
Qwen-Image-i2L: Create Your Personal AI Artist from a Single Image - Complete Guide to Personalized Image Generation
Qwen-Image-i2L: Create Your Personal AI Artist from a Single Image - Complete Guide to Personalized Image Generation
Have you ever wished AI could learn your favorite illustration style, but struggled with the need for dozens of samples and expensive computing power? Now, one image is all you need. Alibaba's Tongyi Lab's open-source Qwen-Image-i2L is exactly such a revolutionary tool that lets you customize your own AI artist like "building with LEGO blocks" using just a single image.
This article will guide you from scratch to quickly master this "style magic wand."
I. Introduction to i2L: What Is It and Why Is It Powerful?
Qwen-Image-i2L is a personalized style transfer tool. Its core is "Image to LoRA", meaning it decomposes and "compresses" the key style features of an input image into a lightweight LoRA (Low-Rank Adaptation) adapter module.
Core Principle: The Art of Simplifying Style Decomposition
Traditional AI learning of new styles requires massive data and long training times. i2L's innovation lies in its image decomposition mechanism: like unpacking a mystery box, it intelligently decomposes an image into learnable "components" such as "color tone," "texture brushwork," and "composition elements." These components are packaged into a LoRA file of only a few GB, which can then be loaded like a plugin into mainstream text-to-image models like Stable Diffusion to generate countless new works in the same style.

Simply put, its workflow can be summarized in three steps:
flowchart TD
A[Input<br>Single Style Image] --> B(Core: Image Decomposition & Feature Extraction)
B --> C{Select Model Variant<br>Based on Needs}
C -- Style Mode --> D1[Extract Pure Aesthetic Features<br>like brushstrokes, tones]
C -- Coarse Mode --> D2[Extract Content + Style<br>for scene reconstruction]
C -- Fine Mode --> D3[Extract High-Resolution Details<br>for texture enhancement]
D1 & D2 & D3 --> E(Generate Lightweight<br>LoRA Adapter File)
E --> F[Output<br>AI Artist capable of infinite same-style generation]
Deep Dive into Principles
The model's core is the image-to-LoRA conversion pipeline: input images are first transformed into embedding vectors through encoders (such as SigLIP2 for semantic extraction, DINOv3 for visual pattern capture, and Qwen-VL for high-resolution detail processing), then these vectors are directly mapped to LoRA matrices (low-rank matrices A and B). LoRA is essentially a "patch" for the base model (like Qwen-Image), updating only a small number of parameters (typically <1%) for efficient injection.
The four variant designs target different needs:
- Style (2.4B): Focuses on style extraction with weak detail preservation but strong style capture. Encoders: SigLIP2 + DINOv3.
- Coarse (7.9B): Extends Style, initially captures content but details aren't perfect. Adds Qwen-VL encoder (224x224 resolution).
- Fine (7.6B): Incremental upgrade of Coarse, increases to 1024x1024 resolution, focuses on details. Must be used with Coarse.
- Bias (30M): Static LoRA that corrects style deviation between generated images and Qwen-Image base model (like color preferences).
Below is a general LoRA architecture diagram, with Qwen-Image-i2L adding an image input layer on this foundation:
![]()
Limitations include insufficient generalization (single images struggle to capture 3D logic) and detail loss (complex textures may require multiple input images). Research shows using Bias can improve compatibility by 20-30% (based on example comparisons).
Why Should You Care? Four Core Advantages
- Extremely Low Barrier: Say goodbye to traditional workflows requiring 20+ images and GPU clusters - one image and a regular computer are enough.
- Extremely High Efficiency: From preparation to generating a usable style model, time is reduced from hours to just minutes.
- Excellent Quality: Generated LoRAs can precisely capture the essence of the original image and seamlessly integrate into mainstream AI painting workflows.
- Flexible Applications: Whether applying the style of "Starry Night" to modern architecture or transferring anime style to real photos, you can quickly experiment.
II. Practical Guide: Using i2L from Scratch
1. Environment Setup
Similar to using the basic Qwen-Image model, you need a Python environment. Since i2L is developed based on the powerful Qwen-Image (20 billion parameter MMDiT architecture), it has certain hardware requirements.
Here are recommended configuration references:
| Hardware | Minimum Requirements | Recommended Configuration |
|---|---|---|
| GPU | NVIDIA GTX 1080 Ti (8GB) | NVIDIA RTX 4090 D or higher |
| RAM | 16GB | 32GB or more |
| Storage | 50GB available space | 100GB SSD |
2. Choose Your "Magic Wand": Four Model Variants
i2L is not one-size-fits-all; it provides four models optimized for different scenarios. You need to choose based on your creative goals:
| Model Variant | Parameter Scale | Core Purpose | Suitable Scenarios |
|---|---|---|---|
| Style Mode | 2.4B | Specializes in pure aesthetic style transfer | Learning watercolor brushwork, oil painting texture, specific filter tones |
| Coarse Mode | 7.9B | Captures content and style for scene reconstruction | Turning street scenes into cyberpunk, landscapes into fairy tales |
| Fine Mode | 7.6B | Generates 1024x1024 high-resolution details | When highlighting animal fur, building bricks, fabric textures, etc. |
| Bias Mode | 30M | Ensures output is consistent with Qwen-Image native style | Corporate unified promotional image visual style, preventing brand "drift" |
Beginner Suggestion: Start with Style Mode or Coarse Mode - they can handle most common needs.
3. Core Steps: Training Your LoRA from a Single Image
Below is a simplified operation flow. For specific code, please refer to the official GitHub repository.
Step 1: Obtain the Model
All models are open-source. You can search for "Qwen-Image-i2L" on Hugging Face or ModelScope platforms and download for free.
- https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-i2L
- https://huggingface.co/DiffSynth-Studio/Qwen-Image-i2L
Step 2: Prepare Your Style Image
- Choose an image that clearly represents the style you need.
- Ensure the image quality is high with clear key elements.
- (Optional) If you want to learn a specific subject (like a particular cat), use an image where the subject is prominent.
Step 3: Run Training Script
Training usually requires just one command. You need to specify the input image path, output LoRA save location, and select the corresponding model type from the table above.
# Example command (for reference only, please follow official documentation)
python train_i2l.py \
--input_image "your_image.webp" \
--model_type "style" \ # Select "Style Mode" here
--output_lora "./my_style_lora.safetensors"
Step 4: Use Generated LoRA for Creation
After training, you'll get a .safetensors file. In Stable Diffusion WebUI (like Automatic1111) or ComfyUI:
- Place the LoRA file in the corresponding model folder.
- When generating images, call the LoRA through specific syntax in the prompt (like
<lora:my_style_lora:1>). - Enter your content description to generate new images that blend your custom style.

4. Parameter Tuning and Prompt Tips
- Prompts are Key: The Qwen series models are known for their powerful text understanding and rendering capabilities. When generating final images, combining clear content prompts with LoRA yields better results. For example: "
<lora:van_gogh_starry_night:0.8>, a modern skyscraper, night sky, swirling starlight, oil painting brushstrokes." - Control LoRA Strength: You can usually adjust the weight in the calling syntax (like changing
:1to:0.7). Lower weights mean weaker style influence and more natural fusion with content. - Use Negative Prompts: Exclude unwanted elements, like "blurry, deformed, ugly" to improve image quality.
5. Official Recommended Inference Code
Install DiffSynth-Studio:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
Qwen-Image-i2L-Style
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
# Load models
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Style.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
# Load images
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/style/1/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/style/1/0.webp"),
Image.open("data/examples/assets/style/1/1.webp"),
Image.open("data/examples/assets/style/1/2.webp"),
Image.open("data/examples/assets/style/1/3.webp"),
Image.open("data/examples/assets/style/1/4.webp"),
]
# Model inference
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
save_file(lora, "model_style.safetensors")
Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine, Qwen-Image-i2L-Bias
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from diffsynth.utils.lora import merge_lora
from diffsynth import load_state_dict
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
# Load models
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Coarse.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Fine.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
# Load images
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/lora/3/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/lora/3/0.webp"),
Image.open("data/examples/assets/lora/3/1.webp"),
Image.open("data/examples/assets/lora/3/2.webp"),
Image.open("data/examples/assets/lora/3/3.webp"),
Image.open("data/examples/assets/lora/3/4.webp"),
Image.open("data/examples/assets/lora/3/5.webp"),
]
# Model inference
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
lora_bias = ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Bias.safetensors")
lora_bias.download_if_necessary()
lora_bias = load_state_dict(lora_bias.path, torch_dtype=torch.bfloat16, device="cuda")
lora = merge_lora([lora, lora_bias])
save_file(lora, "model_coarse_fine_bias.safetensors")
Using Generated LoRA to Generate Images
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
vram_config = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": torch.bfloat16,
"onload_device": "cpu",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors", **vram_config),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
pipe.load_lora(pipe.dit, "model_style.safetensors")
image = pipe("a cat", seed=0, height=1024, width=1024, num_inference_steps=50)
image.save("image.webp")
6. Official Examples
Style
The Qwen-Image-i2L-Style model can be used to quickly generate style LoRAs by simply inputting a few images with unified style. Below are our generated results, all with random seed 0.
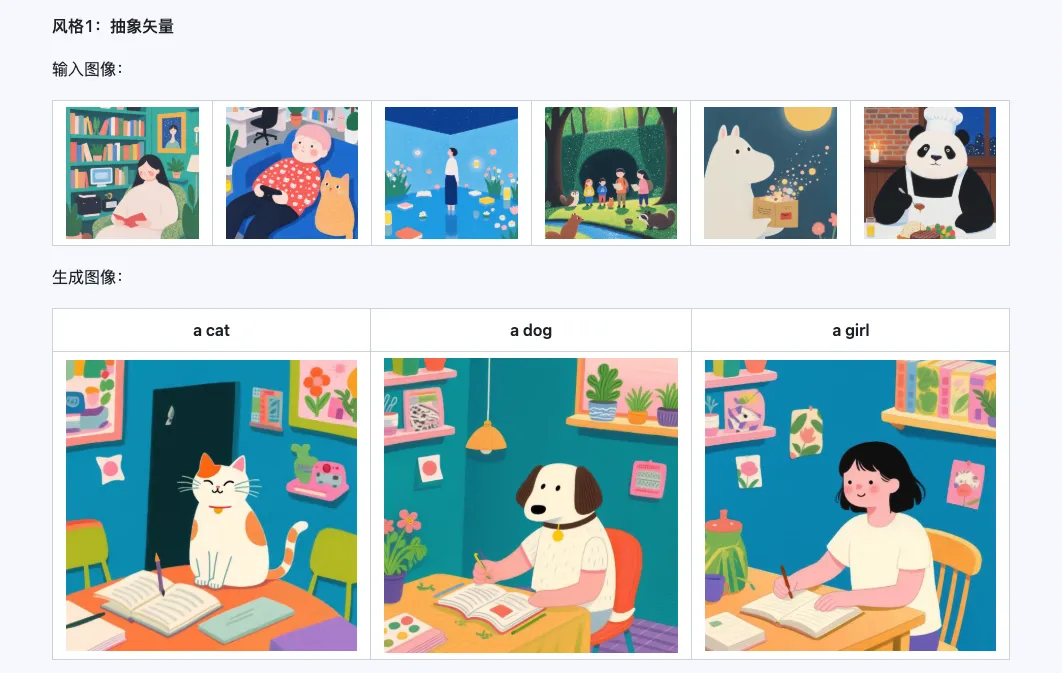
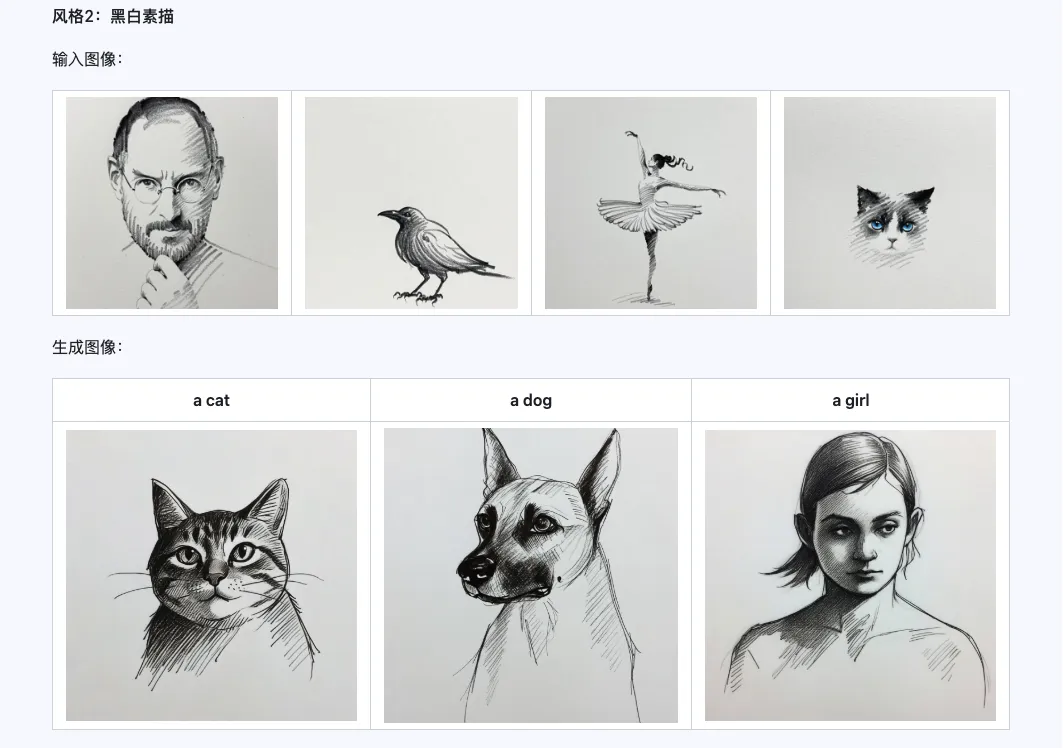
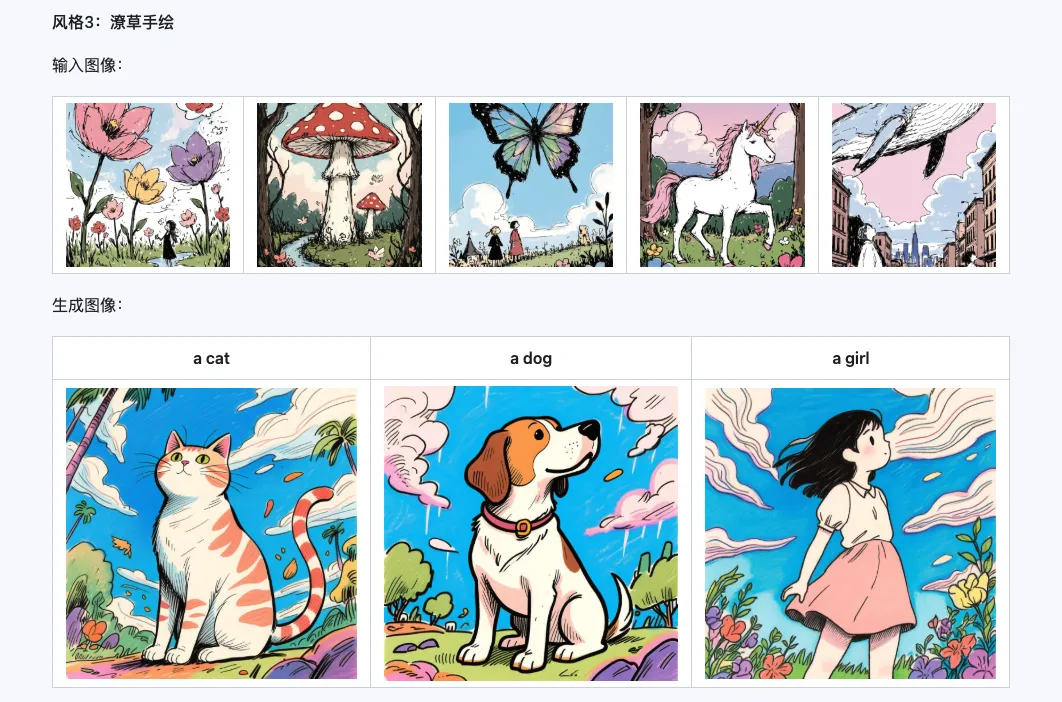
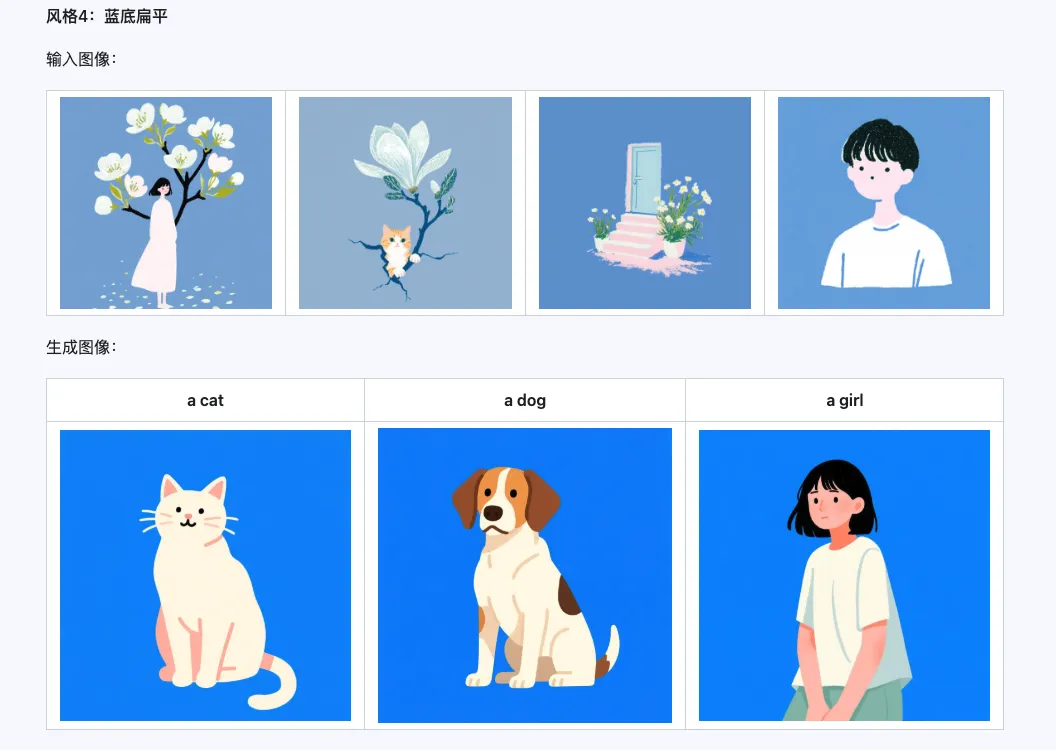
Coarse + Fine + Bias
The combination of Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine, and Qwen-Image-i2L-Bias can generate LoRA weights that preserve image content and detail information. These weights can serve as initialization weights for LoRA training to accelerate convergence.
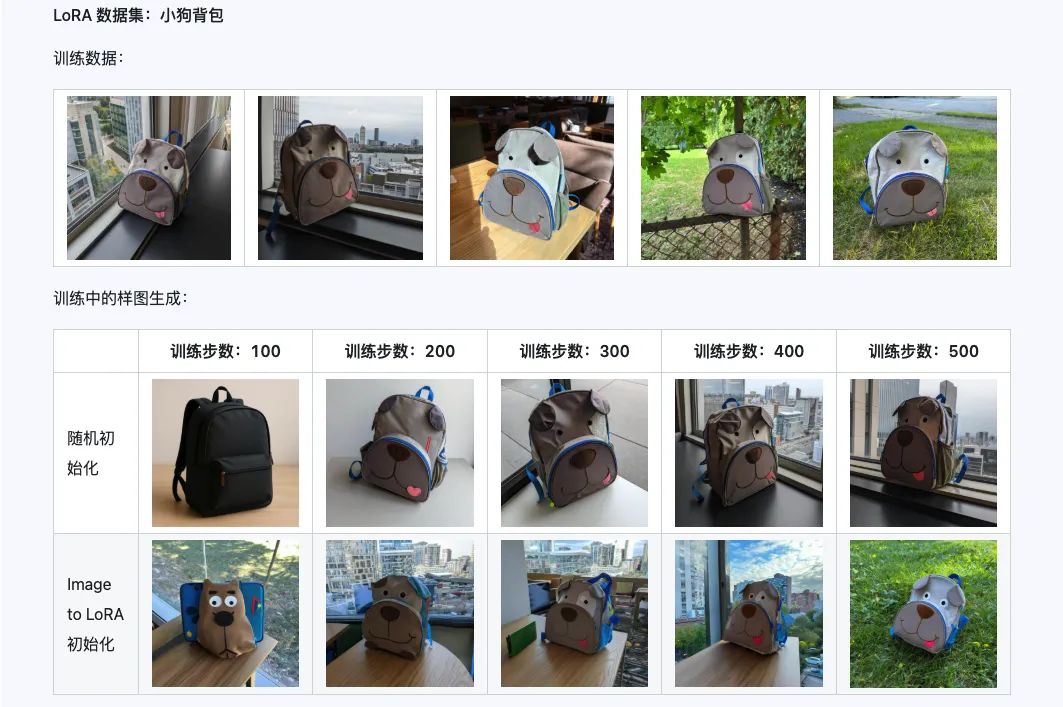
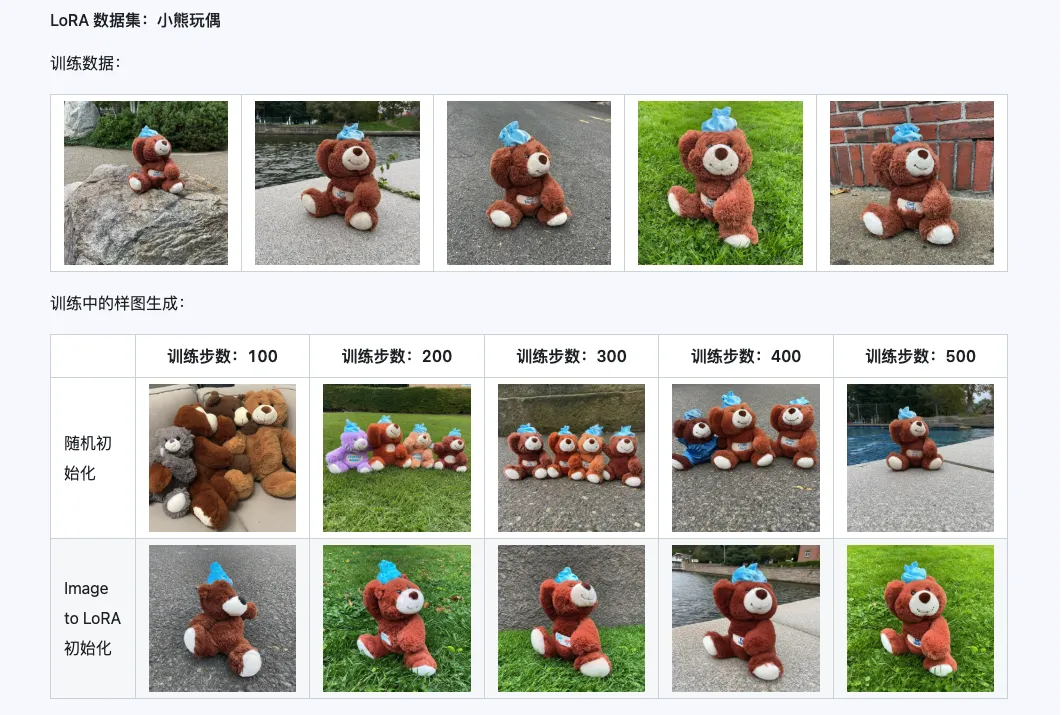

III. Application Scenarios: Your Creative Accelerator
- Personal Artistic Creation: Quickly experiment with various master painting styles or establish a unified style for your portfolio.
- E-commerce & Marketing: Quickly generate promotional images with unified style but different content for different product lines, significantly reducing shooting and design costs.
- Game & Film Concepts: Quickly transfer one original art style to multiple scenes and character designs, efficiently producing concept art.
- Brand Visual Management: Use "Bias Mode" to ensure all AI-generated marketing materials strictly comply with brand VI specifications.
IV. Considerations and Future Outlook
- Current Limitations: Deriving 3D logic from a single 2D image presents challenges. For example, training on an image of "a cat on a sofa" may result in generated images showing objects floating or deformed from other angles. For complex three-dimensional styles, preparing multi-angle images is still a better choice.
- Future Development: i2L marks AI image generation entering the "instant customization" era. It's foreseeable that more applications like "one-click comic storyboard generation" and "one-click character design" will emerge, making personalized AI creation more widespread.
Now, find an image that best represents your aesthetic vision and start creating your personal AI artist!
This operational guide is based on Qwen-Image-i2L open-source technical documentation and community practices. Specific model usage methods may be updated. It's recommended to also check z-image.me, Hugging Face, or ModelScope project pages for the latest information.