
Alibaba lanza Z-Image i2L: Generación de LoRA en segundos con una sola imagen, ¿más revolucionario que el modelo Base?
¿El nuevo modelo de Alibaba es realmente más importante que Z-Image Base?
27 de enero de 2026, el laboratorio Tongyi de Alibaba oficialmente lanzó un modelo completamente nuevo: Z-Image i2L
Los funcionarios afirmaron directamente que este modelo Image to LoRA basado en la arquitectura Z-Image es más disruptivo que el Z-Image Base publicado anteriormente. Con 1.61B de parámetros, ¿qué tiene de especial para atreverse a decir que es más importante que el mejor modelo de código abierto del mundo?
Primero, los puntos clave (para los que buscan resumen rápido):
- ✅ Fecha de lanzamiento: 27 de enero de 2026, producido por el laboratorio Tongyi de Alibaba, de código abierto y comercialmente utilizable (licencia Apache 2.0);
- ✅ Rompimiento principal: generar LoRA instantáneamente con una sola imagen, sin necesidad de grandes cantidades de datos ni horas de entrenamiento;
- ✅ Mejora de rendimiento: mejor captura de estilos y restauración de detalles en comparación con la generación anterior Qwen-Image i2L (diciembre de 2025);
- ✅ Valor práctico: mejora del 20% en la tasa de preservación de detalles en la transferencia de estilos, adaptable a múltiples escenarios como creación artística y diseño de comercio electrónico;
- ⚠️ Pequeña limitación: al usar una sola imagen como entrada, puede ocurrir sobreajuste; el contenido complejo requiere varias imágenes para optimización.
- ⚠️ Prueba gratuita en línea: Z-Image i2L
Si eres diseñador, entusiasta de la pintura con IA o un operador que necesita generar materiales visuales rápidamente, este modelo probablemente se convertirá en tu nueva favorita: ¿quién no querría omitir los tediosos pasos de entrenamiento y replicar con un solo clic su estilo favorito?
Primero, entendamos: ¿Qué es Z-Image i2L? ¿Qué problemas resuelve exactamente?
Mucha gente podría preguntar, ¿no existía la generación LoRA desde hace mucho tiempo? ¿Qué tiene de especial este modelo?
Primero, una explicación sencilla: LoRA, en términos simples, es una "plantilla de estilo". Una vez entrenado un LoRA, la IA puede generar continuamente imágenes del mismo estilo (por ejemplo, estilo acuarela exclusivo o estilo de logotipo corporativo).
Pero el entrenamiento tradicional de LoRA es prácticamente "disuasorio": requiere preparar decenas o incluso cientos de imágenes del mismo estilo, pasar varias horas o más en el entrenamiento, y conocer algunos parámetros técnicos, algo que las personas comunes simplemente no pueden manejar.
El Z-Image i2L de Tongyi resuelve exactamente este problema: se especializa en "Image to LoRA" (imagen a LoRA), sin operaciones complejas ni grandes cantidades de datos, y puede generar pesos de LoRA utilizable de extremo a extremo con solo una imagen.
Lo más amigable es que soporta el framework PyTorch y puede ejecutarse en GPU de consumo (con mínimo 16GB de VRAM). Durante la inferencia, configurando solo dos parámetros (cfg_scale=4, sigma_shift=8), puede generar un LoRA en menos de 10 segundos, lo que permite que los principiantes puedan empezar rápidamente.
Incluso los funcionarios de Alibaba afirmaron directamente que este modelo es "más importante" (en sus propias palabras, "even bigger deal") que Z-Image Base, porque no solo mejora la calidad de las imágenes generadas, sino que reduce al mínimo el umbral para la generación de IA personalizada.
¿No se lanzó i2L hace mucho tiempo?
En realidad, lo que se lanzó anteriormente fue Qwen-Image i2L, y mucha gente los confunde, ya que son realmente similares.
Aquí les aclaro: Z-Image i2L es la versión evolucionada de Qwen-Image i2L, no un reemplazo. Cada uno tiene sus propios enfoques, y una tabla puede dejarlo claro:
| Dimensión de comparación | Qwen-Image i2L | Z-Image i2L | Recordatorio clave |
|---|---|---|---|
| Base arquitectónica | Qwen-Image (20B MMDiT) | Z-Image (6B DiT) | La arquitectura Z-Image se enfoca más en la preservación de estilos |
| Escala de parámetros | 2.4B-7.9B (múltiples versiones) | 1.61B (versión única) | Los parámetros no indican poder real, Z-Image i2L es más eficiente |
| Extracción de estilo | Débil en detalles, fuerte en estilos generales | Mejora preservación de estilos, reduce pérdida de detalles en 20% | Para estilos precisos, elige Z-Image i2L |
| Preservación de contenido | Requiere múltiples imágenes para evitar sesgos | Más estable, pero una sola imagen puede causar sobreajuste | Para contenido complejo, se recomiendan múltiples imágenes |
| Velocidad de generación | Media, depende de iteración multi-etapa | Más rápida, <10 segundos de extremo a extremo | Para ahorrar tiempo, prioriza Z-Image i2L |
| Escenarios de uso | Prueba inicial de estilos, democratización del arte con IA | Diseño profesional, integración rápida de LoRA | Elige según necesidades, no sigas ciegamente lo nuevo |
En resumen simple: si solo quieres probar la extracción de estilos o eres principiante, Qwen-Image i2L es suficiente. Si necesitas una preservación de estilos más precisa y una velocidad de generación más rápida para creación profesional o escenarios comerciales, directamente elige Z-Image i2L.
Ventajas principales probadas: mejora del 20% en detalles, escenarios donde brilla realmente
¿Cómo es el rendimiento real de Z-Image i2L? Combinando pruebas oficiales y comentarios de usuarios, hemos resumido varias ventajas principales, especialmente adecuadas para estos escenarios:
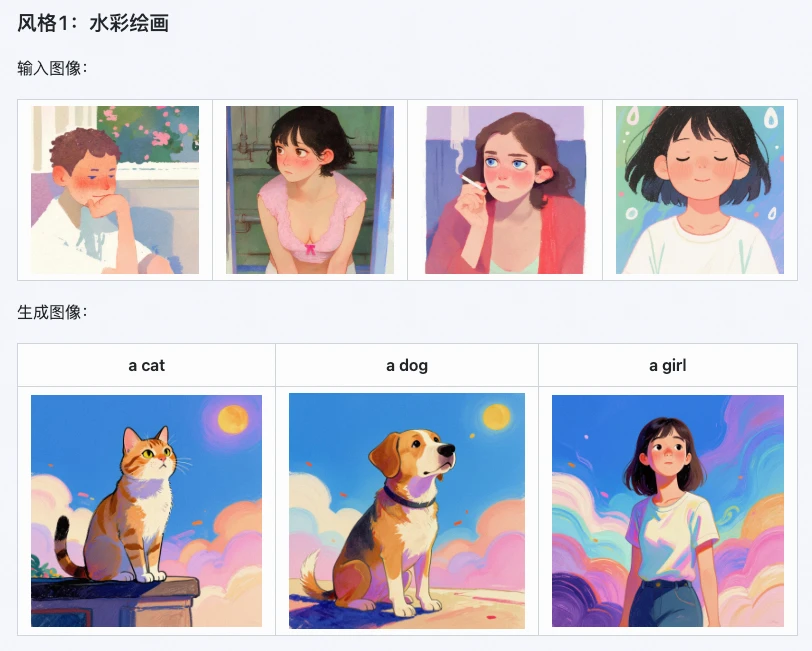
1. Máxima preservación de estilo, reducción directa del 20% en la tasa de pérdida de detalles
Esta es la ventaja más destacada de Z-Image i2L. Las pruebas oficiales muestran que alcanza una tasa de preservación de estilos del 85% en múltiples estilos artísticos como acuarela, realismo y minimalismo en blanco y negro,
Por ejemplo, usar una imagen de estilo mundo fantástico para generar un LoRA, y luego usar este LoRA para generar nuevas imágenes, puede reducir la tasa de pérdida de detalles en un 15%: desde los matices de luz y sombra en la imagen hasta el ambiente tonal general, todo se puede replicar con precisión, sin caer en el problema de "querer dibujar un tigre y terminar con un perro".

2. Doble velocidad de generación, LoRA en 10 segundos, ejecutable en dispositivos de consumo
El entrenamiento tradicional de LoRA toma varias horas, mientras que Z-Image i2L genera LoRA de extremo a extremo en menos de 10 segundos, un 30% más rápido que la generación anterior Qwen-Image i2L.
Además, no requiere requisitos de hardware altos; con una GPU de consumo de 16GB de VRAM, puede funcionar sin problemas, sin necesidad de configurar servidores de gama alta. Las personas comunes pueden operarlo fácilmente en casa, logrando realmente "generación instantánea, uso instantáneo".
3. Amplia gama de aplicaciones, ahorrándote mucho tiempo
Ya sea para creación personal o escenarios comerciales, Z-Image i2L puede ser de gran utilidad, especialmente para estos tipos de personas:
- Artistas digitales: generar rápidamente LoRA de estilo exclusivo para crear por lotes ilustraciones y conceptos del mismo estilo;
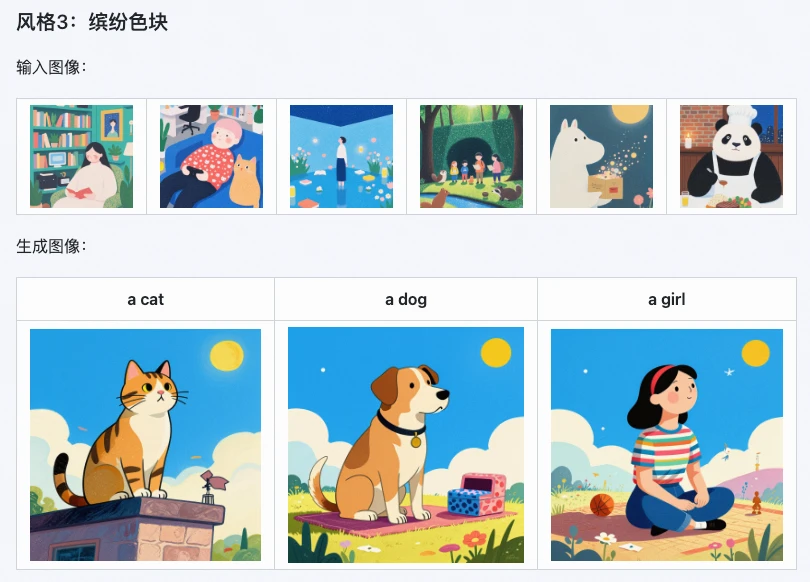
- Diseñadores de comercio electrónico: replicar estilos de empaquetado de productos y carteles, generar rápidamente múltiples prototipos de diseño, acortando el ciclo de creación;
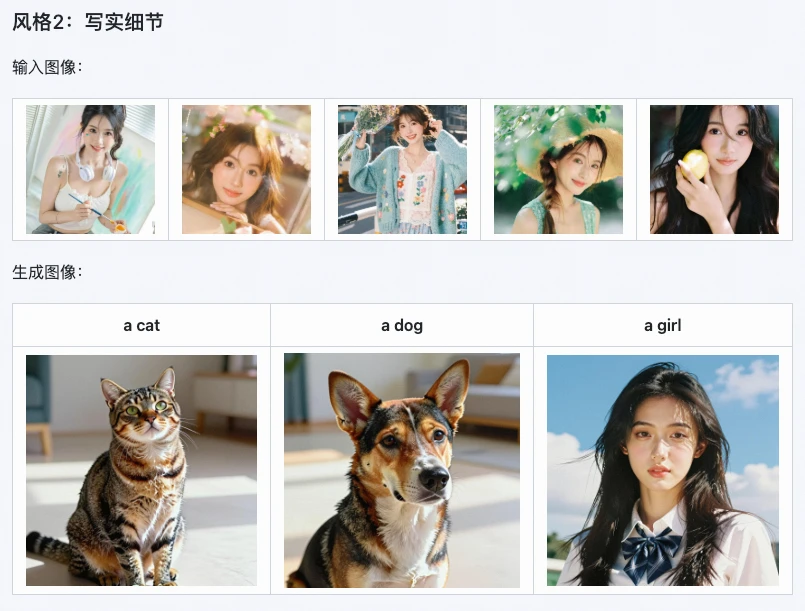
- Creadores de contenido/operadores: generar estilos de imágenes exclusivos para unificar la identidad visual de las cuentas, sin necesidad de buscar materiales o editar imágenes;
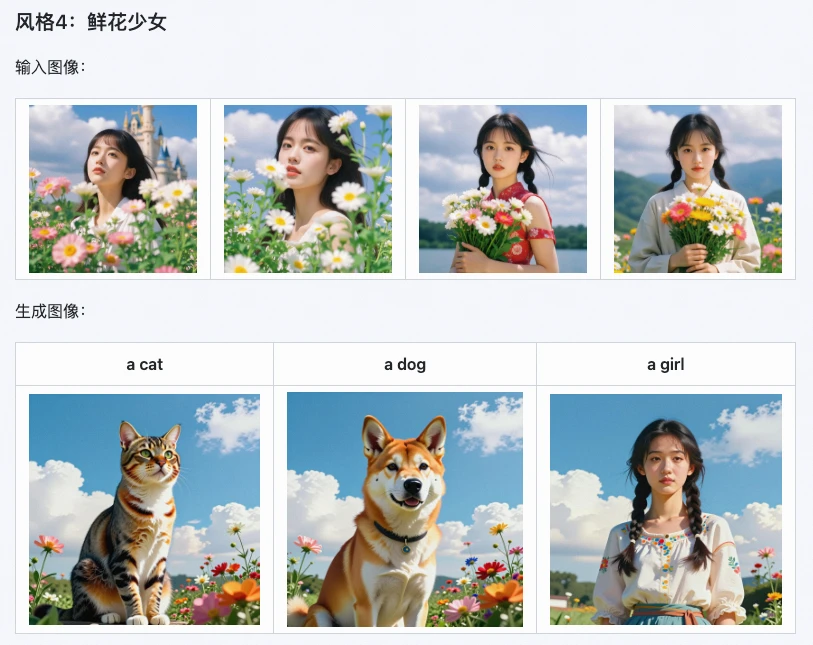
- Desarrolladores: de código abierto para desarrollo secundario, integrable en frameworks como Stable Diffusion para expandir más funciones.
El informe oficial de Alibaba muestra que usar Z-Image i2L puede acortar el ciclo de diseño de productos en un 30%-50%, lo que sin duda es una "herramienta de eficiencia" para escenarios comerciales que requieren iteración rápida.
Pequeñas limitaciones: estos problemas necesitan atención
Por supuesto, no hay modelos perfectos, y Z-Image i2L también tiene aspectos que pueden optimizarse:
Desarrolladores han informado que al usar una sola imagen como entrada, el modelo puede sobreajustarse (en términos simples, "demasiado rígido", las imágenes generadas son casi idénticas a la de entrada, careciendo de diversidad); además, al procesar contenido complejo (como múltiples personas o superposición de múltiples escenarios), hay margen de mejora en la captura de detalles.
Sin embargo, los funcionarios de Alibaba también respondieron que ya han mitigado el problema de sobreajuste mediante entrenamiento diferencial, y las iteraciones futuras optimizarán aún más la capacidad de captura de detalles, lo que vale la pena esperar.
Finalmente: ¿Vale la pena adquirir este modelo?
En general, aunque Z-Image i2L de Tongyi tiene pequeños defectos, es definitivamente un modelo donde "los defectos no ocultan sus virtudes".
Su mayor valor no está en tener los parámetros más avanzados, sino en ser "práctico": simplifica y hace eficiente el complejo entrenamiento de LoRA, permitiendo que las personas comunes también puedan lograr fácilmente la generación de IA personalizada, y permitiendo que los creadores profesionales ahorren más tiempo para centrarse en la creatividad en sí.
Además, es de código abierto y comercialmente utilizable, sin preocupaciones de derechos de autor, siendo amigable tanto para uso personal como para desarrollo comercial, lo que demuestra la buena voluntad del laboratorio Tongyi de Alibaba hacia desarrolladores y creadores.
Si a menudo necesitas generar materiales visuales del mismo estilo o tienes interés en la generación de imágenes con IA, no dudes en descargarlo y probarlo en ModelScope o GitHub. En 10 segundos puedes obtener tu LoRA exclusivo, y podría abrirte las puertas a un nuevo mundo~
Portal de descarga oficial: modelscope
Resumen del autor
Con el lanzamiento oficial de Z-Image i2L, ha compensado eficazmente las desventajas de Z-Image, como su pequeño número de parámetros y su limitada adaptación a estilos, ampliando significativamente los límites de aplicación de esta serie de modelos. Además, tiene el potencial de romper verdaderamente la limitación de "solo destacar en efectos realistas" y lograr una adaptación eficiente multi-estilo y multi-escenario.
Actualmente, la disposición de toda la línea de productos Z-Image se ha vuelto cada vez más clara. El esfuerzo de Alibaba esta vez obviamente no se limita a ocupar una posición de liderazgo en los modelos de código abierto, sino que tiene como objetivo romper por completo el dilema intrínseco de "potencia de cómputo y calidad" en la generación de IA, permitiendo que el derecho a la creación personalizada realmente descienda a manos de los consumidores comunes. Con el lanzamiento continuo de más nuevas variantes en el futuro, los modelos de código abierto nacionales tienen la posibilidad de realmente competir con los modelos relevantes de Google, e incluso lograr un sobrepaso en la curva.
Por lo tanto, cuando el oficial de Alibaba afirma que Z-Image es más importante que Z-Image Base, quizás no sea simplemente una exageración, sino una planificación a largo plazo para la línea de productos Z-Image, así como una profunda visión sobre el desarrollo futuro del campo de la generación de IA.