
Qwen-Image-i2L : Créez votre artiste IA personnalisé avec une seule image - Guide complet de création d'images personnalisées
Qwen-Image-i2L : Créez votre propre artiste IA avec une seule image, guide complet pour la création d'images personnalisées
Avez-vous déjà souhaité que l'IA apprenne votre style d'illustration préféré, mais vous êtes heurté au manque de dizaines d'images et de puissance de calcul coûteuse ? Maintenant, une seule image suffit. Qwen-Image-i2L, open-sourced par le laboratoire Tongyi d'Alibaba, est exactement cet outil révolutionnaire qui vous permet de personnaliser votre propre artiste IA "comme des Lego" avec une seule image.
Cet article vous guidera dès le début pour maîtriser rapidement l'utilisation de cette "baguette magique de style".
I. Première approche de i2L : Qu'est-ce que c'est et pourquoi est-il si puissant ?
Qwen-Image-i2L est un outil de transfert de style personnalisé. Son noyau est "Image vers LoRA", ce qui signifie qu'il prend les caractéristiques de style clés d'une image d'entrée, les décompose et les "compresse" en un module d'adaptateur LoRA (Low-Rank Adaptation) léger.
Principe de base : la technique de "décryptage de style" qui simplifie le complexe
L'IA traditionnelle a besoin de vastes quantités de données et d'un long entraînement pour apprendre un nouveau style. L'innovation d'i2L réside dans son mécanisme de décomposition d'image : il décompose intelligemment une image en "pièces" apprenables comme "tonalité de couleur", "touches de texture", "éléments de composition", etc. Ces pièces sont encapsulées dans un fichier LoRA de seulement quelques Go, puis peuvent être chargées comme des plug-ins dans des modèles de génération d'images à partir de texte comme Stable Diffusion pour générer d'innombrables nouvelles œuvres du même style.

En bref, son flux de travail peut être résumé en trois étapes :
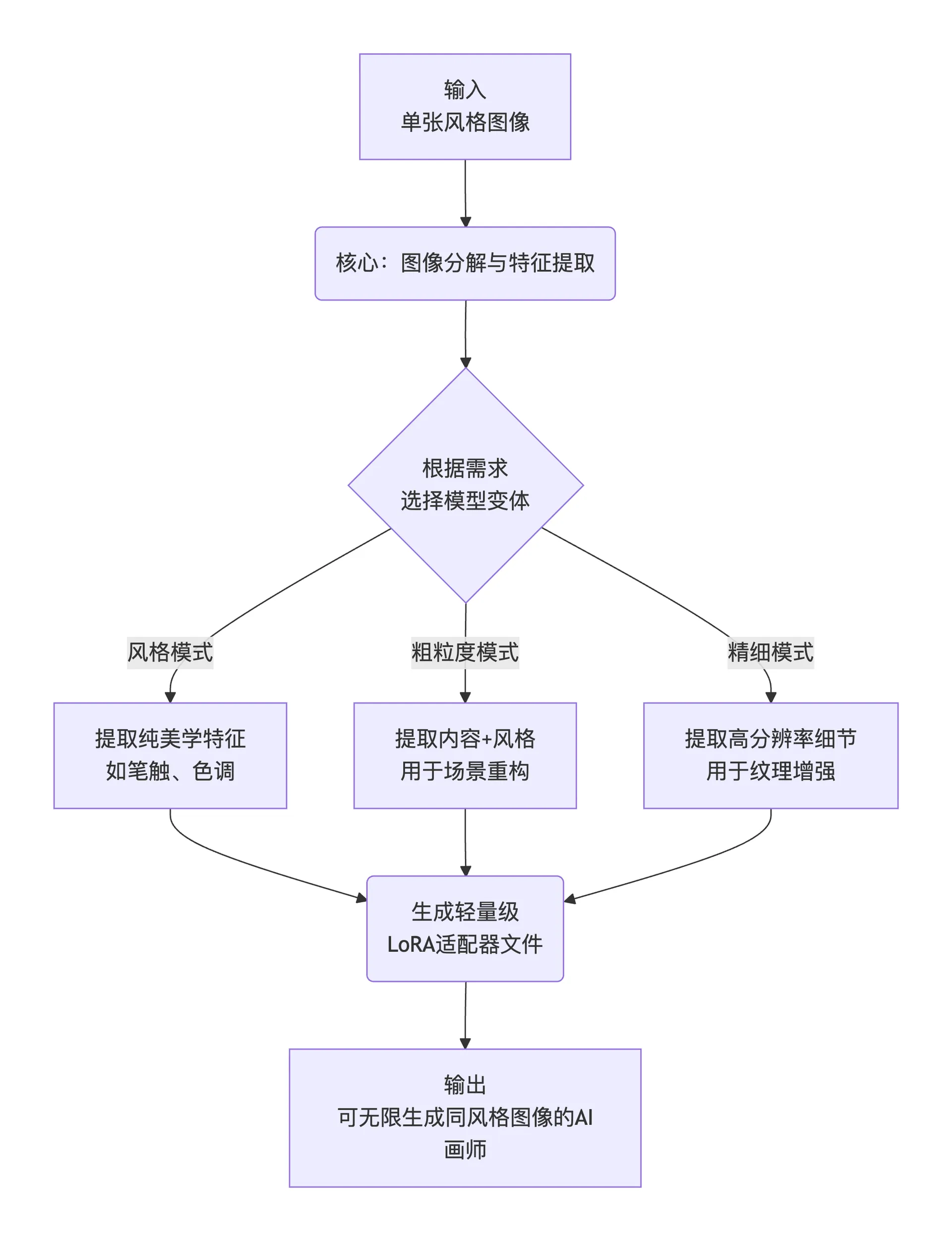
flowchart TD
A[Entrée<br>Image de style unique] --> B(Noyau : Décomposition et extraction de caractéristiques d'image)
B --> C{Selon les besoins<br>Choisir la variante de modèle}
C -- Mode style --> D1[Extraire des caractéristiques esthétiques pures<br>comme les touches de pinceau, les tons]
C -- Mode granularité grossière --> D2[Extraire contenu + style<br>pour la reconstruction de scène]
C -- Mode fin --> D3[Extraire des détails en haute résolution<br>pour l'amélioration de texture]
D1 & D2 & D3 --> E(Générer un fichier d'adaptateur<br>LoRA léger)
E --> F[Sortie<br>Artiste IA pouvant générer des images de même style à l'infini]
Analyse approfondie des principes
Le noyau du modèle est le pipeline de conversion d'image en LoRA : l'image d'entrée est d'abord transformée en vecteurs d'incorporation par un encodeur (comme SigLIP2 pour extraire la sémantique, DINOv3 pour capturer les modèles visuels, Qwen-VL pour traiter les détails en haute résolution), puis ces vecteurs sont directement mappés sur la matrice LoRA (matrices de rang bas A et B). LoRA est essentiellement un "correctif" pour le modèle de base (comme Qwen-Image), ne mettant à jour que quelques paramètres (généralement <1%), permettant une injection efficace.
Quatre variantes sont conçues pour différents besoins :
- Style (2.4B) : Se concentre sur l'extraction de style, la préservation des détails est faible, mais la capture de style est forte. Encodeur : SigLIP2 + DINOv3.
- Grossier (7.9B) : Extension de Style, capture initialement le contenu, mais les détails ne sont pas parfaits. Encodeur ajoutant Qwen-VL (résolution 224x224).
- Fin (7.6B) : Amélioration incrémentale de Grossier, porté à une résolution de 1024x1024, se concentrant sur les détails. Doit être utilisé avec Grossier.
- Biais (30M) : LoRA statique, corrige le décalage de style entre l'image générée et le modèle de base Qwen-Image (comme les préférences de couleur).
La figure ci-dessous est un schéma d'architecture LoRA général, Qwen-Image-i2L ajoute une couche d'entrée d'image sur cette base :
![]()
Les limitations incluent une généralisation insuffisante (une seule image a du mal à capturer la logique 3D) et une perte de détails (des textures complexes peuvent nécessiter plusieurs images en entrée). La recherche montre que l'utilisation de Biais peut améliorer la compatibilité de 20-30% (basé sur des comparaisons d'exemples).
Pourquoi s'intéresser à lui ? Quatre avantages fondamentaux
- Seuil d'entrée extrêmement bas : Adieu au processus traditionnel nécessitant plus de 20 images et un cluster GPU, une seule image et un ordinateur ordinaire suffisent.
- Efficacité extrême : De la préparation à la généération d'un modèle de style utilisable, le temps est réduit de plusieurs heures à quelques minutes.
- Qualité exceptionnelle : Le LoRA généré peut capturer précisément l'essence de l'image originale et s'intégrer de manière transparente au flux de travail de peinture IA principal.
- Utilisation flexible : Que ce soit pour appliquer le style de "La Nuit étoilée" sur des bâtiments modernes ou pour transférer un style anime sur des photos de personnes réelles, tout peut être rapidement testé.
II. Guide pratique : Commencer à utiliser i2L dès zéro
1. Préparation de l'environnement
Comme pour l'utilisation du modèle de base Qwen-Image, vous avez besoin d'un environnement Python. Étant donné qu'i2L est développé sur la base du puissant modèle Qwen-Image (architecture MMDiT de 20 milliards de paramètres), il présente certaines exigences matérielles.
Voici les configurations recommandées :
| Matériel | Exigences minimales | Configuration recommandée |
|---|---|---|
| GPU | NVIDIA GTX 1080 Ti (8GB) | NVIDIA RTX 4090 D ou supérieur |
| Mémoire | 16GB | 32GB ou plus |
| Stockage | 50GB d'espace disponible | 100GB SSD |
2. Choisissez votre "baguette magique" : Quatre variantes de modèle
i2L n'est pas une solution unique, il propose quatre modèles optimisés pour différents scénarios, et vous devez choisir en fonction de vos objectifs de création :
| Variante de modèle | Taille des paramètres | Utilisation principale | Scénarios adaptés |
|---|---|---|---|
| Mode style | 2.4B | Spécialisé dans la migration de style esthétique pur | Apprendre les touches de pinceau aquarelle, la texture de l'huile, les filtres de ton spécifiques |
| Mode granularité grossière | 7.9B | Capturer contenu et style, pour la reconstruction de scène | Transformer une rue en cyberpunk, un paysage en monde de conte de fées |
| Mode fin | 7.6B | Générer des détails en haute résolution 1024x1024 | Lorsqu'il faut mettre en évidence les poils d'animaux, les briques de bâtiment, les textures de tissu, etc. |
| Mode biais | 30M | Assurer que la sortie est cohérente avec le style natif de Qwen-Image | Unifier le style visuel des images promotionnelles d'entreprise, empêcher la marque de "dévier" |
Conseil pour débutants : Commencez par le mode style ou le mode granularité grossière, ils peuvent gérer la plupart des besoins courants.
3. Étapes clés : Entraînez votre LoRA avec une seule image
Voici un flux de travail opérationnel simplifié, pour le code spécifique, veuillez vous référer au dépôt GitHub officiel du projet.
Étape 1 : Obtenir le modèle
Tous les modèles sont open-source, vous pouvez rechercher "Qwen-Image-i2L" sur les plateformes Hugging Face ou ModelScope et les télécharger gratuitement.
Étape 2 : Préparer votre image de style
- Choisissez une image qui représente clairement le style souhaité.
- Assurez-vous que l'image est de haute qualité, avec les éléments clairs.
- (Optionnel) Si vous souhaitez apprendre un sujet spécifique (comme un chat particulier), utilisez si possible une image où le sujet est bien mis en avant.
Étape 3 : Exécuter le script d'entraînement
Le processus d'entraînement ne nécessite généralement qu'une seule commande. Vous devez spécifier le chemin de l'image d'entrée, l'emplacement de sauvegarde du LoRA de sortie, et choisir le type de modèle correspondant dans le tableau ci-dessus.
# Exemple de commande (à titre indicatif, veuillez vous référer à la documentation officielle)
python train_i2l.py \
--input_image "votre_image.webp" \
--model_type "style" \ # Ici, choisissez "mode style"
--output_lora "./mon_style_lora.safetensors"
Étape 4 : Utiliser le LoRA généré pour créer
Une fois l'entraînement terminé, vous obtiendrez un fichier .safetensors. Dans Stable Diffusion WebUI (comme Automatic1111) ou ComfyUI :
- Placez le fichier LoRA dans le dossier de modèles correspondant.
- Lors de la génération d'images, appelez ce LoRA via une syntaxe spécifique (comme
<lora:mon_style_lora:1>) dans votre prompt. - Entrez votre description de contenu, et vous pourrez générer de nouvelles images fusionnant le style personnalisé.

4. Techniques de réglage et de prompt engineering
- Les prompts sont essentiels : Les modèles de la série Qwen sont connus pour leurs puissantes capacités de compréhension et de rendu textuel. Pour générer l'image finale, combiner des prompts de contenu clairs et des LoRA donne de meilleurs résultats. Par exemple : "
<lora:van Gogh_starry_night:0.8>, un gratte-ciel moderne, ciel nocturne, étoiles tourbillonnantes, coups de pinceau à l'huile." - Contrôle de l'intensité LoRA : On peut généralement ajuster le poids dans la syntaxe d'appel (comme changer
:1en:0.7), un poids plus faible signifie une influence de style plus faible et une intégration plus naturelle avec le contenu. - Utilisation de prompts négatifs : Exclure les éléments indésirables comme "blurry, deformed, ugly" pour améliorer la qualité de l'image.
5. Code d'inférence recommandé officiellement
Installation de DiffSynth-Studio :
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
Qwen-Image-i2L-Style
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
# Charger les modèles
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Style.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
# Charger les images
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/style/1/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/style/1/0.webp"),
Image.open("data/examples/assets/style/1/1.webp"),
Image.open("data/examples/assets/style/1/2.webp"),
Image.open("data/examples/assets/style/1/3.webp"),
Image.open("data/examples/assets/style/1/4.webp"),
]
# Inférence du modèle
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
save_file(lora, "model_style.safetensors")
Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine, Qwen-Image-i2L-Bias
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from diffsynth.utils.lora import merge_lora
from diffsynth import load_state_dict
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
Charger les modèles
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Coarse.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Fine.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
Charger les images
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/lora/3/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/lora/3/0.webp"),
Image.open("data/examples/assets/lora/3/1.webp"),
Image.open("data/examples/assets/lora/3/2.webp"),
Image.open("data/examples/assets/lora/3/3.webp"),
Image.open("data/examples/assets/lora/3/4.webp"),
Image.open("data/examples/assets/lora/3/5.webp"),
]
Inférence du modèle
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
lora_bias = ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Bias.safetensors")
lora_bias.download_if_necessary()
lora_bias = load_state_dict(lora_bias.path, torch_dtype=torch.bfloat16, device="cuda")
lora = merge_lora([lora, lora_bias])
save_file(lora, "model_coarse_fine_bias.safetensors")
#### Utiliser le LoRA généré pour créer des images
```py
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
vram_config = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": torch.bfloat16,
"onload_device": "cpu",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors", **vram_config),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
pipe.load_lora(pipe.dit, "model_style.safetensors")
image = pipe("a cat", seed=0, height=1024, width=1024, num_inference_steps=50)
image.save("image.webp")
6. Exemples officiels
Style
Le modèle Qwen-Image-i2L-Style peut être utilisé pour générer rapidement un LoRA de style, il suffit d'entrer quelques images avec un style uniforme. Voici les résultats que nous avons générés, avec une graine aléatoire de 0 dans tous les cas.
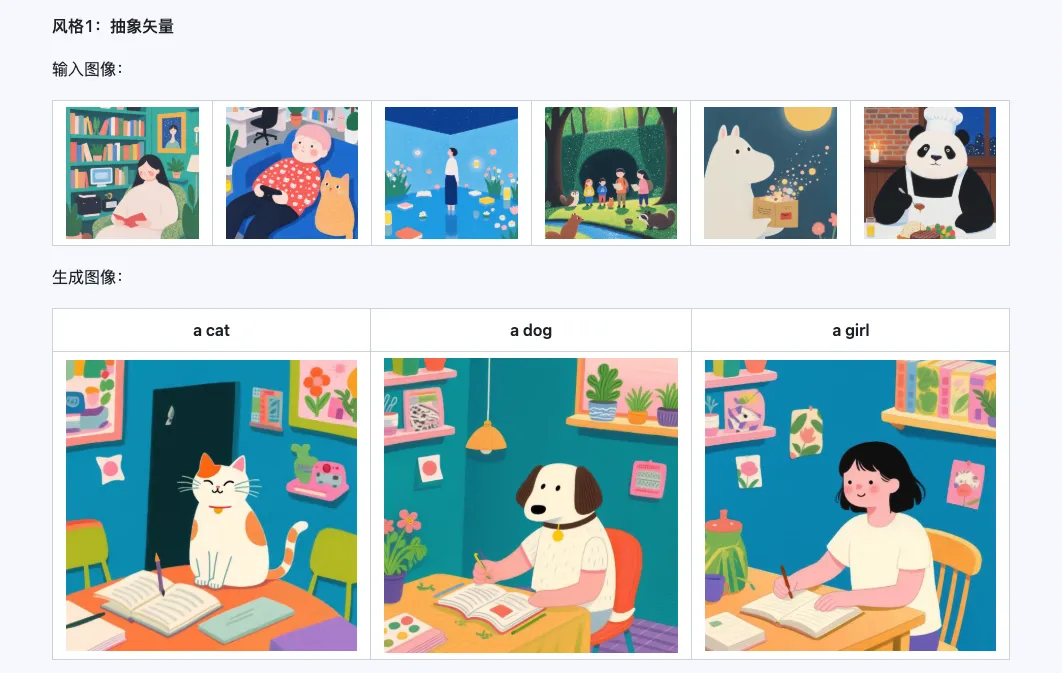
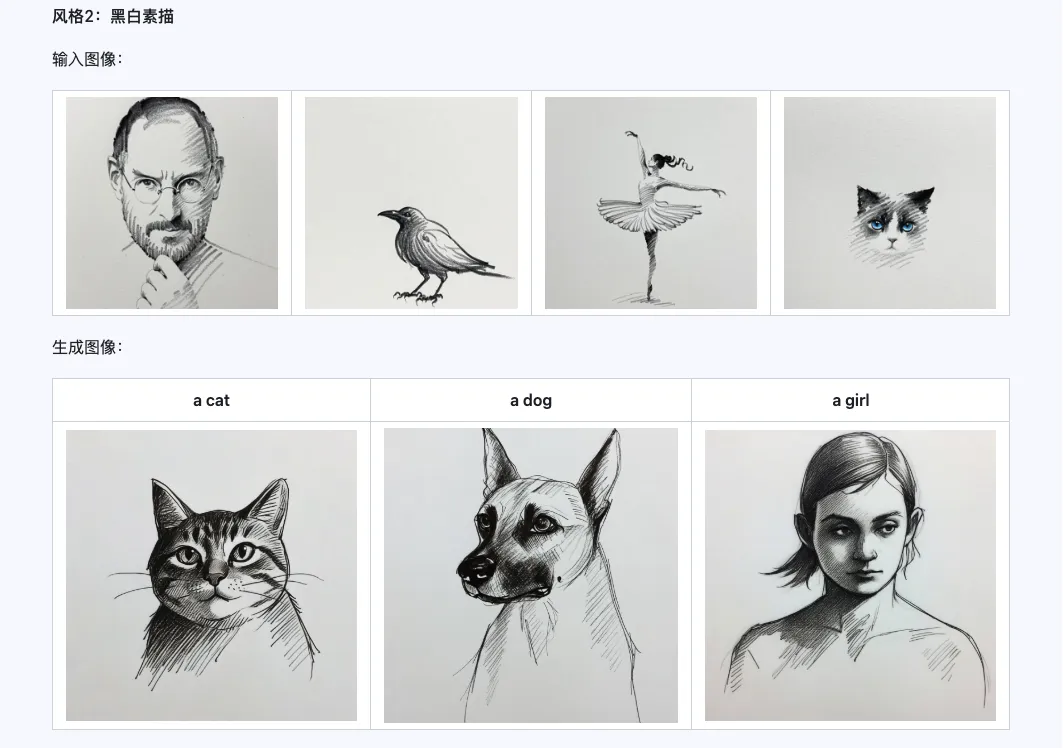
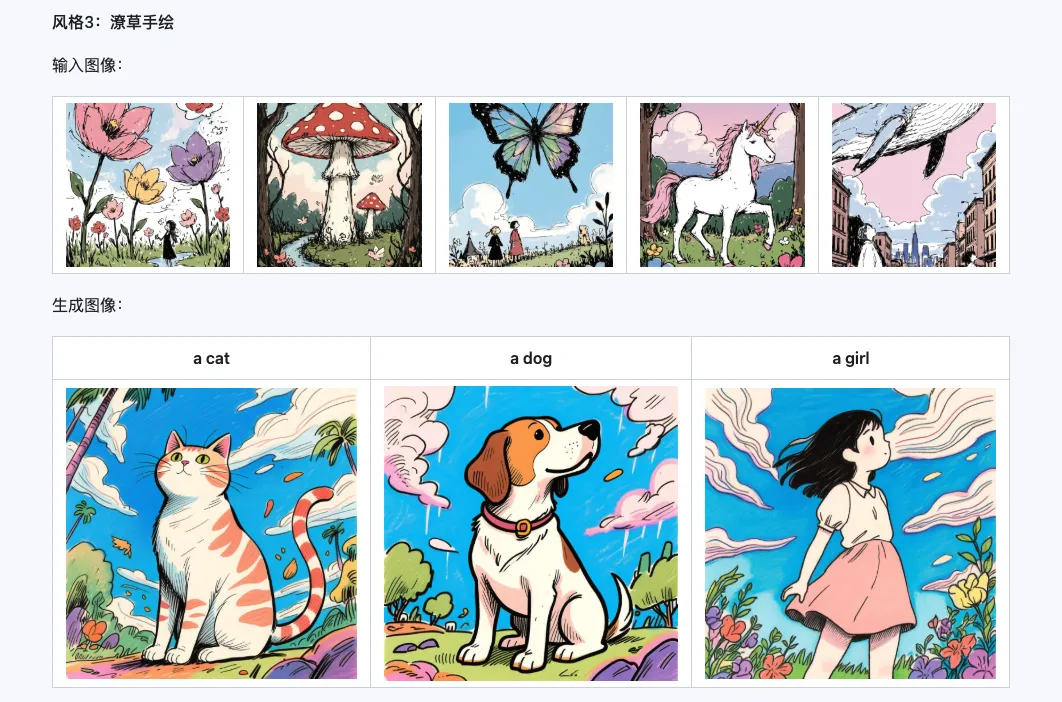
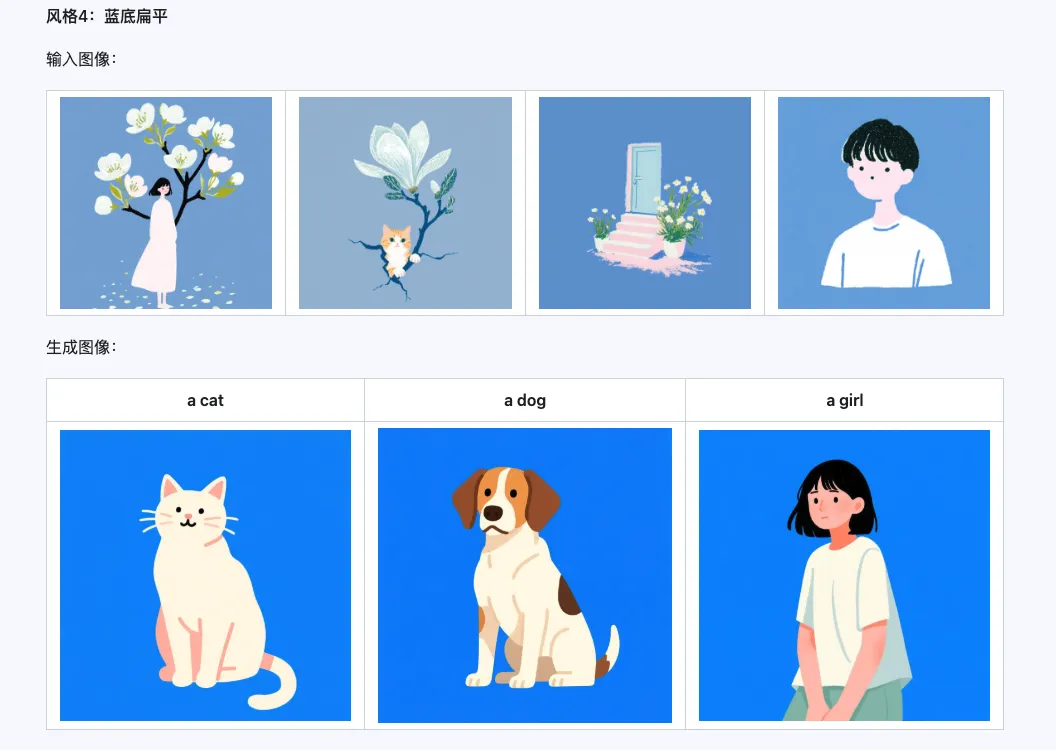
Coarse + Fine + Bias
La combinaison des trois modèles Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine et Qwen-Image-i2L-Bias peut générer des poids LoRA qui préservent le contenu et les détails des images. Ces poids, utilisés comme poids d'initialisation pour l'entraînement de LoRA, peuvent accélérer la vitesse de convergence.
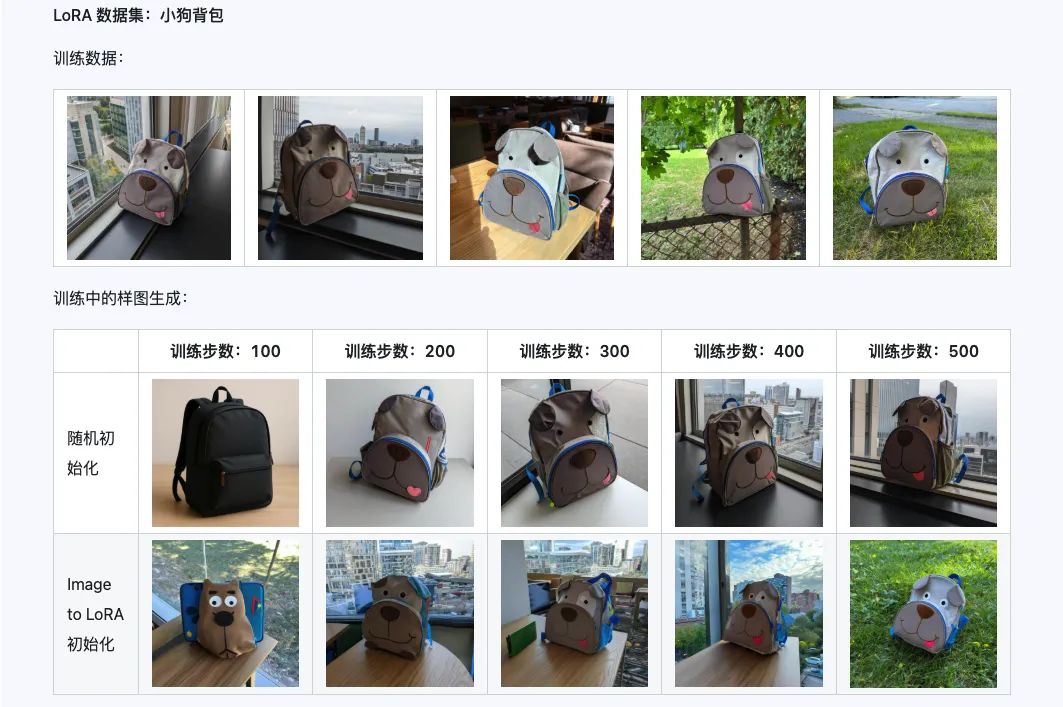
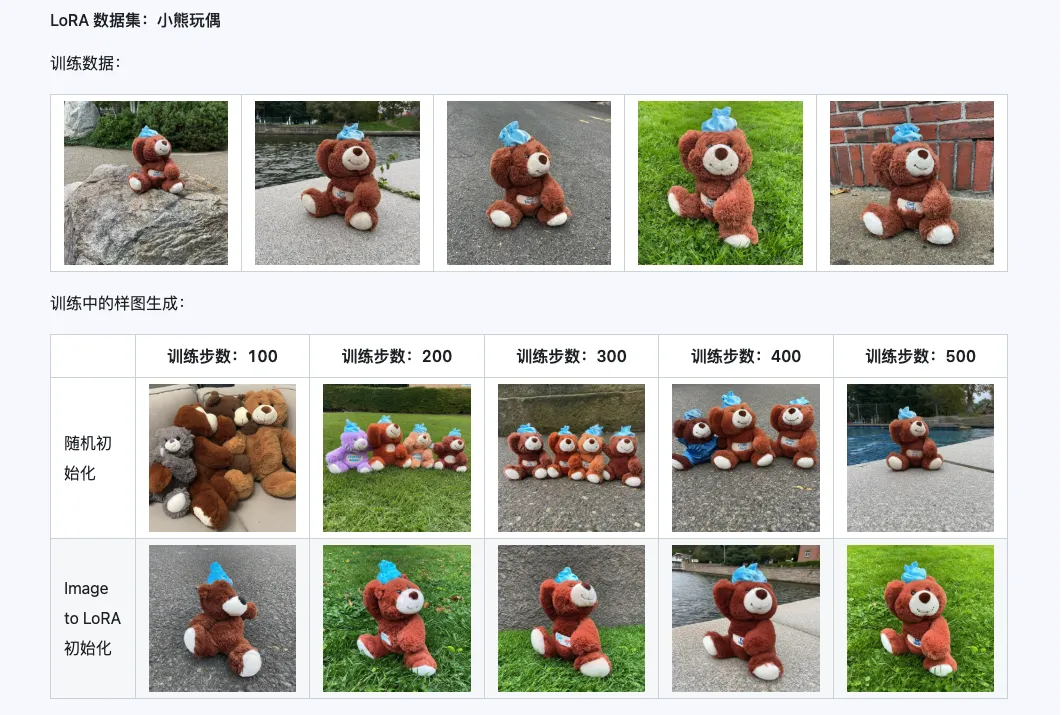

Troisième partie : Scénarios d'application : votre accélérateur de créativité
- Création artistique personnelle : Essayez rapidement différents styles de maîtres, ou établissez un style cohérent pour votre portfolio.
- E-commerce et marketing : Générez rapidement des images promotionnelles de style uniforme mais avec différents contenus pour différentes gammes de produits, réduisant considérablement les coûts de prise de vue et de design.
- Concepts de jeux et de cinéma : Appliquez rapidement le style d'une illustration originale à plusieurs scènes et designs de personnages, produisant efficacement des concepts.
- Gestion visuelle de la marque : Utilisez le "mode biais" pour garantir que tous les supports marketing générés par l'AI respectent strictement les normes VI de la marque.
Quatrième partie : Considérations et avenir
- Limitations actuelles : Il existe des défis à déduire la logique 3D à partir d'une seule image 2D. Par exemple, en entraînant l'AI avec une image d'un "chat sur un canapé", les images générées peuvent présenter des objets flottants ou déformés à d'autres angles. Pour les styles tridimensionnels complexes, il est toujours préférable de préparer des images sous plusieurs angles.
- Développement futur : i2L marque l'entrée de la génération d'images AI dans l'ère de la "personnalisation instantanée". On peut s'attendre à ce que davantage d'applications telles que "générer en un clic des storyboards de bande dessinée" ou "concevoir en un clic des personnages" émergent, rendant la création AI personnalisée plus répandue.
Maintenant, trouvez une image qui représente le mieux l'esthétique que vous avez en tête et commencez à créer votre propre peintre AI !
Ce guide pratique est basé sur la documentation technique open source de Qwen-Image-i2L et les pratiques communautaires. Les méthodes d'utilisation spécifiques du modèle peuvent être mises à jour, il est recommandé de consulter simultanément les pages de projet sur z-image.me, Hugging Face ou ModelScope pour obtenir les informations les plus récentes.