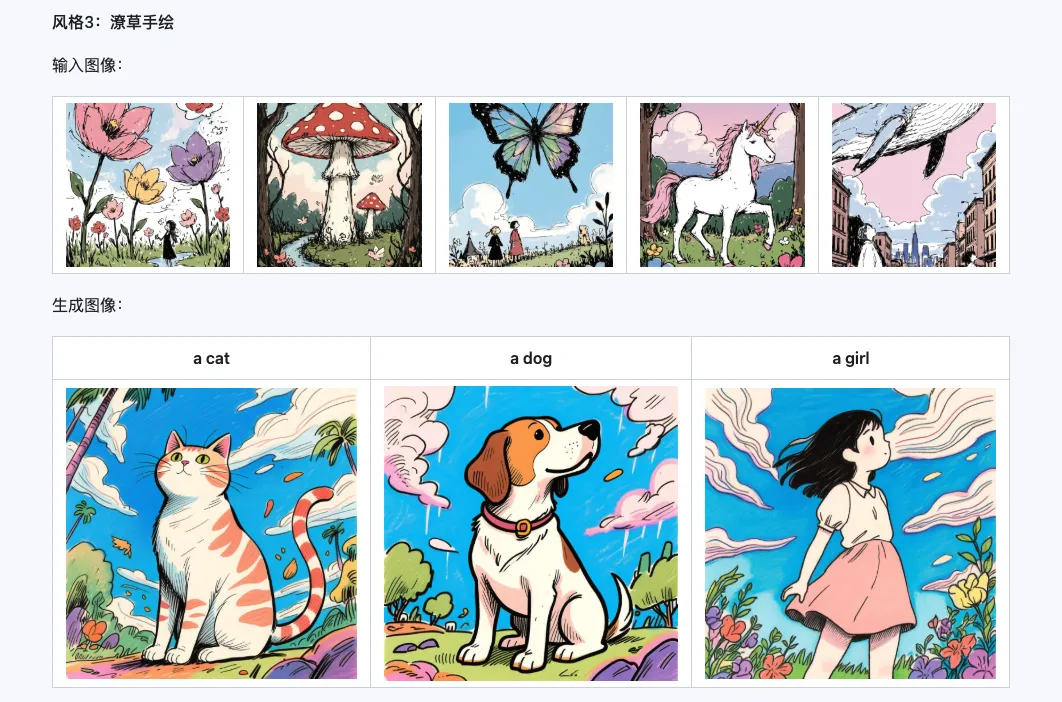
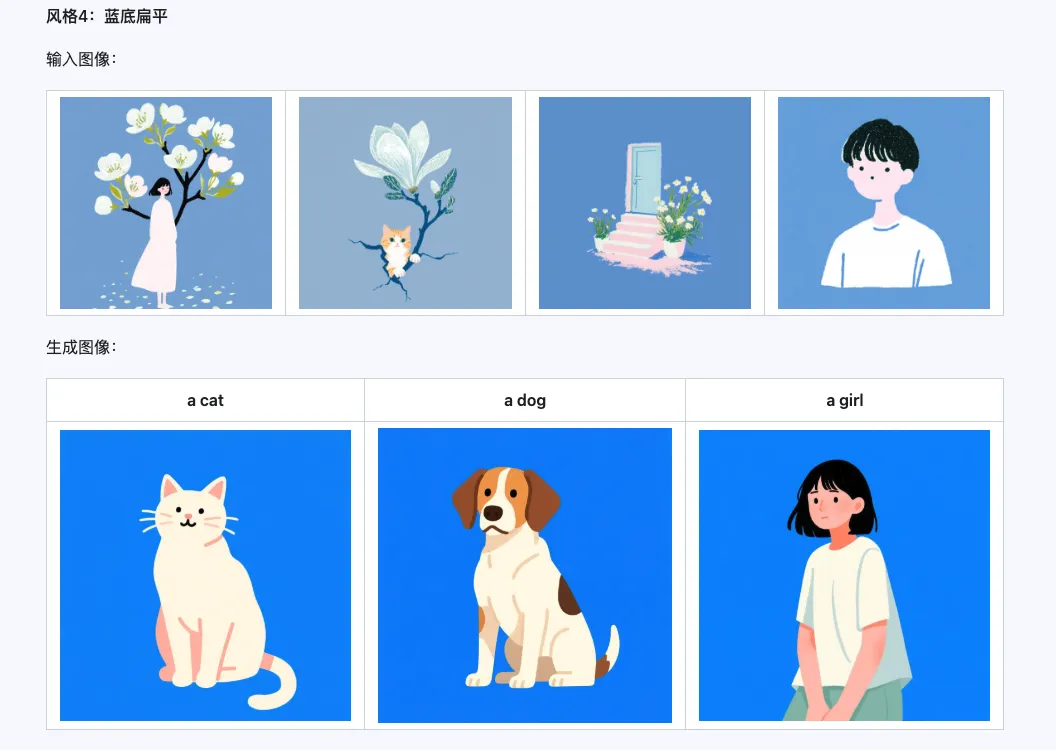
Coarse + Fine + Bias
Qwen-Image-i2L-Coarse、Qwen-Image-i2L-Fine、Qwen-Image-i2L-Bias の3つを組み合わせることで、画像の内容と詳細情報を保持する LoRA 重みを生成できます。この重みセットは LoRA 訓練の初期化重みとして使用でき、収束速度を向上させることができます。
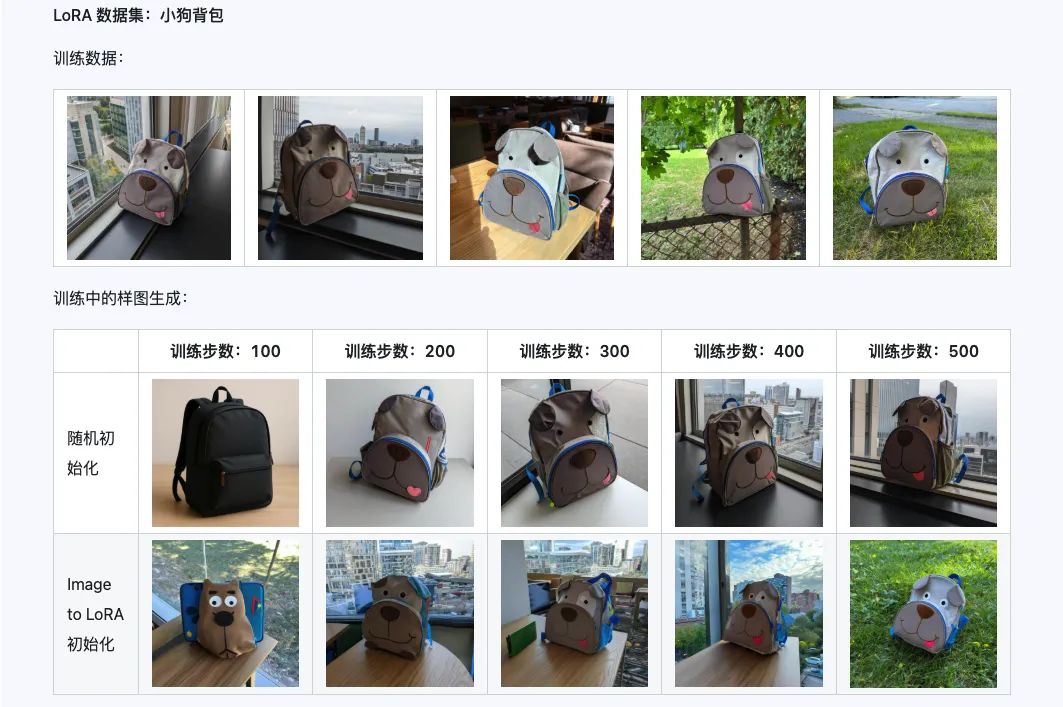
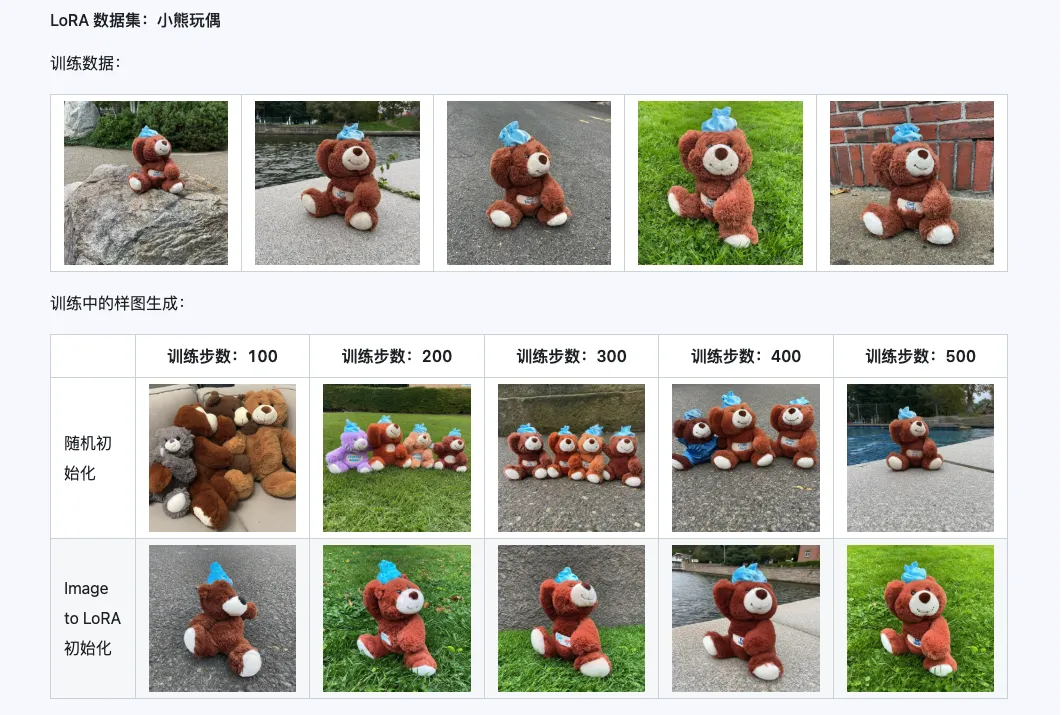

三、応用シナリオ:あなたのクリエイティブ・アクセラレーター
- 個人のアート創作:さまざまな巨匠の画風を素早く試したり、作品集に統一されたスタイルを確立したりできます。
- 電子商取引とマーケティング:異なる製品ラインに合わせて、統一されたスタイルで内容の異なるプロモーション画像を迅速に生成し、撮影とデザインのコストを大幅に削減できます。
- ゲームと映画のコンセプト:1枚の原画のスタイルを複数のシーンやキャクターデザインに素早く適用し、効率的にコンセプトアートを生産できます。
- ブランドビジュアル管理:「バイアスモード」を使用して、すべてのAI生成のマーケティング素材がブランドVI規格を厳格に遵守することを保証します。
四、注意事項と未来
- 現在の制限:単一の2D画像から3Dロジックを導出することには課題があります。例えば、「ソファにいる猫」の画像を訓練すると、生成された画像の他の角度で物体が浮いたり変形したりすることがあります。複雑な3Dスタイルの場合、複数の角度からの画像を準備するのが依然としてより良い選択です。
- 将来の発展:i2LはAI画像生成が**「インスタントカスタマイズ」時代**に入ったことを示しています。今後、「ワンクリックで漫画の分镜を生成」、「ワンクリックでキャラクターをデザイン」などのアプリケーションがより多く登場し、パーソナライズされたAI創作がより普及すると予想されます。
今すぐ、あなたの心の中の美学を最も表現する画像を見つけて、あなた専用のAIアーティストを作り始めましょう!
この記事の操作ガイドは、Qwen-Image-i2Lのオープンソース技術ドキュメントおよびコミュニティの実践に基づいています。モデルの具体的な使用方法は更新される可能性があるため、最新情報を入手するためにz-image.me、Hugging FaceまたはModelScopeのプロジェクトページも参照することをお勧めします。