
Qwen-Image-i2L: 한 이미지로 전용 AI 아티스트 만들기, 개인화된 이미지 창작 완벽 가이드
Qwen-Image-i2L: 한 이미지로 전용 AI 아티스트 만들기, 개인화된 이미지 창작 가이드
당신이 AI가 가장 좋아하는 일러스트 스타일을 배우기를 원했지만 수십 장의 소재와 비싼 컴퓨팅 파워가 부족했던 적이 있나요? 이제 한 장의 이미지면 충분합니다. 알리툰이(阿里通义) 연구실이 오픈소스로 공개한 Qwen-Image-i2L은 바로 그런 혁신적인 도구로, "레고 조립"처럼 한 장의 이미지로만 자신만의 AI 아티스트를 커스터마이징할 수 있게 해줍니다.
본 글에서는 처음부터 시작하여 이 "스타일 마법 지팡이"의 사용법을 빠르게 익히는 방법을 안내해 드리겠습니다.
1. i2L 소개: 무엇이며 왜 강력한가?
Qwen-Image-i2L은 개인화된 스타일 이전 도구입니다. 그 핵심은 **"Image to LoRA"**로, 입력 이미지의 핵심 스타일 특징을 분해하고 "압축"하여 경량의 LoRA(Low-Rank Adaptation) 어댑터 모듈로 만드는 것을 의미합니다.
핵심 원리: 복잡함을 단순화하는 "스타일 분해술"
전통적인 AI가 새로운 스타일을 배우기에는 방대한 데이터와 장시간의 훈련이 필요합니다. i2L의 혁신성은 그 이미지 분해 메커니즘에 있습니다: "언박스링"하는 것처럼, 한 장의 이미지를 "색조 기반", "텍스처 붓 터치", "구도 요소" 등 학습 가능한 "부품"으로 지능적으로 분해합니다. 이 부품들은 몇 GB 크기의 LoRA 파일로 패키징되어, 이후 플러그인처럼 Stable Diffusion과 같은 주요 텍스트-이미지 생성 모델에 로드하여 수많은 동일 스타일의 새 작품을 생성할 수 있습니다.

간단히 말해, 그 작업 흐름은 다음 세 단계로 요약할 수 있습니다:
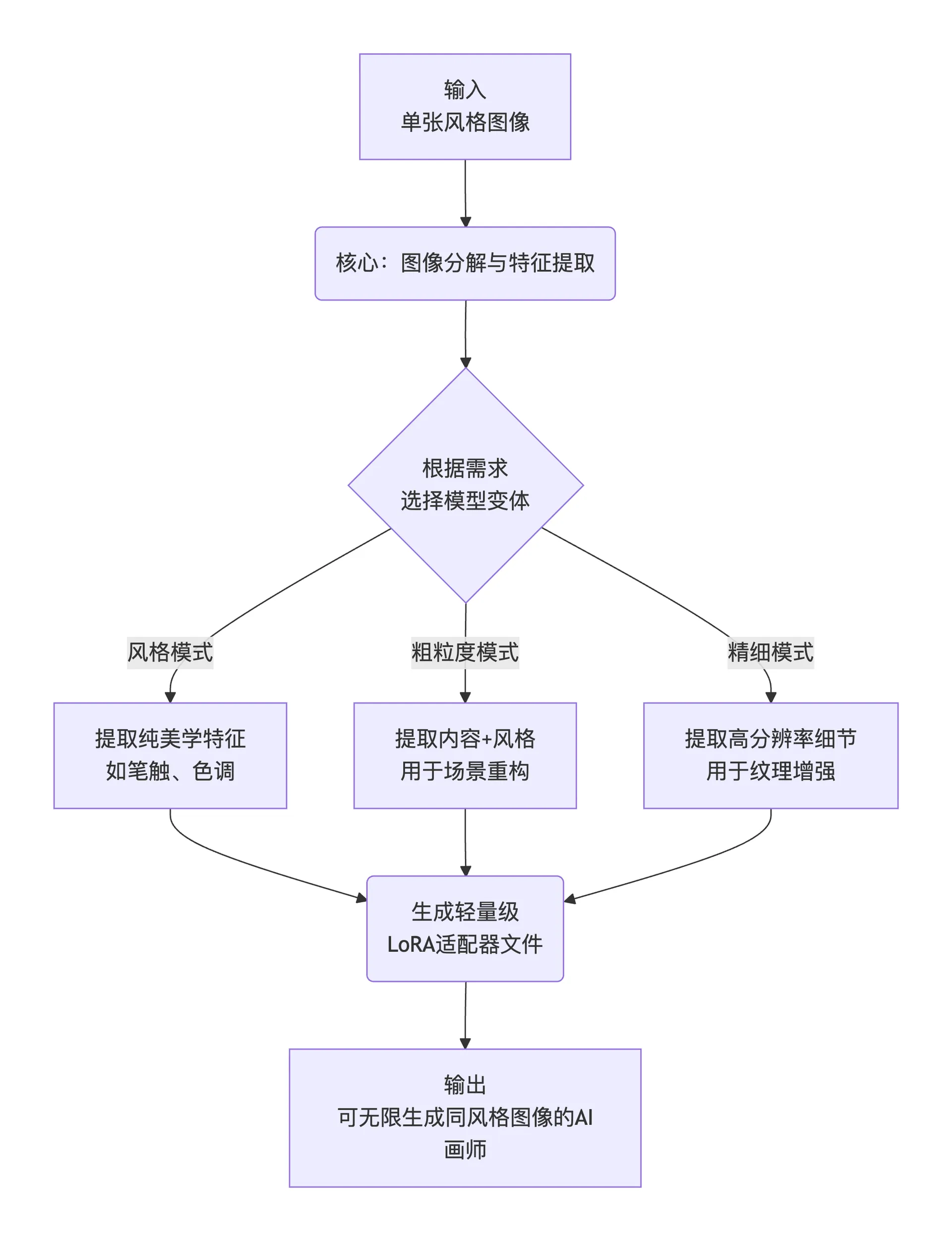
flowchart TD
A[입력<br>단일 스타일 이미지] --> B(핵심: 이미지 분해 및 특징 추출)
B --> C{요구사항에 따라<br>모델 변체 선택}
C -- 스타일 모드 --> D1[순수 미학 특징 추출<br>예: 붓 터치, 톤]
C -- 거친 모드 --> D2[콘텐츠+스타일 추출<br>장면 재구성용]
C -- 세밀 모드 --> D3[고해상도 세부사항 추출<br>텍스처 강화용]
D1 & D2 & D3 --> E(경량화된<br>LoRA 어댑터 파일 생성)
E --> F[출력<br>무한히 동일 스타일 이미지 생성 가능한 AI 아티스트]
심층 원리 분석
모델의 핵심은 이미지에서 LoRA로 변환하는 파이프라인입니다: 입력 이미지가 먼저 인코더(SigLIP2로 의미 추출, DINOv3로 시각적 패턴 캡처, Qwen-VL로 고해상도 세부 처리)를 통해 임베딩 벡터로 변환되고, 이 벡터들은 LoRA 행렬(저랭크 행렬 A와 B)로 직접 매핑됩니다. LoRA는 본질적으로 기본 모델(예: Qwen-Image)의 "패치"로, 소수의 매개변수(보통 <1%)만 업데이트하여 효율적인 주입을 구현합니다.
네 가지 변체는 다양한 요구사항을 대상으로 설계되었습니다:
- Style (2.4B): 스타일 추출에 전념, 세부 보존은 약하지만 스타일 캡처력이 강함. 인코더: SigLIP2 + DINOv3.
- Coarse (7.9B): Style 확장, 내용을 초기 캡처하지만 세부사항이 완벽하지 않음. 인코더에 Qwen-VL (224x224 해상도) 추가.
- Fine (7.6B): Coarse의 증분 업그레이드, 1024x1024 해상도로 업그레이드, 세부사항에 집중. 반드시 Coarse와 함께 사용해야 함.
- Bias (30M): 정적 LoRA, 생성 이미지와 Qwen-Image 기본 모델의 스타일 편향(예: 색상 선호도)을 수정합니다.
다음은 일반 LoRA 아키텍처 다이어그램이며, Qwen-Image-i2L은 이에 이미지 입력 레이어를 추가한 것입니다:
![]()
제한점으로는 일반화 부족(단일 이미지로 3D 논리 캡처 어려움)과 세부사항 손실(복잡한 텍스처는 다중 이미지 입력 필요)이 있습니다. 연구에 따르면 Bias 사용은 호환성을 20-30% 향상시킬 수 있습니다(예시 비교 기준).
왜 주목해야 할까? 네 가지 핵심 장점
- 진입장벽 매우 낮음: 20장 이상의 이미지와 GPU 클러스터가 필요한 전통적인 과정을 작별하고, 한 장의 이미지와 일반 컴퓨터로 충분합니다.
- 효율성 매우 높음: 준비부터 사용 가능한 스타일 모델 생성까지 소요 시간이 수 시간에서 몇 분으로 단축됩니다.
- 품질 뛰어남: 생성된 LoRA는 원본 이미지의 본질을 정확히 포착하며, 주요 AI 드로잉 워크플로우에 원활하게 통합됩니다.
- 용도 유연: 《별이 빛나는 밤》의 스타일을 현대 건축에 적용하든, 애니메이션 스타일을 실사 사진으로 이전하든 빠르게 시도해볼 수 있습니다.
2. 실전 가이드: 처음부터 i2L 사용하기
1. 환경 준비
기본 Qwen-Image 모델 사용과 유사하게 Python 환경이 필요합니다. i2L은 강력한 **Qwen-Image(200억 매개변수 MMDiT 아키텍처)**를 기반으로 개발되었으므로 하드웨어에 일정 요구사항이 있습니다.
다음은 권장 구성 참조입니다:
| 하드웨어 | 최소 요구사항 | 권장 구성 |
|---|---|---|
| GPU | NVIDIA GTX 1080 Ti (8GB) | NVIDIA RTX 4090 D 또는 더 높은 사양 |
| 메모리 | 16GB | 32GB 또는 그 이상 |
| 저장 공간 | 50GB 가용 공간 | 100GB SSD |
2. 당신의 "마법 지팡이" 선택: 네 가지 모델 변체
i2L은 만능이 아니며, 다양한 시나리오에 최적화된 네 가지 모델을 제공하므로 창작 목적에 따라 선택해야 합니다:
| 모델 변체 | 매개변수 규모 | 핵심 용도 | 적합한 시나리오 |
|---|---|---|---|
| 스타일 모드 | 2.4B | 순수 미학 스타일 이전에 전념 | 수채화 붓 터치, 유화 질감, 특정 필터 톤 학습 |
| 거친 모드 | 7.9B | 콘텐츠와 스타일 캡처, 장면 재구성 | 거리 풍경을 사이버펑크로, 풍경을 동화 세계로 변환 |
| 세밀 모드 | 7.6B | 1024x1024 고해상도 세부사항 생성 | 동물 털, 건축 블록,織物 텍스처 등 세부사항을 강조해야 할 때 |
| 편향 모드 | 30M | 출력이 Qwen-Image 원본 스타일과 일치하도록 보장 | 기업 통일 홍보 이미지 시각 스타일, 브랜드 "이탈" 방지 |
초보자 추천: 스타일 모드 또는 거친 모드로 시작하는 것을 권장하며, 이들은 대부분의 일반적인 요구사항을 처리할 수 있습니다.
3. 핵심 단계: 한 장의 이미지로 LoRA 훈련하기
다음은 단순화된 작업 절차이며, 구체적인 코드는 프로젝트 공식 GitHub 저장소를 참조하십시오.
첫 번째 단계: 모델 가져오기
모든 모델은 오픈소스로 공개되어 있으며, Hugging Face 또는 ModelScope 플랫폼에서 "Qwen-Image-i2L"을 검색하여 무료로 다운로드할 수 있습니다.
두 번째 단계: 스타일 이미지 준비
- 원하는 스타일을 명확하게 대표하는 이미지를 선택합니다.
- 이미지 품질이 높고, 주요 요소가 선명한지 확인합니다.
- (선택 사항) 특정 주제(예: 특정 고양이)를 학습하고 싶다면 주제가 돋보이는 이미지를 사용하십시오.
세 번째 단계: 훈련 스크립트 실행
훈련 과정은 보통 하나의 명령으로만 가능합니다. 입력 이미지 경로, 출력 LoRA의 저장 위치, 그리고 위 표에 해당하는 모델 유형을 지정해야 합니다.
# 예시 명령 (참고용이며, 공식 문서를 따르십시오)
python train_i2l.py \
--input_image "your_image.webp" \
--model_type "style" \ # 여기서 "스타일 모드" 선택
--output_lora "./my_style_lora.safetensors"
네 번째 단계: 생성된 LoRA로 창작하기
훈련이 완료되면 .safetensors 파일을 얻게 됩니다. Stable Diffusion WebUI(예: Automatic1111) 또는 ComfyUI에서:
- LoRA 파일을 해당 모델 폴더에 넣습니다.
- 이미지 생성 시 특정 구문(예:
<lora:my_style_lora:1>)을 통해 해당 LoRA를 호출합니다. - 콘텐츠 설명을 입력하면 사용자 정의 스타일이 통합된 새 이미지가 생성됩니다.

4. 파라미터 조정 및 프롬프트 기법
- 프롬프트가 핵심입니다: Qwen 시리즈 모델은 강력한 텍스트 이해 및 렌더링 능력으로 유명합니다. 최종 이미지를 생성할 때 명확한 콘텐츠 프롬프트와 LoRA를 결합하면 더 좋은 결과를 얻을 수 있습니다. 예: "
<lora:van Gogh_starry_night:0.8>현대적인 마천루, 밤하늘, 소용돌이치는 별빛, 유화 붓질." - LoRA 강도 제어: 일반적으로 호출 구문에서 가중치를 조정할 수 있습니다(예:
:1을:0.7로 변경). 가중치가 낮을수록 스타일 영향이 약해지고 콘텐츠와의 융합이 더 자연스럽습니다. - 네거티브 프롬프트 사용: 원하지 않는 요소를 제외합니다. 예: "blurry, deformed, ugly"를 사용하여 화면 품질을 향상시킵니다.
5. 공식 추론 코드
DiffSynth-Studio 설치:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
Qwen-Image-i2L-Style
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
# Load models
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Style.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
# Load images
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/style/1/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/style/1/0.webp"),
Image.open("data/examples/assets/style/1/1.webp"),
Image.open("data/examples/assets/style/1/2.webp"),
Image.open("data/examples/assets/style/1/3.webp"),
Image.open("data/examples/assets/style/1/4.webp"),
]
# Model inference
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
save_file(lora, "model_style.safetensors")
Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine, Qwen-Image-i2L-Bias
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from diffsynth.utils.lora import merge_lora
from diffsynth import load_state_dict
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
모델 로드
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Coarse.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Fine.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
이미지 로드
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/lora/3/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/lora/3/0.webp"),
Image.open("data/examples/assets/lora/3/1.webp"),
Image.open("data/examples/assets/lora/3/2.webp"),
Image.open("data/examples/assets/lora/3/3.webp"),
Image.open("data/examples/assets/lora/3/4.webp"),
Image.open("data/examples/assets/lora/3/5.webp"),
]
모델 추론
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
lora_bias = ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Bias.safetensors")
lora_bias.download_if_necessary()
lora_bias = load_state_dict(lora_bias.path, torch_dtype=torch.bfloat16, device="cuda")
lora = merge_lora([lora, lora_bias])
save_file(lora, "model_coarse_fine_bias.safetensors")
#### 생성된 LoRA로 이미지 생성
```py
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
vram_config = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": torch.bfloat16,
"onload_device": "cpu",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors", **vram_config),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
pipe.load_lora(pipe.dit, "model_style.safetensors")
image = pipe("a cat", seed=0, height=1024, width=1024, num_inference_steps=50)
image.save("image.webp")
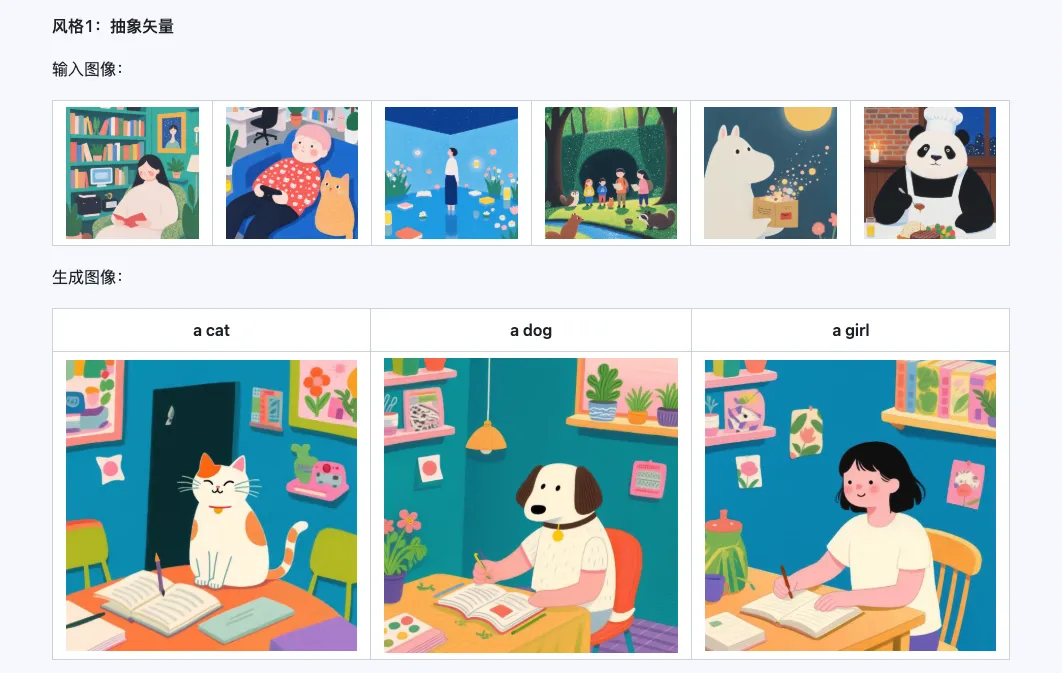
6. 공식 예제
스타일
Qwen-Image-i2L-Style 모델은 몇 장의 스타일이 통일된 이미지만 입력하면 빠르게 스타일 LoRA를 생성할 수 있습니다. 다음은 우리가 생성한 결과이며, 모두 랜덤 시드가 0입니다.
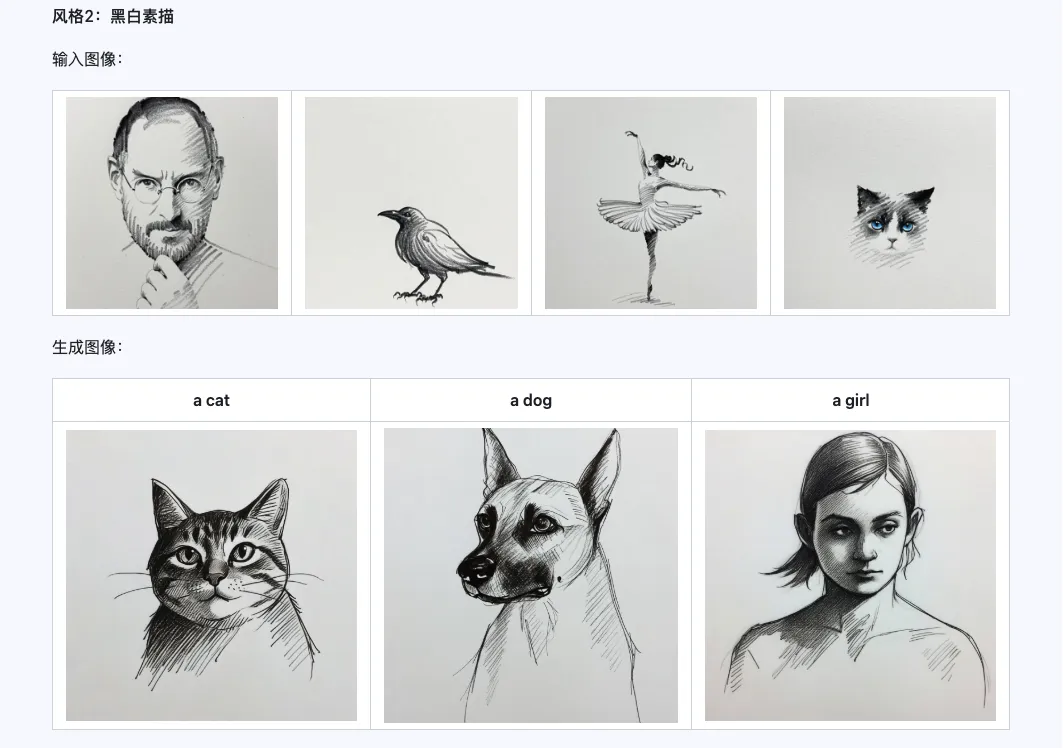
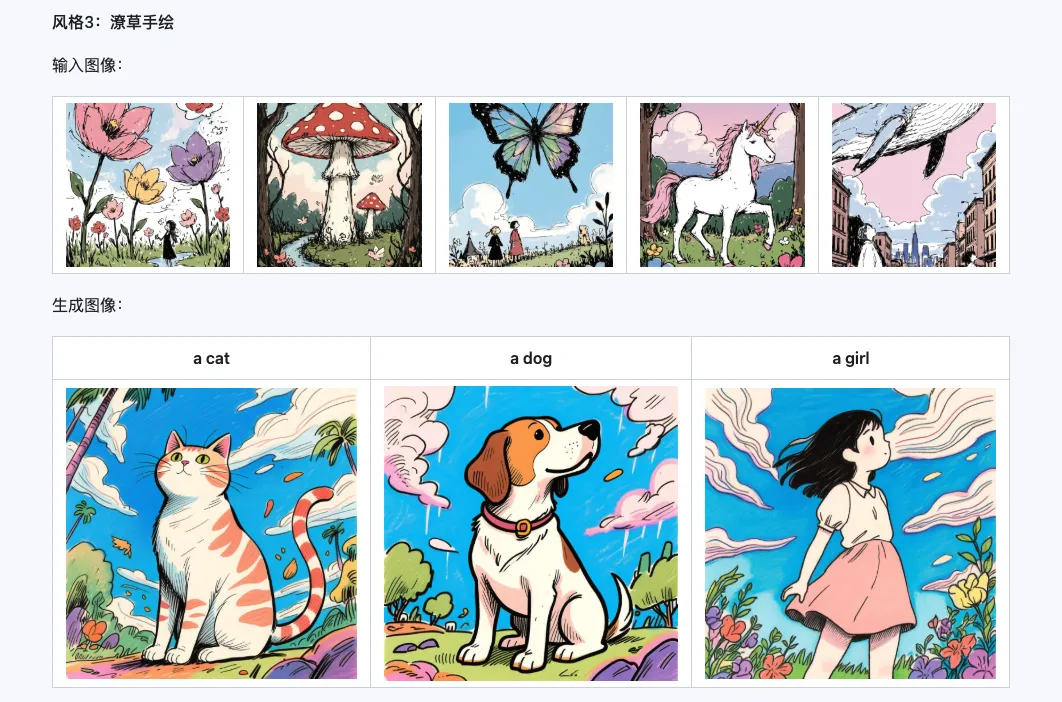
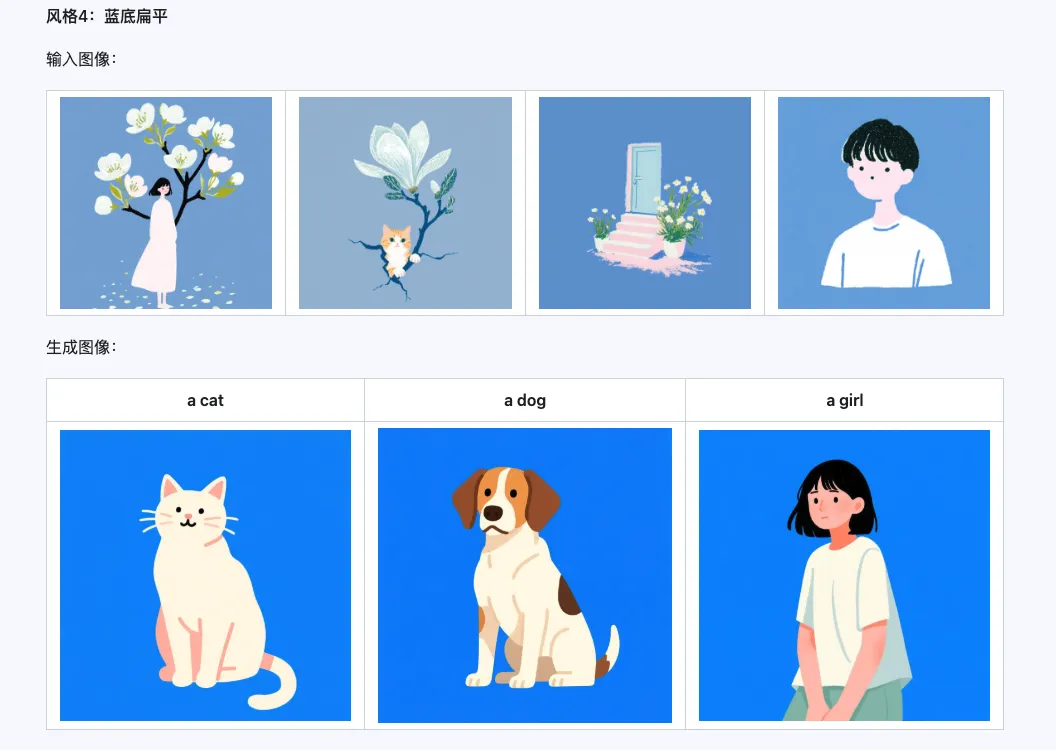
Coarse + Fine + Bias
Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine, Qwen-Image-i2L-Bias 세 가지를 조합하면 이미지 내용과 세부 정보를 보존하는 LoRA 가중치를 생성할 수 있으며, 이 가중치는 LoRA 훈련의 초기 가중치로 사용되어 수렴 속도를 높일 수 있습니다.
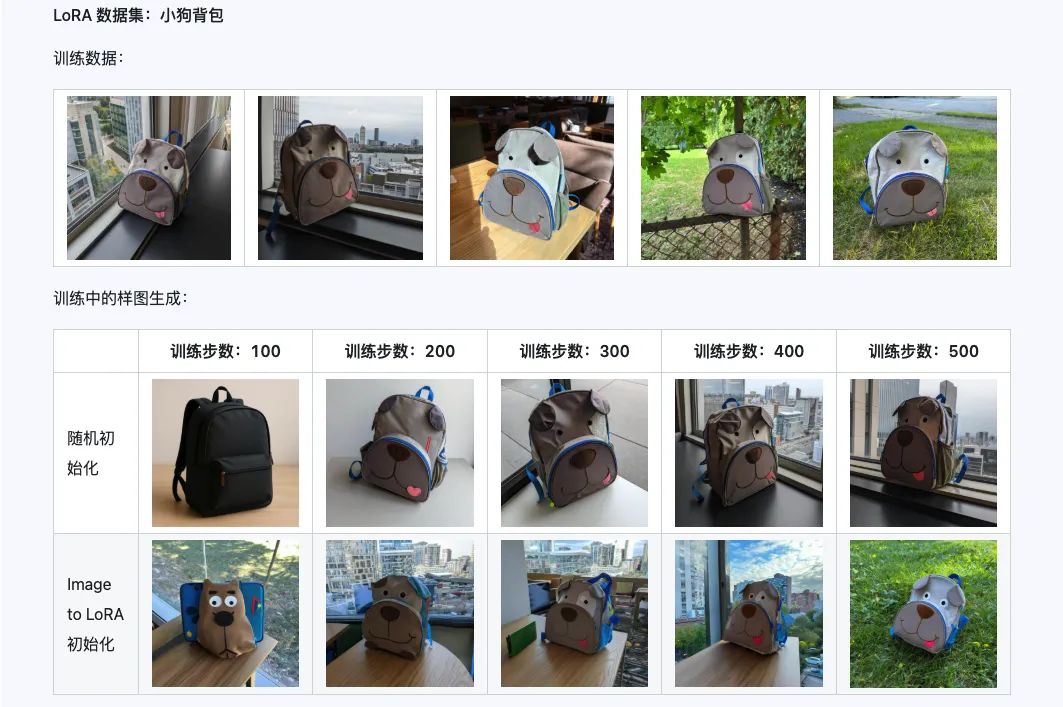
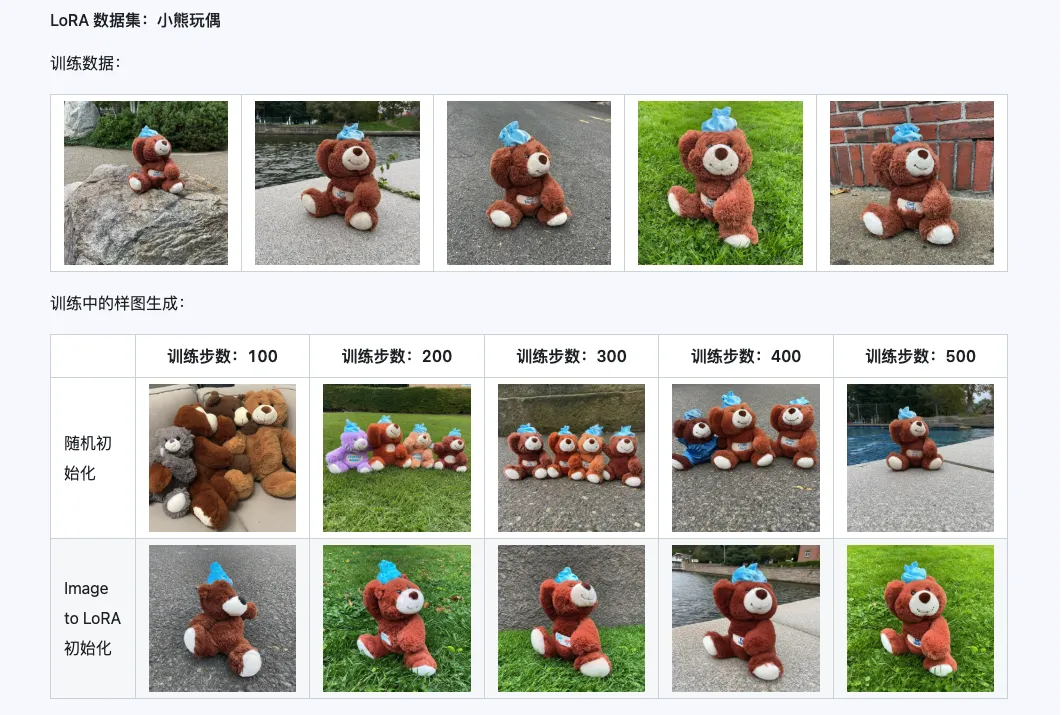

3. 애플리케이션 시나리오: 당신의 크리에이티브 가속기
- 개인 예술 창작: 다양한 대가들의 화풍을 빠르게 시도하거나, 자신의 포트폴리오를 위한 통일된 스타일을 구축합니다.
- 전자상거래 및 마케팅: 다양한 제품 라인을 위해 통일된 스타일과 다양한 콘텐츠의 홍보 이미지를 빠르게 생성하여 촬영 및 디자인 비용을 크게 절감합니다.
- 게임 및 영화 개념: 한 장의 원화 스타일을 여러 장면과 캐릭터 디자인으로 빠르게 이전하여 효율적으로 컨셉 아트를 생산합니다.
- 브랜드 시각 관리: "편향 모드"를 사용하여 모든 AI 생성 마케팅 자료가 브랜드 VI 규정을 엄격히 준수하도록 보장합니다.
4. 주의사항 및 미래
- 현재 한계: 단일 2D 이미지에서 3D 로직을 추론하는 데는 도전이 있습니다. 예를 들어, "소파에 있는 고양이" 이미지를 훈련시키면, 생성된 이미지에서 다른 각도에서 물체가 공중에 떠 있거나 변형될 수 있습니다. 복잡한 3D 스타일의 경우, 다양한 각도의 이미지를 준비하는 여전히 더 나은 선택입니다.
- 미래 발전: i2L은 AI 이미지 생성이 "즉시 맞춤화" 시대로 진입했음을 의미합니다. 앞으로 "원클릭 만화 분장 생성", "원클릭 캐릭터 디자인" 등 더 많은 애플리케이션이 등장하여 개인화된 AI 창작이 더욱 보편화될 것으로 예상됩니다.
이제, 당신의 미학을 가장 잘 대표하는 이미지를 찾아 당신만의 전용 AI 화가를 만들어보세요!
본 글의 작동 가이드는 Qwen-Image-i2L 오픈소스 기술 문서 및 커뮤니티 실천에 기반합니다. 모델의 구체적인 사용 방법은 업데이트될 수 있으므로, 최신 정보를 얻기 위해 z-image.me、Hugging Face 또는 ModelScope의 프로젝트 페이지를 함께 참고하시기 바랍니다.