
Qwen-Image-i2L: Crie seu assistente de IA personalizado com uma única imagem - Guia completo para criação de imagens personalizadas
Qwen-Image-i2L: Crie seu artista de IA personalizado com uma única imagem - Guia completo para criação de imagens personalizadas
Já desejou que a IA aprendesse o seu estilo de ilustração favorito, mas foi impedido por não ter dezenas de exemplos e poder computacional caro? Agora, uma única imagem é suficiente. O Qwen-Image-i2L, de código aberto do laboratório Tongyi da Alibaba, é uma ferramenta revolucionária que permite personalizar seu próprio artista de IA como se estivesse "montando um Lego", usando apenas uma única imagem.
Este guia irá levá-lo do início ao fim, ajudando-o a dominar rapidamente o uso desta "varinha mágica de estilo".
I. Primeiros passos com o i2L: O que é e por que é poderoso?
Qwen-Image-i2L é uma ferramenta de transferência de estilo personalizada. O seu núcleo é o "Image to LoRA", que significa decompor e "comprimir" os recursos de estilo-chave de uma imagem de entrada em um módulo de adaptador LoRA (Low-Rank Adaptation) leve.
Princípio fundamental: A "técnica de desmontagem de estilo" que simplifica o complexo
A IA tradicional precisa de grandes volumes de dados e treinamento prolongado para aprender novos estilos. A inovação do i2L está no seu mecanismo de decomposição de imagem: ele inteligentemente divide uma imagem em "peças" aprendíveis, como "tom de cor", "textura e traço", "elementos de composição", assim como desmontando uma caixa surpresa. Essas peças são encapsuladas em um arquivo LoRA de apenas alguns GB, que pode então ser carregado em modelos de geração de imagem a partir de texto populares como o Stable Diffusion, gerando inúmeras novas obras no mesmo estilo.

Em termos simples, seu fluxo de trabalho pode ser resumido em três passos:
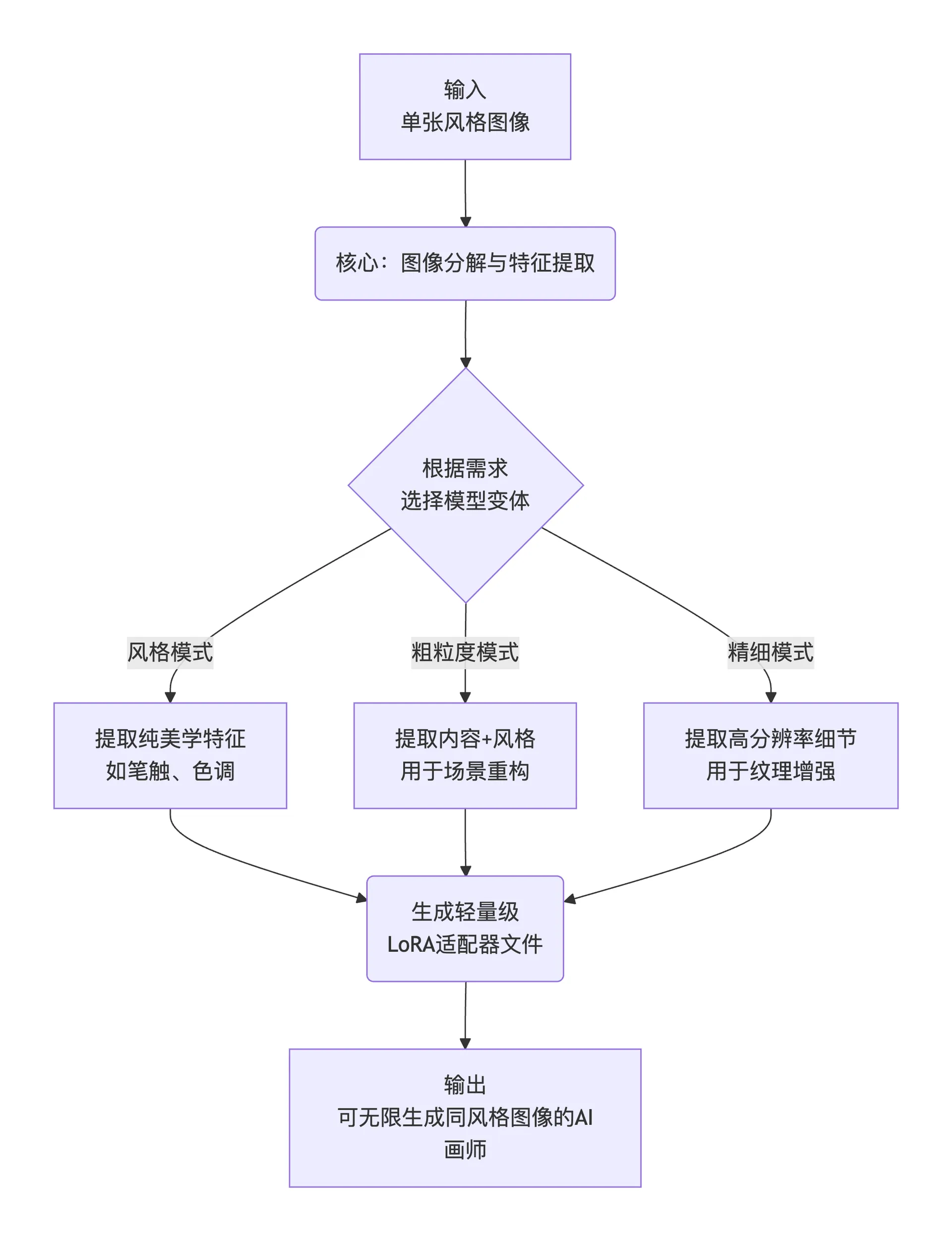
flowchart TD
A[输入<br>单张风格图像] --> B(核心:图像分解与特征提取)
B --> C{根据需求<br>选择模型变体}
C -- 风格模式 --> D1[提取纯美学特征<br>如笔触、色调]
C -- 粗粒度模式 --> D2[提取内容+风格<br>用于场景重构]
C -- 精细模式 --> D3[提取高分辨率细节<br>用于纹理增强]
D1 & D2 & D3 --> E(生成轻量级<br>LoRA适配器文件)
E --> F[输出<br>可无限生成同风格图像的AI画师]
Análise aprofundada dos princípios
O núcleo do modelo é o pipeline de conversão de imagem para LoRA: a imagem de entrada primeiro passa por codificadores (como SigLIP2 para semântica, DINOv3 para padrões visuais, Qwen-VL para detalhes de alta resolução) para se tornar vetores de incorporação, que são então mapeados diretamente para matrizes LoRA (matrizes de baixa ordem A e B). LoRA é essencialmente um "patch" para o modelo base (como Qwen-Image), atualizando apenas um pequeno número de parâmetros (geralmente <1%) para uma injeção eficiente.
As quatro variantes são projetadas para diferentes necessidades:
- Style (2.4B): Focado em extração de estilo, fraco na preservação de detalhes, mas forte na captura de estilo. Codificadores: SigLIP2 + DINOv3.
- Coarse (7.9B): Estende o Style, captura conteúdo preliminarmente, mas os detalhes são imperfeitos. Adiciona codificador Qwen-VL (resolução 224x224).
- Fine (7.6B): Atualização incremental do Coarse, atualizado para resolução 1024x1024, focando em detalhes. Deve ser usado com o Coarse.
- Bias (30M): LoRA estático, corrige o desvio de estilo entre as imagens geradas e o modelo base Qwen-Image (como preferências de cor).
A imagem abaixo é um diagrama de arquitetura LoRA geral, o Qwen-Image-i2L adiciona uma camada de entrada de imagem com base nisso:
![]()
As limitações incluem generalização insuficiente (uma única imagem tem dificuldade em capturar a lógica 3D) e perda de detalhes (texturas complexas podem exigir múltiplas imagens de entrada). Pesquisas mostram que o uso do Bias pode melhorar a compatibilidade em 20-30% (com base em comparações de exemplos).
Por que prestar atenção a ele? Quatro vantagens principais
- Limite extremamente baixo: Diga adeus ao processo tradicional que exige 20+ imagens e clusters de GPU, uma imagem mais um computador comum é suficiente.
- Extremamente eficiente: Da preparação à geração de um modelo de estilo utilizável, o tempo é reduzido de várias horas para alguns minutos.
- Qualidade excelente: O LoRA gerado pode capturar com precisão a essência da imagem original e integrar-se perfeitamente aos fluxos de trabalho de pintura de IA populares.
- Uso flexível: Seja aplicando o estilo de "Noite Estrelada" em edifícios modernos ou transferindo estilo anime para fotos reais, você pode experimentar rapidamente.
II. Guia prático: Começando do zero com o i2L
1. Preparação do ambiente
Semelhante ao uso do modelo básico Qwen-Image, você precisa de um ambiente Python. Como o i2L é desenvolvido com base na poderosa arquitetura Qwen-Image (20 bilhões de parâmetros MMDiT), ele tem certos requisitos de hardware.
Aqui estão referências de configuração recomendadas:
| Hardware | Requisito mínimo | Configuração recomendada |
|---|---|---|
| GPU | NVIDIA GTX 1080 Ti (8GB) | NVIDIA RTX 4090 D ou superior |
| Memória | 16GB | 32GB ou mais |
| Armazenamento | 50GB de espaço disponível | 100GB SSD |
2. Escolha sua "varinha mágica": Quatro variantes de modelo
O i2L não é único para todos, oferece quatro modelos otimizados para diferentes cenários, e você precisa escolher com base em seus objetivos criativos:
| Variante do modelo | Tamanho de parâmetro | Propósito principal | Cenários adequados |
|---|---|---|---|
| Modo Style | 2.4B | Focado puramente em transferência de estilo estético | Aprendendo traços de aquarela, textura de pintura a óleo, tons de filtro específicos |
| Modo Coarse | 7.9B | Capturar conteúdo e estilo, para reconstrução de cena | Transformar cenas urbanas em cyberpunk, paisagens em mundos de conto de fadas |
| Modo Fine | 7.6B | Gerar detalhes de alta resolução 1024x1024 | Quando é necessário destacar pelos de animais, tijolos de edifícios, texturas de tecido, etc. |
| Modo Bias | 30M | Garantir que a saída corresponda ao estilo nativo do Qwen-Image | Estilo visual unificado de promocional empresarial, impedir o "desvio" da marca |
Sugestão para iniciantes: Comece com o Modo Style ou Modo Coarse, eles podem lidar com a maioria das necessidades comuns.
3. Passos principais: Treinando seu LoRA com uma única imagem
Aqui está um fluxo de trabalho simplificado, para código específico, consulte o repositório oficial do GitHub do projeto.
Passo 1: Obter os modelos
Todos os modelos são de código aberto, você pode pesquisar "Qwen-Image-i2L" nas plataformas Hugging Face ou ModelScope e baixar gratuitamente.
Passo 2: Preparar sua imagem de estilo
- Escolha uma imagem que represente claramente o estilo que você deseja.
- Certifique-se de que a imagem seja de alta qualidade, com elementos-chave claros.
- (Opcional) Se você quiser aprender um sujeito específico (como um gato específico), tente usar uma imagem com sujeito proeminente.
Passo 3: Executar o script de treinamento
O processo de treinamento geralmente requer apenas um comando. Você precisa especificar o caminho da imagem de entrada, local de salvamento do LoRA de saída e escolher o tipo de modelo correspondente da tabela acima.
# Exemplo de comando (apenas para referência, consulte a documentação oficial)
python train_i2l.py \
--input_image "sua_imagem.webp" \
--model_type "style" \ # Aqui escolha "Modo Style"
--output_lora "./meu_style_lora.safetensors"
Passo 4: Usar o LoRA gerado para criação
Após o treinamento ser concluído, você obterá um arquivo .safetensors. No Stable Diffusion WebUI (como Automatic1111) ou ComfyUI:
- Coloque o arquivo LoRA na pasta de modelos correspondente.
- Ao gerar imagens, chame este LoRA através de sintaxe específica (como
<lora:my_style_lora:1>) no seu prompt. - Digite sua descrição de conteúdo e você pode gerar novas imagens que combinam seu estilo personalizado.

4. Técnicas de Ajuste e Dicas de Prompt
- O prompt é a chave: Os modelos da série Qwen são conhecidos por suas poderosas capacidades de compreensão e renderização de texto. Ao gerar a imagem final, combinar prompts de conteúdo claros com LoRA produz melhores resultados. Por exemplo: "
<lora:van Gogh_starry_night:0.8>, um arranha-céus moderno, céu noturno, estrelas em forma de espiral, pinceladas de óleo." - Controlar a intensidade da LoRA: Geralmente, você pode ajustar o peso na sintaxe de chamada (como mudar
:1para:0.7), onde um peso mais baixo resulta em uma influência de estilo mais fraca e uma integração mais natural com o conteúdo. - Usar prompts negativos: Exclua elementos indesejados, como "blurry, deformed, ugly" para melhorar a qualidade da imagem.
5. Código de Inferência Recomendado Oficialmente
Instalar DiffSynth-Studio:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
Qwen-Image-i2L-Style
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
# Load models
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Style.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
# Load images
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/style/1/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/style/1/0.webp"),
Image.open("data/examples/assets/style/1/1.webp"),
Image.open("data/examples/assets/style/1/2.webp"),
Image.open("data/examples/assets/style/1/3.webp"),
Image.open("data/examples/assets/style/1/4.webp"),
]
# Model inference
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
save_file(lora, "model_style.safetensors")
Qwen-Image-i2L-Coarse、Qwen-Image-i2L-Fine、Qwen-Image-i2L-Bias
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from diffsynth.utils.lora import merge_lora
from diffsynth import load_state_dict
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
Carregar modelos
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Coarse.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Fine.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
Carregar imagens
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/lora/3/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/lora/3/0.webp"),
Image.open("data/examples/assets/lora/3/1.webp"),
Image.open("data/examples/assets/lora/3/2.webp"),
Image.open("data/examples/assets/lora/3/3.webp"),
Image.open("data/examples/assets/lora/3/4.webp"),
Image.open("data/examples/assets/lora/3/5.webp"),
]
Inferência do modelo
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
lora_bias = ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Bias.safetensors")
lora_bias.download_if_necessary()
lora_bias = load_state_dict(lora_bias.path, torch_dtype=torch.bfloat16, device="cuda")
lora = merge_lora([lora, lora_bias])
save_file(lora, "model_coarse_fine_bias.safetensors")
#### Usar o LoRA gerado para gerar imagens
```py
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
vram_config = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": torch.bfloat16,
"onload_device": "cpu",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors", **vram_config),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
pipe.load_lora(pipe.dit, "model_style.safetensors")
image = pipe("a cat", seed=0, height=1024, width=1024, num_inference_steps=50)
image.save("image.webp")
6. Exemplos oficiais
Estilo
O modelo Qwen-Image-i2L-Style pode ser usado para gerar rapidamente um LoRA de estilo, basta inserir algumas imagens com estilo uniforme. Aqui estão os resultados que geramos, com sementes aleatórias todas 0.
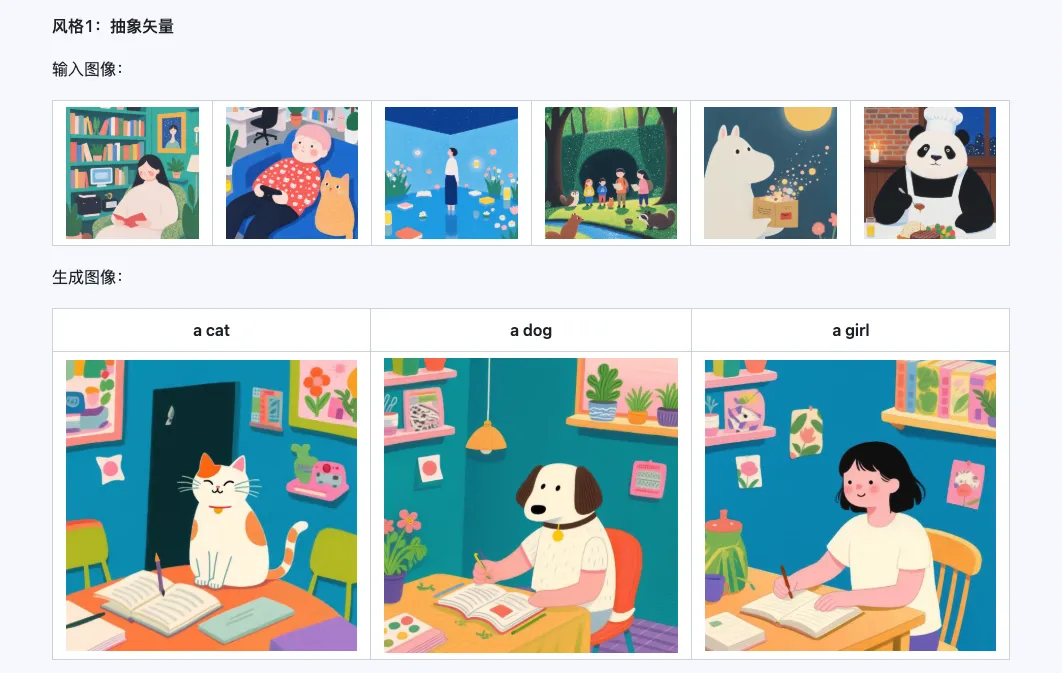
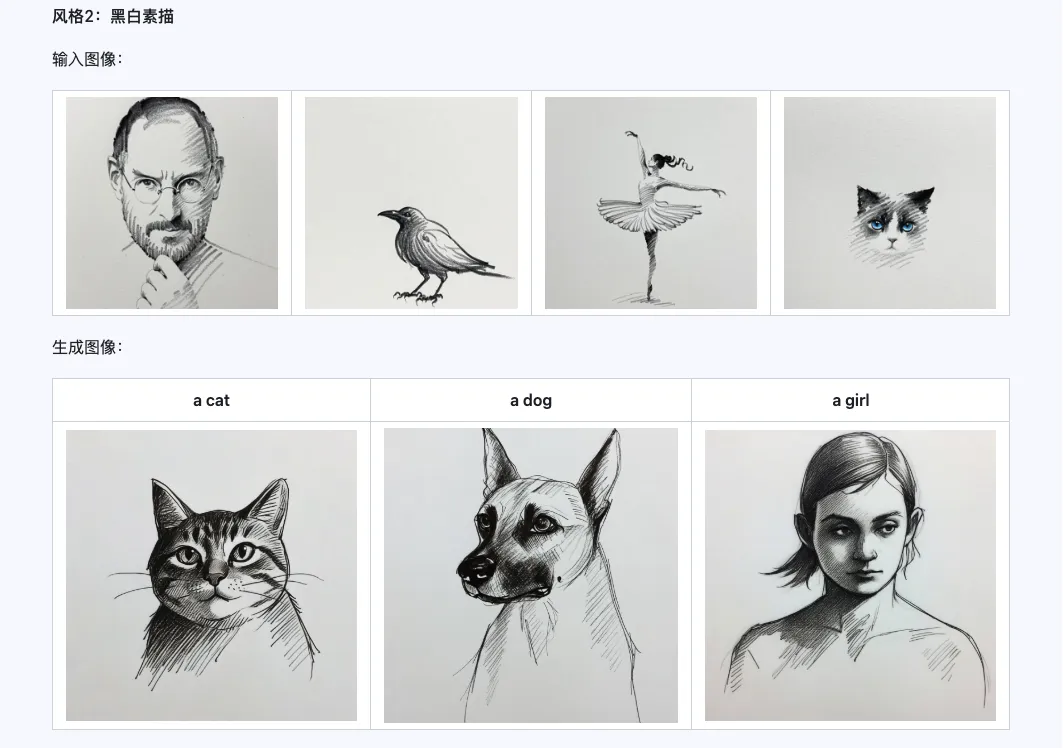
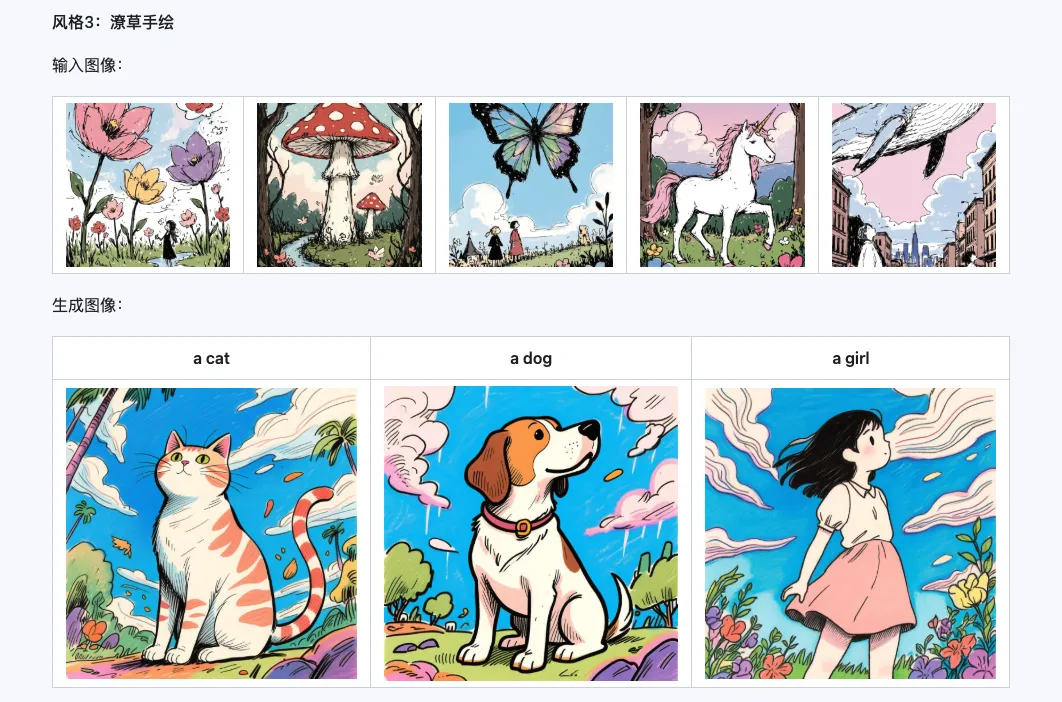
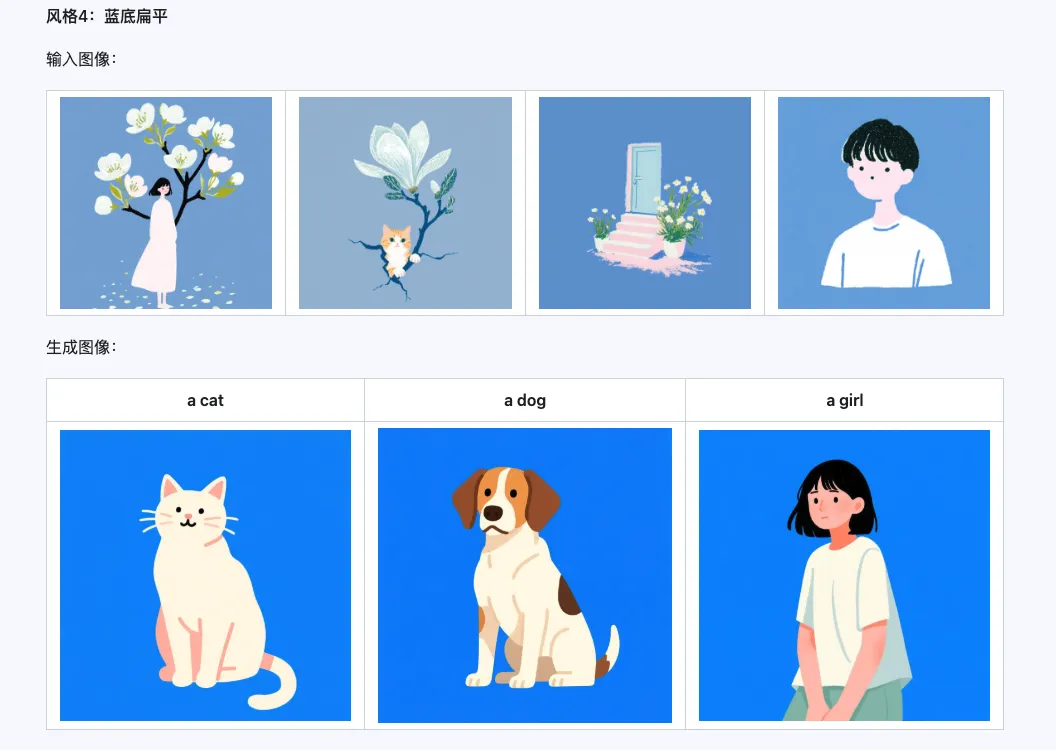
Coarse + Fine + Bias
A combinação dos três modelos Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine e Qwen-Image-i2L-Bias pode gerar pesos LoRA que preservam o conteúdo e as informações detalhadas da imagem. Este conjunto de pesos, como pesos de inicialização para o treinamento LoRA, pode acelerar a velocidade de convergência.
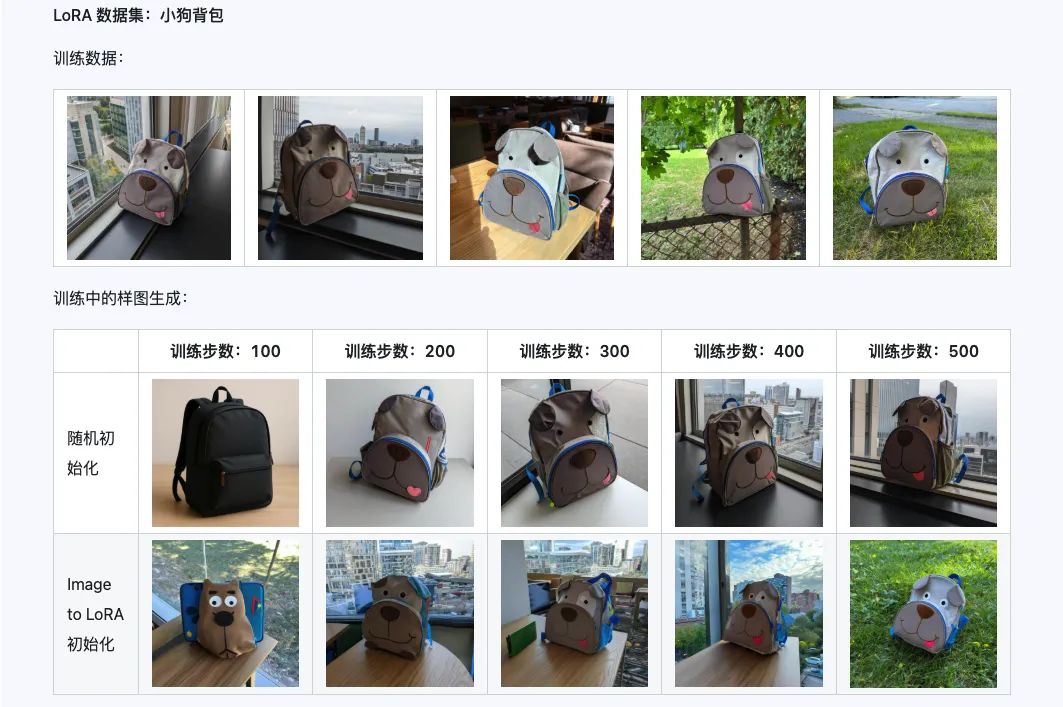
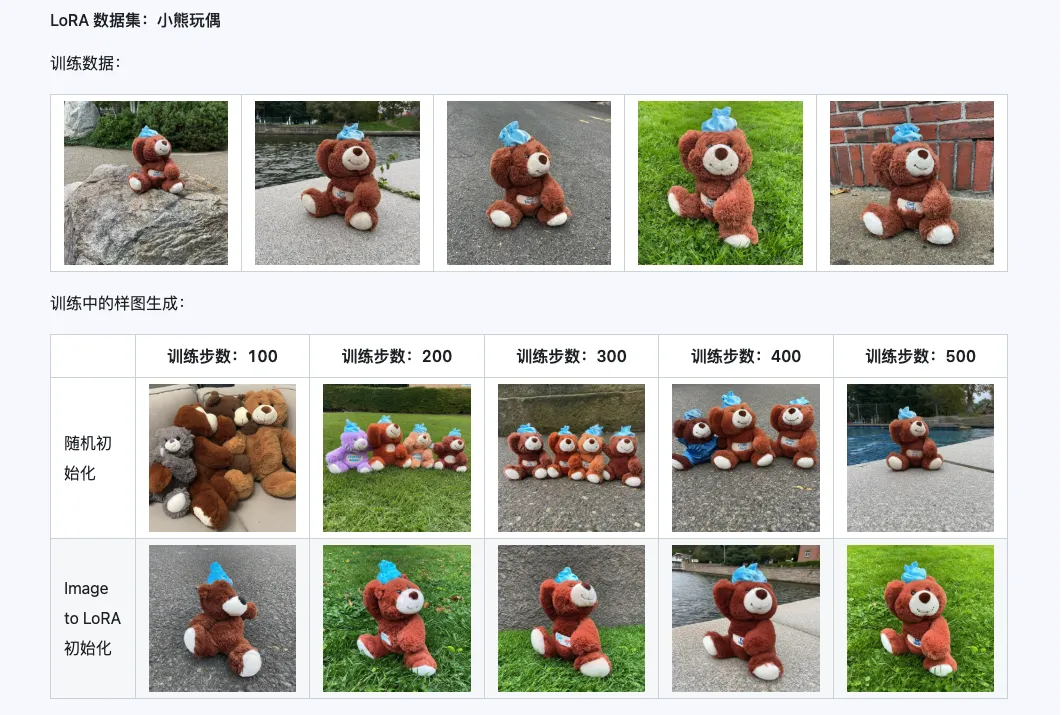

III. Cenários de Aplicação: Acelerador da sua Criatividade
- Criação artística pessoal: Experimente rapidamente diversos estilos de mestres, ou estabeleça um estilo consistente para seu portfólio.
- E-commerce e marketing: Gere rapidamente imagens promocionais com estilo consistente e conteúdo variado para diferentes linhas de produtos, reduzindo significativamente os custos de fotografia e design.
- Conceitos para jogos e cinema: Migrar rapidamente o estilo de uma arte original para múltiplos cenários e designs de personagens, gerando eficientemente conceitos visuais.
- Gestão visual de marca: Utilize o "modo de viés" para garantir que todos os materiais de marketing gerados por IA estejam em conformidade estrita com as diretrizes de identidade visual da marca.
IV. Precauções e Futuro
- Limitações atuais: Existe um desafio em derivar lógica 3D a partir de uma única imagem 2D. Por exemplo, ao treinar com uma imagem de "um gato no sofá", as imagens geradas podem mostrar objetos flutuando ou distorcidos em outros ângulos. Para estilos tridimensionais complexos, preparar imagens de múltiplos ângulos continua sendo a melhor opção.
- Desenvolvimento futuro: i2L marca a entrada da geração de imagens por IA na era da "personalização instantânea". Pode-se prever que mais aplicativos como "geração instantânea de storyboards de mangá" e "design instantâneo de personagens" surgirão, tornando a criação personalizada por IA mais comum.
Agora, encontre a imagem que melhor representa a sua estética e comece a criar seu próprio artista de IA personalizado!
Este guia de operação é baseado na documentação técnica de código aberto Qwen-Image-i2L e práticas da comunidade. Os métodos específicos de uso do modelo podem ser atualizados, recomendamos consultar simultaneamente as páginas do projeto em z-image.me, Hugging Face ou ModelScope para obter as informações mais recentes.