
Qwen-Image-i2L: Creëer je eigen AI-kunstenaar met één afbeelding: De complete gids voor gepersonaliseerde beeldcreatie
Qwen-Image-i2L: Maak met één afbeelding je eigen AI-kunstenaar, complete gids voor gepersonaliseerde creatie
Heb je ooit gewenst dat AI je favoriete illustratiestijl kon leren, maar had je geen tientallen afbeeldingen en dure rekenkracht nodig? Nu is één afbeelding genoeg. Qwen-Image-i2L, open-source van het Alibaba Tongyi Lab, is zo'n revolutionair instrument dat je als "Lego bouwen" in staat stelt met één enkele afbeelding je eigen AI-kunstenaar aan te passen.
Dit artikel zal je van begin tot eind meenemen in het gebruik van deze "stijltoverstaf".
Eerste kennismaking met i2L: Wat is het en waarom is het krachtig?
Qwen-Image-i2L is een gepersonaliseerde stijloverdrachtstool. De kern ervan is "Image to LoRA", wat betekent dat de sleutelstijlkenmerken van een invoerafbeelding worden ontbonden en "gecomprimeerd" tot een lichtgewicht LoRA (Low-Rank Adaptation) adaptermodule.
Kernprincipe: De "stijlontledingstechniek" die complex vereenvoudigt
Traditionele AI heeft enorme hoeveelheden data en lange trainingsperioden nodig om nieuwe stijlen te leren. De innovatie van i2L ligt in zijn afbeeldingsontbindingsmechanisme: het intelligent ontbindt een afbeelding in leerbare "onderdelen" zoals "kleurenbasis", "textuurstreken" en "compositie-elementen". Deze onderdelen worden verpakt in een LoRA-bestand van slechts een paar GB, dat vervolgens als plug-in kan worden geladen in mainstream tekst-naar-afbeelding-modellen zoals Stable Diffusion om oneindig veel nieuwe werken in dezelfde stijl te genereren.

Eenvoudig gezegd kan het werkproces als volgt worden samengevat in drie stappen:
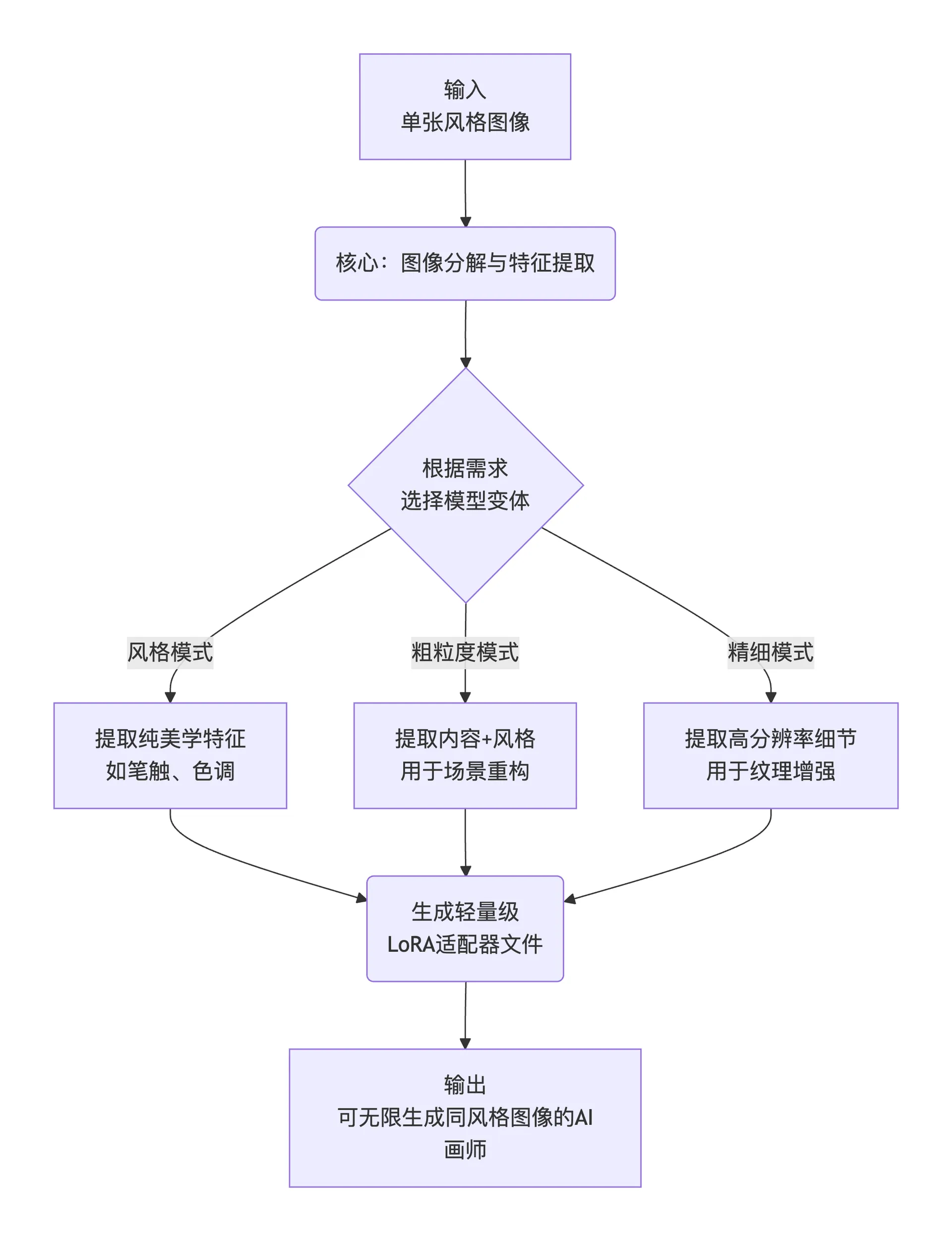
flowchart TD
A[输入<br>单张风格图像] --> B(核心:图像分解与特征提取)
B --> C{根据需求<br>选择模型变体}
C -- 风格模式 --> D1[提取纯美学特征<br>如笔触、色调]
C -- 粗粒度模式 --> D2[提取内容+风格<br>用于场景重构]
C -- 精细模式 --> D3[提取高分辨率细节<br>用于纹理增强]
D1 & D2 & D3 --> E(生成轻量级<br>LoRA适配器文件)
E --> F[输出<br>可无限生成同风格图像的AI画师]
Diepgaande principieanalyse
De kern van het model is de conversiepijplijn van afbeelding naar LoRA: de invoerafbeelding wordt eerst door encoders (zoals SigLIP2 voor semantische extractie, DINOv3 voor visuele patronen, Qwen-VL voor hoge-resolutiedetails) omgezet in ingebedde vectoren, die vervolgens direct worden toegewezen aan de LoRA-matrix (lage-rang matrices A en B). LoRA is in wezen een "patch" voor het basismodel (zoals Qwen-Image) die slechts een klein aantal parameters (meestal <1%) bijwerkt voor efficiënte injectie.
De vier varianten zijn ontworpen voor verschillende behoeften:
- Style (2.4B): Gericht op stijlextractie, zwakke detailbehoud maar sterke stijlcapture. Encoders: SigLIP2 + DINOv3.
- Coarse (7.9B): Uitbreiding van Style, vangt初步 inhoud maar details zijn niet perfect. Encoder voegt Qwen-VL toe (224x224 resolutie).
- Fine (7.6B): Incrementele upgrade van Coarse, verhoogd naar 1024x1024 resolutie, gericht op details. Moet samen met Coarse worden gebruikt.
- Bias (30M): Statische LoRA, corrigeert stijlafwijkingen tussen gegenereerde afbeeldingen en het Qwen-Image basismodel (zoals kleurvoorkeuren).
Hieronder staat een diagram van een algemene LoRA-architectuur, waarop Qwen-Image-i2L een afbeeldingsinvoerlaag toevoegt:
![]()
Beperkingen omvatten onvoldoende generalisatie (één afbeelding kan moeilijk 3D-logica vastleggen) en detailverlies (complexe texturen vereisen mogelijk meerdere afbeeldingen). Onderzoek toont aan dat het gebruik van Bias de compatibiliteit met 20-30% kan verbeteren (op basis van voorbeeldvergelijkingen).
Waarom zou je hier aandacht aan besteden? Vier kernvoordelen
- Extremee lage drempel: Vaarwel met de traditionele workflow die 20+ afbeeldingen en GPU-clusters vereist, één afbeelding op een gewone computer is voldoende.
- Extreem efficiënt: Van voorbereiding tot het genereren van een bruikbaar stijlmodel duurt het van uren tot enkele minuten.
- Uitmuntende kwaliteit: De gegenereerde LoRA kan de essentie van de originele afbeelding nauwkeurig vastleggen en naadloos integreren in mainstream AI-schilderworkflows.
- Flexibel gebruik: Of je nu de stijl van "Sterrennacht" op moderne architectuur wilt toepassen of anime-stijl wilt overbrengen naar echte foto's, je kunt het snel uitproberen.
Praktische gids: Begin met i2L vanaf nul
1. Omgevingsvoorbereiding
Net als bij het gebruik van de basis Qwen-Image-model heb je een Python-omgeving nodig. Omdat i2L is ontwikkeld op basis van het krachtige Qwen-Image (20 miljard parameters MMDiT-architectuur), zijn er bepaalde hardwarevereisten.
Hier zijn de aanbevolen configuratieverwijzingen:
| 硬件 | 最低要求 | 推荐配置 |
|---|---|---|
| GPU | NVIDIA GTX 1080 Ti (8GB) | NVIDIA RTX 4090 D of hoger |
| 内存 | 16GB | 32GB of meer |
| 存储 | 50GB beschikbare ruimte | 100GB SSD |
2. Kies je "toverstaf": Vier modelvarianten
i2L is niet één-size-fits-all, het biedt vier modellen die zijn geoptimaliseerd voor verschillende scenario's, en je moet kiezen op basis van je creatieve doelen:
| 模型变体 | 参数规模 | 核心用途 | 适合场景 |
|---|---|---|---|
| Stijlmodus | 2.4B | Gespecialiseerd in zuivere esthetische stijl overdracht | Leer waterverfstreken, olieverf textuur, specifieke filtertinten |
| Grove modus | 7.9B | Vangt inhoud en stijl voor scenarioreconstructie | Transformeer straatbeelden naar cyberpunk, landschappen naar sprookjeswerelden |
| Fijne modus | 7.6B | Genereert 1024x1024 hoge-resolutie details | Wanneer dierenvacht, bouwstenen, textielstructuren etc. benadrukt moeten worden |
| Bias modus | 30M | Zorgt ervoor dat de output consistent is met de originele stijl van Qwen-Image | Bedrijfseenheid宣传图视觉风格, voorkom merk "afwijken" |
Advies voor beginners: Begin met de Stijlmodus of Grove modus, ze kunnen de meeste voorkomende behoeften aan.
3. Kernstappen: Train je LoRA met één afbeelding
Hier is een vereenvoudigde workflow, voor specifieke code raadpleeg de officiële GitHub repository van het project.
Stap 1: Verkrijg het model
Alle modellen zijn open-source, je kunt "Qwen-Image-i2L" zoeken op de platforms Hugging Face of ModelScope en gratis downloaden.
- https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-i2L
- https://huggingface.co/DiffSynth-Studio/Qwen-Image-i2L
Stap 2: Bereid je stijlafbeelding voor
- Kies een afbeelding die je gewenste stijl duidelijk vertegenwoordigt.
- Zorg dat de afbeelding van hoge kwaliteit is, met duidelijke belangrijke elementen.
- (Optioneel) Als je een specifiek onderwerp wilt leren (zoals een bepaalde kat), gebruik dan een afbeelding waar het onderwerp opvalt.
Stap 3: Voer het trainingsscript uit
Het trainingproces vereist meestal slechts één commando. Je moet het pad van de invoerafbeelding, de opslaglocatie voor de output LoRA, en het corresponderende modeltype uit de bovenstaande tabel specificeren.
# Voorbeeldcommando (alleen ter referentie, raadpleeg de officiële documentatie)
python train_i2l.py \
--input_image "jouw_afbeelding.webp" \
--model_type "style" \ # Hier kies je "stijlmodus"
--output_lora "./mijn_stijl_lora.safetensors"
Stap 4: Gebruik de gegenereerde LoRA voor creatie
Na voltooiing van de training krijg je een .safetensors bestand. In Stable Diffusion WebUI (zoals Automatic1111) of ComfyUI:
- Plaats het LoRA-bestand in de corresponderende modelmap.
- Bij het genereren van afbeeldingen, roep de LoRA aan via specifieke syntaxis (zoals
<lora:mijn_stijl_lora:1>) in de prompt. - Voer je inhoudsbeschrijving in en genereer nieuwe afbeeldingen die zijn geïntegreerd met je aangepaste stijl.

4. Parameterafstemming en prompttechnieken
- Prompts zijn cruciaal: De Qwen-serie modellen staan bekend om hun krachtige tekstbegrip en weergavecapaciteiten. Bij het genereren van de uiteindelijke afbeelding werkt het beter om duidelijke content prompts te combineren met LoRA. Bijvoorbeeld: "
<lora:van Gogh_starry_night:0.8>, een moderne wolkenkrabber, nachthemel, draaikolvige sterren, olieverf penseelstreken." - Controleer LoRA-intensiteit: U kunt doorgaans het gewicht aanpassen in de aanroepsyntax (bijvoorbeeld
:1veranderen in:0.7). Hoe lager het gewicht, hoe zwakker de stijlinvloed en hoe natuurlijker de integratie met de content. - Gebruik negatieve prompts: Sluit ongewenste elementen uit, zoals "blurry, deformed, ugly" om de beeldkwaliteit te verbeteren.
5. Officieel aanbevolen inferentiecode
Installeer DiffSynth-Studio:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
Qwen-Image-i2L-Style
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
# Laad modellen
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Style.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
# Laad afbeeldingen
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/style/1/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/style/1/0.webp"),
Image.open("data/examples/assets/style/1/1.webp"),
Image.open("data/examples/assets/style/1/2.webp"),
Image.open("data/examples/assets/style/1/3.webp"),
Image.open("data/examples/assets/style/1/4.webp"),
]
# Model inferentie
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
save_file(lora, "model_style.safetensors")
Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine, Qwen-Image-i2L-Bias
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from diffsynth.utils.lora import merge_lora
from diffsynth import load_state_dict
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
Modellen laden
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Coarse.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Fine.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
Afbeeldingen laden
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/lora/3/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/lora/3/0.webp"),
Image.open("data/examples/assets/lora/3/1.webp"),
Image.open("data/examples/assets/lora/3/2.webp"),
Image.open("data/examples/assets/lora/3/3.webp"),
Image.open("data/examples/assets/lora/3/4.webp"),
Image.open("data/examples/assets/lora/3/5.webp"),
]
Model inferentie
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
lora_bias = ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Bias.safetensors")
lora_bias.download_if_necessary()
lora_bias = load_state_dict(lora_bias.path, torch_dtype=torch.bfloat16, device="cuda")
lora = merge_lora([lora, lora_bias])
save_file(lora, "model_coarse_fine_bias.safetensors")
#### Met gegenereerde LoRA afbeeldingen genereren
```py
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
vram_config = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": torch.bfloat16,
"onload_device": "cpu",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors", **vram_config),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
pipe.load_lora(pipe.dit, "model_style.safetensors")
image = pipe("a cat", seed=0, height=1024, width=1024, num_inference_steps=50)
image.save("image.webp")
6. Officiële voorbeelden
Style
Het Qwen-Image-i2L-Style model kan worden gebruikt voor het snel genereren van style LoRA's, door slechts een paar stijluniforme afbeeldingen in te voeren. Hieronder vindt u onze resultaten, met willekeurige zaden van 0.
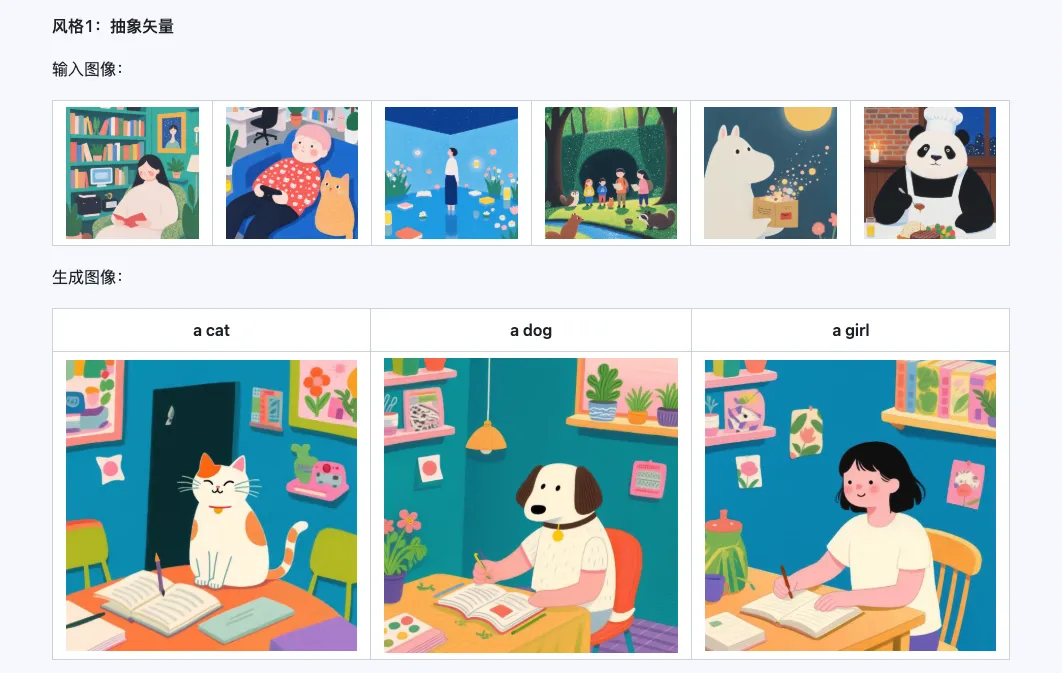
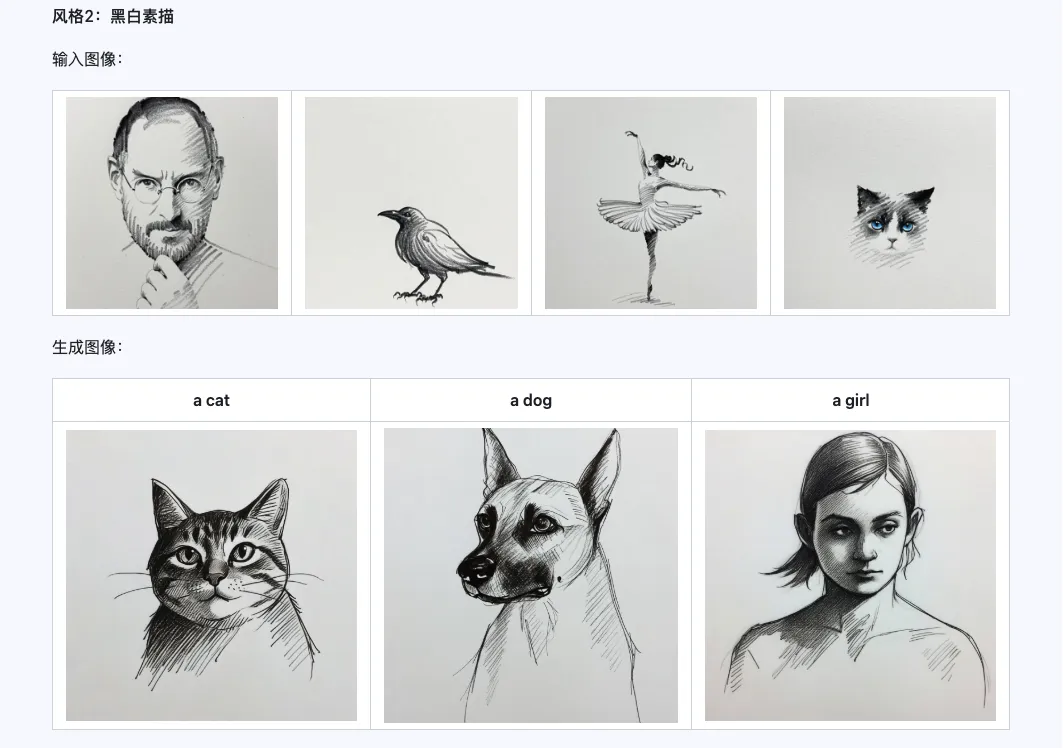
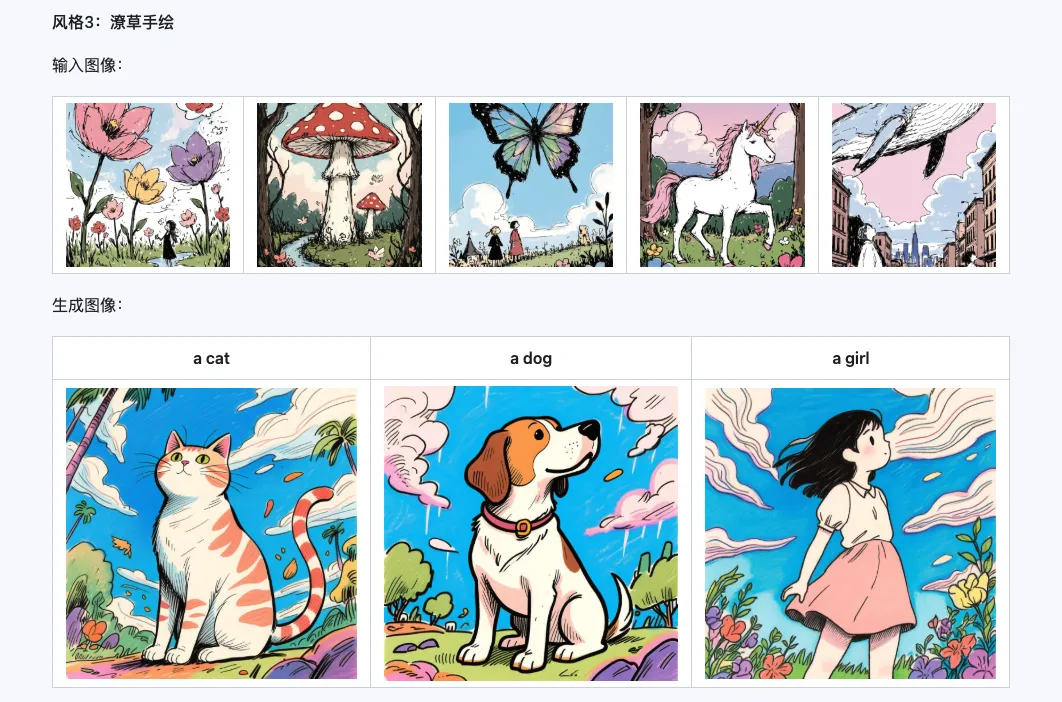
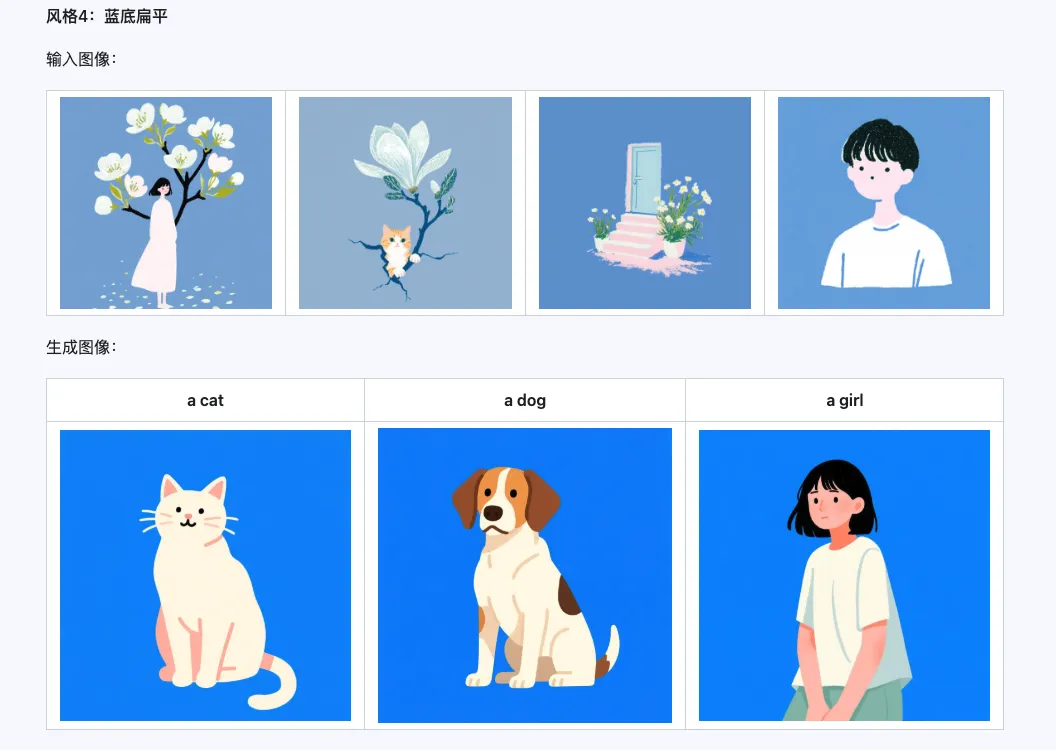
Coarse + Fine + Bias
De combinatie van Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine en Qwen-Image-i2L-Bias kan LoRA gewichten genereren die afbeeldingsinhoud en detailinformatie behouden. Deze gewichten kunnen als initialisatiegewichten voor LoRA-training worden gebruikt om de convergentiesnelheid te versnellen.
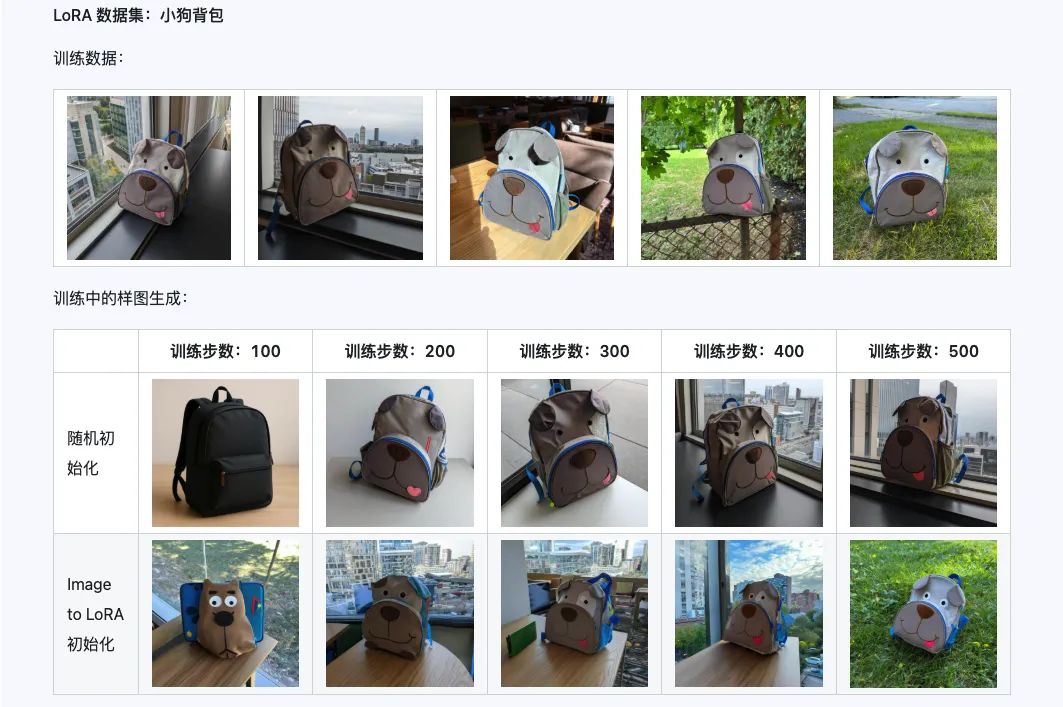
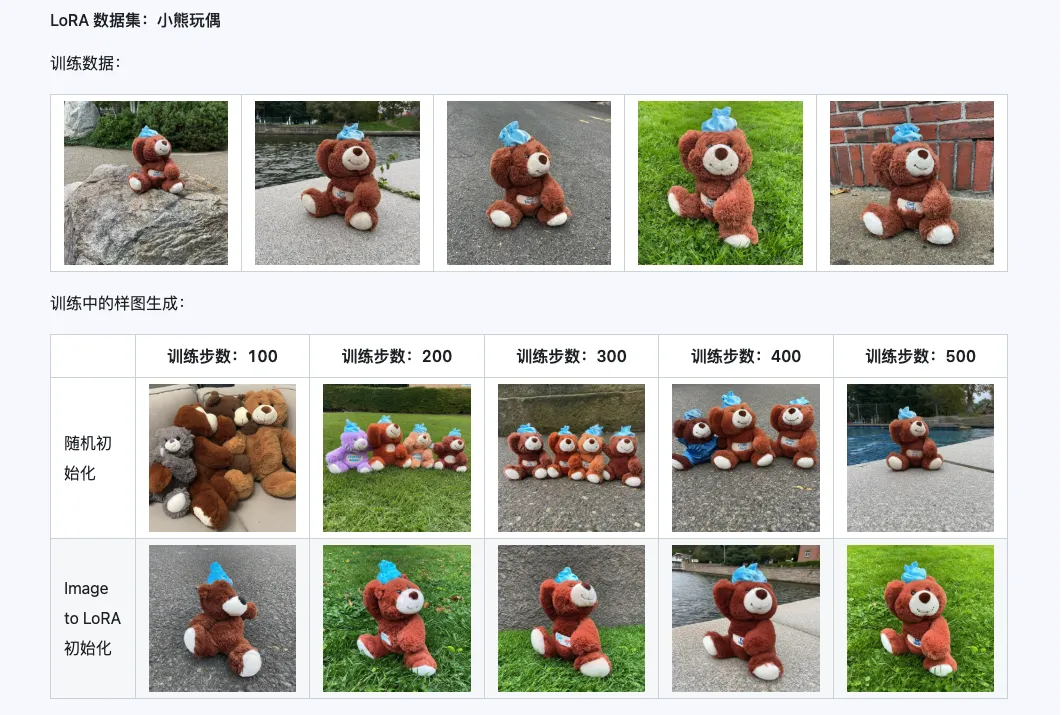

Drie. Toepassings场景: Jouw creatieve versneller
- Persoonlijke kunstcreatie: Snel verschillende meesterstijlen uitproberen, of een uniforme stijl voor je portfolio opzetten.
- E-commerce en marketing: Snel promotieafbeeldingen met een uniforme stijl maar verschillende inhoud genereren voor verschillende productlijnen, wat de kosten voor fotografie en design aanzienlijk verlaagt.
- Game- en filmconcepten: Snel de stijl van een originele afbeelding overbrengen naar meerdere场景 en ontwerpen voor personages, voor efficiënte productie van conceptafbeeldingen.
- Merkvisueel beheer: Gebruik de "bias-modus" om ervoor te zorgen dat door AI gegenereerde marketingmaterialen strikt voldoen aan de merk-VI-richtlijnen.
Vier. Aandachtspunten en toekomst
- Huidige beperkingen: Het afleiden van 3D-logica uit één enkele 2D-afbeelding is een uitdaging. Bijvoorbeeld, als je een afbeelding van "een kat op de bank" traint, kunnen de gegenereerde afbeeldingen bij andere hoeken objecten in de lucht of vervormde objecten tonen. Voor complexe driedimensionale stijlen is het nog steeds beter om afbeeldingen van meerdere hoeken voor te bereiden.
- Toekomstige ontwikkeling: i2L markeert de intrede van AI-afbeeldingsgeneratie in het "op-maat-gemaakte" tijdperk. Het is te verwachten dat er in de toekomst meer toepassingen zullen verschijnen zoals "één-klik generatie van漫画 storyboards" en "één-klik ontwerp van personages", wat gepersonaliseerde AI-creatie meer toegankelijk maakt.
Nu, zoek een afbeelding die het beste jouw esthetische voorkeur vertegenwoordigt en begin met het creëren van je eigen AI-kunstenaar!
Deze handleiding is gebaseerd op de open-source technische documentatie en communitypraktijken van Qwen-Image-i2L. De specifieke gebruiksmethoden van het model kunnen worden bijgewerkt. Het wordt aanbevolen om ook de projectpagina's op z-image.me, Hugging Face of ModelScope te raadplegen voor de meest recente informatie.