
Qwen-Image-i2L: Создание персонального ИИ-художника из одного изображения: полное руководство по персонализированному созданию изображений
Qwen-Image-i2L: Создание персонального ИИ-художника из одного изображения, полное руководство по персонализированному созданию изображений
Вы когда-нибудь хотели, чтобы ИИ научился вашему любимому стилю иллюстраций, но не хватало десятков изображений и дорогих вычислительных мощностей? Теперь одного изображения достаточно. Qwen-Image-i2L, открытая исходный код лабораторией Alibaba Tongyi, является именно таким революционным инструментом, который позволяет вам, как "собирать LEGO", создать собственного ИИ-художника с помощью всего одного изображения.
Эта статья проведет вас с нуля, чтобы быстро освоить использование этой "стилевой волшебной палочки".
I. Знакомство с i2L: что это и почему это мощно?
Qwen-Image-i2L - это инструмент для персонализированного переноса стиля. Его суть - "Image to LoRA", что означает разложение ключевых стилевых характеристик входного изображения и "сжатие" их в легковесный модуль адаптера LoRA (Low-Rank Adaptation).
Основной принцип: "техника декомпозиции стиля", упрощающая сложное
Традиционные ИИ для изучения нового стиля требуют огромных объемов данных и длительного обучения. Инновация i2L заключается в его механизме декомпозиции изображений: он, как вскрытие "слепых коробок", умно разбивает одно изображение на обучаемые "компоненты", такие как "цветовая гамма", "текстура мазков", "композиционные элементы". Эти компоненты упаковываются в файл LoRA размером всего несколько гигабайт, который затем можно загружать как плагин в主流ные текстовые модели генерации изображений, такие как Stable Diffusion, для создания бесчисленных новых работ в том же стиле.

Прост говоря, его рабочий процесс можно свести к следующим трем шагам:
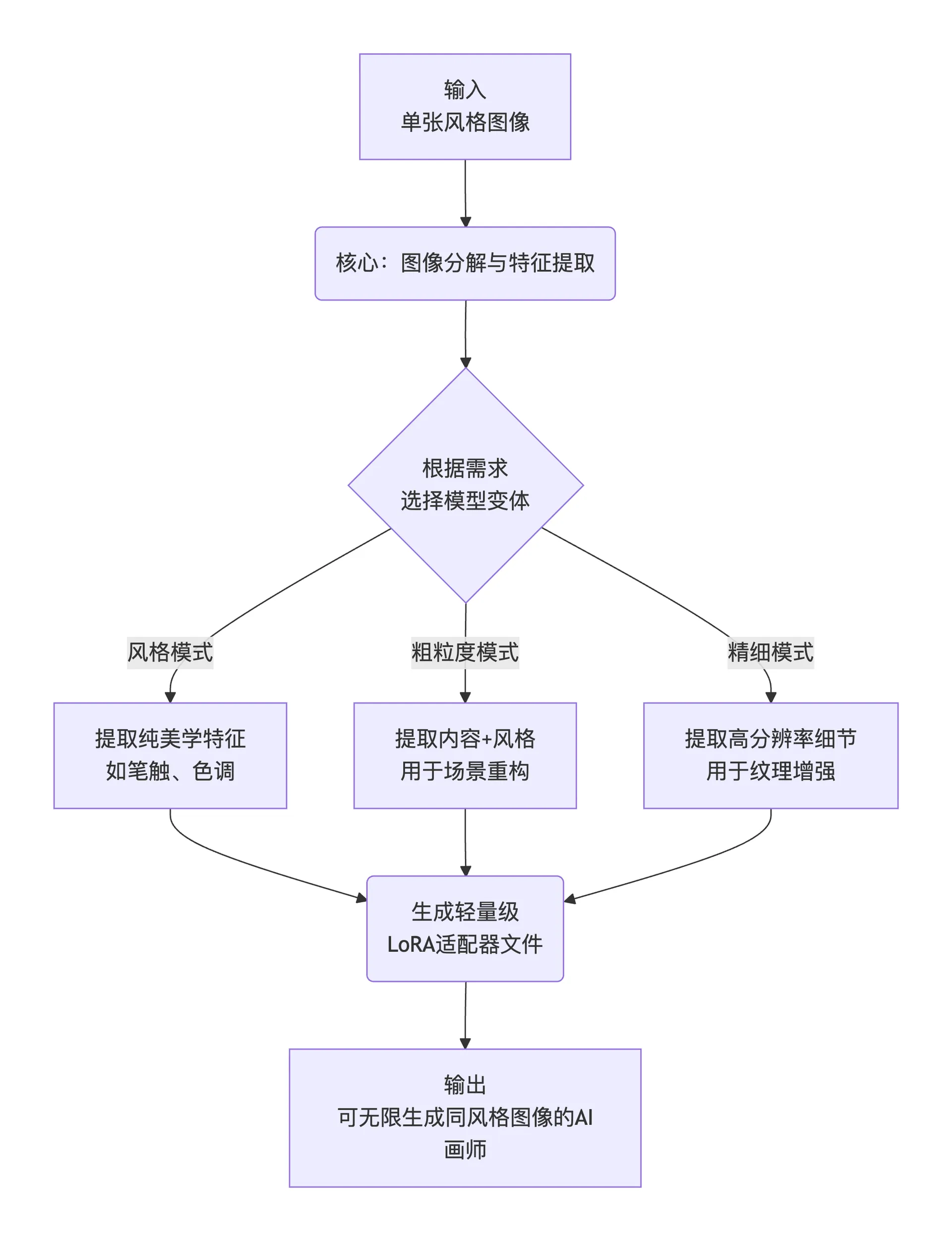
flowchart TD
A[输入<br>单张风格图像] --> B(核心:图像分解与特征提取)
B --> C{根据需求<br>选择模型变体}
C -- 风格模式 --> D1[提取纯美学特征<br>如笔触、色调]
C -- 粗粒度模式 --> D2[提取内容+风格<br>用于场景重构]
C -- 精细模式 --> D3[提取高分辨率细节<br>用于纹理增强]
D1 & D2 & D3 --> E(生成轻量级<br>LoRA适配器文件)
E --> F[输出<br>可无限生成同风格图像的AI画师]
Глубокий анализ принципов работы
Суть модели - это конвейер преобразования изображений в LoRA: входное изображение сначала преобразуется в векторные вложения с помощью кодировщиков (SigLIP2 для извлечения семантики, DINOv3 для захвата визуальных паттернов, Qwen-VL для обработки высокоразмерных деталей), а затем эти векторы напрямую отображаются в матрицы LoRA (матрицы низкого ранга A и B). LoRA по сути является "патчем" для базовой модели (такой как Qwen-Image), обновляющим лишь небольшое количество параметров (обычно <1%), что обеспечивает эффективную инъекцию.
Четыре варианта модели разработаны для разных потребностей:
- Style (2.4B): Специализируется на извлечении стиля, слабо сохраняет детали, но сильно улавливает стиль. Кодировщики: SigLIP2 + DINOv3.
- Coarse (7.9B): Расширенная версия Style, первоначально захватывает содержание, но детали не идеальны. Добавлен кодировщик Qwen-VL (разрешение 224x224).
- Fine (7.6B): Инкрементальное обновление Coarse, повышенное до разрешения 1024x1024, фокусируется на деталях. Должно использоваться вместе с Coarse.
- Bias (30M): Статический LoRA, исправляющий расхождения в стиле между сгенерированными изображениями и базовой моделью Qwen-Image (например, цветовые предпочтения).
На приведенной ниже схеме показана общая архитектура LoRA, на основе которой Qwen-Image-i2L добавляет слой ввода изображения:
![]()
Ограничения включают недостаточную обобщаемость (одного изображения недостаточно для захвата 3D-логики) и потерю деталей (для сложных текстур может потребоваться ввод нескольких изображений). Исследования показывают, что использование Bias может повысить совместимость на 20-30% (на основе сравнительных примеров).
Почему стоит обратить на это внимание? Четыре ключевых преимущества
- Очень низкий порог входа: Прощай традиционный процесс, требующий более 20 изображений и кластера GPU, теперь достаточно одного изображения и обычного компьютера.
- Высочайшая эффективность: от подготовки до создания готовой стилевой модели время сокращается с нескольких часов до нескольких минут.
- Отличное качество: сгенерированный LoRA точно улавливает суть исходного изображения и бесшовно интегрируется в основной процесс AI-рисования.
- Гибкое применение: независимо от того, хотите ли вы применить стиль "Звездная ночь" к современной архитектуре или перенести аниме-стиль на фотографию реального человека, можно быстро попробовать.
II. Практическое руководство: использование i2L с нуля
1. Подготовка окружения
Как и при использовании базовой модели Qwen-Image, вам понадобится Python-окружение. Поскольку i2L разработана на основе мощной Qwen-Image (архитектура MMDiT с 20 миллиардами параметров), к оборудованию предъявляются определенные требования.
Вот рекомендуемые конфигурации:
| Оборудование | Минимальные требования | Рекомендуемая конфигурация |
|---|---|---|
| GPU | NVIDIA GTX 1080 Ti (8GB) | NVIDIA RTX 4090 D или выше |
| Память | 16GB | 32GB или выше |
| Хранилище | 50GB свободного пространства | 100GB SSD |
2. Выберите свою "волшебную палочку": четыре варианта модели
i2L не является универсальным решением, оно предлагает четыре модели, оптимизированных для разных сценариев, и вам нужно выбирать в зависимости от целей творчества:
| Вариант модели | Количество параметров | Основное назначение | Подходящие сценарии |
|---|---|---|---|
| Стиль | 2.4B | Специализация на чисто эстетическом переносе стиля | Изучение акварельных мазков, масляной текстуры, определ цветовых тонов фильтров |
| Грубый | 7.9B | Захват содержания и стиля, реконструкция сцен | Превращение городских улиц в киберпанк, пейзажей - в сказочные миры |
| Точный | 7.6B | Генерация высокоразмерных деталей 1024x1024 | Когда нужно подчеркнуть детали, такие как шерсть животных, кирпичи зданий, текстуры тканей |
| Смещение | 30M | Обеспечение соответствия вывода оригинальному стилю Qwen-Image | Единый визуальный стиль рекламных материалов компании, предотвращение "отклонения" бренда |
Рекомендация для новичков: Начните с стиль-режима или грубого режима, они могут удовлетворить большинство обычных потребностей.
3. Основные шаги: обучение вашего LoRA на одном изображении
Вот упрощенная операционная процедура, конкретный код следует проверять в официальном репозитории GitHub проекта.
Шаг 1: Получение модели
Все модели открыты исходный кодом, вы можете искать "Qwen-Image-i2L" на платформах Hugging Face или ModelScope и бесплатно скачать их.
Шаг 2: Подготовка вашего стилевого изображения
- Выберите изображение, которое четко представляет нужный вам стиль.
- Убедитесь, что изображение имеет высокое качество, ключевые элементы четкие.
- (Опционально) Если вы хотите изучить определенный объект (например, конкретное животное), постарайтесь использовать изображение, где этот объект является доминирующим.
Шаг 3: Запуск скрипта обучения
Процесс обучения обычно требует всего одной команды. Вам нужно указать путь к входному изображению, место сохранения выходного LoRA и выбрать соответствующий тип модели из таблицы выше.
# 示例命令(仅供参考,请以官方文档为准)
python train_i2l.py \
--input_image "你的图片.webp" \
--model_type "style" \ # 此处选择"风格模式"
--output_lora "./my_style_lora.safetensors"
Шаг 4: Использование сгенерированного LoRA для творчества
После завершения обучения вы получите файл .safetensors. В Stable Diffusion WebUI (например, Automatic1111) или ComfyUI:
- Поместите файл LoRA в соответствующую папку с моделями.
- При генерации изображения используйте в промптах специальный синтаксис (например,
<lora:my_style_lora:1>) для вызова этого LoRA. - Введите описание вашего контента, и будет сгенерировано новое изображение, объединяющее пользовательский стиль.

4. Настройка и техники промптов
- Промпты являются ключевыми: Модели серии Qwen известны своей мощной способностью к пониманию и визуализации текста. При генерации конечного изображения сочетание четких контентных промптов и LoRA дает лучшие результаты. Например: "
<lora:van Gogh_starry_night:0.8>, современный небоскреб, ночное небо, вихревые звезды, мазки масляной краски." - Контроль интенсивности LoRA: Обычно можно регулировать вес в синтаксисе вызова (например, изменив
:1на:0.7), чем ниже вес, тем слабее влияние стиля и тем естественнее слияние с контентом. - Использование негативных промптов: Исключение нежелательных элементов, таких как "blurry, deformed, ugly" для улучшения качества изображения.
5. Официально рекомендуемый код для вывода
Установка DiffSynth-Studio:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
Qwen-Image-i2L-Style
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
# Load models
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Style.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
# Load images
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/style/1/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/style/1/0.webp"),
Image.open("data/examples/assets/style/1/1.webp"),
Image.open("data/examples/assets/style/1/2.webp"),
Image.open("data/examples/assets/style/1/3.webp"),
Image.open("data/examples/assets/style/1/4.webp"),
]
# Model inference
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
save_file(lora, "model_style.safetensors")
Qwen-Image-i2L-Coarse、Qwen-Image-i2L-Fine、Qwen-Image-i2L-Bias
from diffsynth.pipelines.qwen_image import (
QwenImagePipeline, ModelConfig,
QwenImageUnit_Image2LoRAEncode, QwenImageUnit_Image2LoRADecode
)
from diffsynth.utils.lora import merge_lora
from diffsynth import load_state_dict
from modelscope import snapshot_download
from safetensors.torch import save_file
import torch
from PIL import Image
vram_config_disk_offload = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": "disk",
"onload_device": "disk",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
Загрузка моделей
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="SigLIP2-G384/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/General-Image-Encoders", origin_file_pattern="DINOv3-7B/model.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Coarse.safetensors", **vram_config_disk_offload),
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Fine.safetensors", **vram_config_disk_offload),
],
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
Загрузка изображений
snapshot_download(
model_id="DiffSynth-Studio/Qwen-Image-i2L",
allow_file_pattern="assets/lora/3/*",
local_dir="data/examples"
)
images = [
Image.open("data/examples/assets/lora/3/0.webp"),
Image.open("data/examples/assets/lora/3/1.webp"),
Image.open("data/examples/assets/lora/3/2.webp"),
Image.open("data/examples/assets/lora/3/3.webp"),
Image.open("data/examples/assets/lora/3/4.webp"),
Image.open("data/examples/assets/lora/3/5.webp"),
]
Инференс модели
with torch.no_grad():
embs = QwenImageUnit_Image2LoRAEncode().process(pipe, image2lora_images=images)
lora = QwenImageUnit_Image2LoRADecode().process(pipe, **embs)["lora"]
lora_bias = ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-i2L", origin_file_pattern="Qwen-Image-i2L-Bias.safetensors")
lora_bias.download_if_necessary()
lora_bias = load_state_dict(lora_bias.path, torch_dtype=torch.bfloat16, device="cuda")
lora = merge_lora([lora, lora_bias])
save_file(lora, "model_coarse_fine_bias.safetensors")
#### Генерация изображений с использованием созданного LoRA
```py
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
vram_config = {
"offload_dtype": "disk",
"offload_device": "disk",
"onload_dtype": torch.bfloat16,
"onload_device": "cpu",
"preparing_dtype": torch.bfloat16,
"preparing_device": "cuda",
"computation_dtype": torch.bfloat16,
"computation_device": "cuda",
}
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors", **vram_config),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors", **vram_config),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
vram_limit=torch.cuda.mem_get_info("cuda")[1] / (1024 ** 3) - 0.5,
)
pipe.load_lora(pipe.dit, "model_style.safetensors")
image = pipe("a cat", seed=0, height=1024, width=1024, num_inference_steps=50)
image.save("image.webp")
6. Официальные примеры
Стиль
Модель Qwen-Image-i2L-Style может использоваться для быстрой генерации стилевого LoRA, просто вводя несколько изображений с единым стилем. Ниже приведены результаты нашей генерации, случайные семена равны 0.
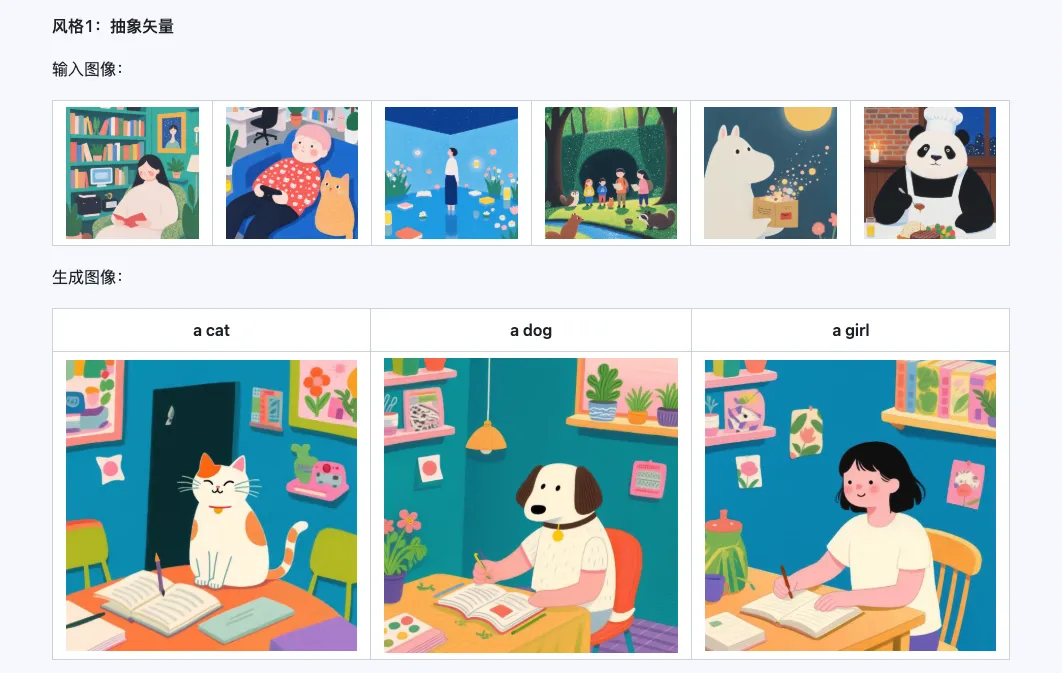
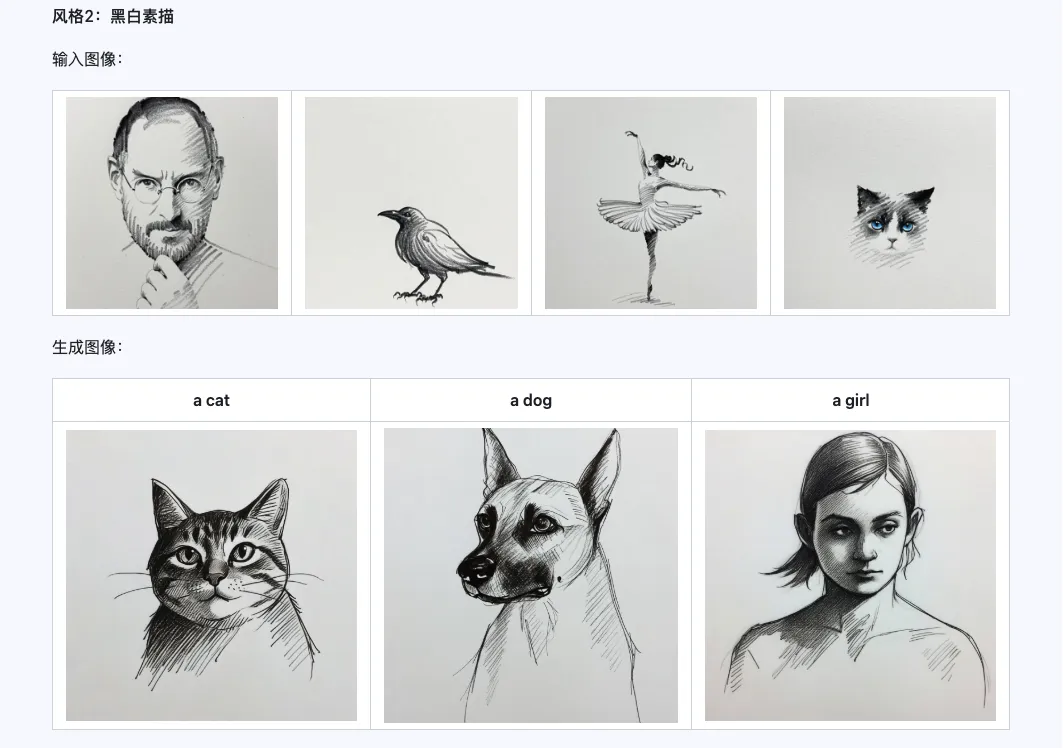
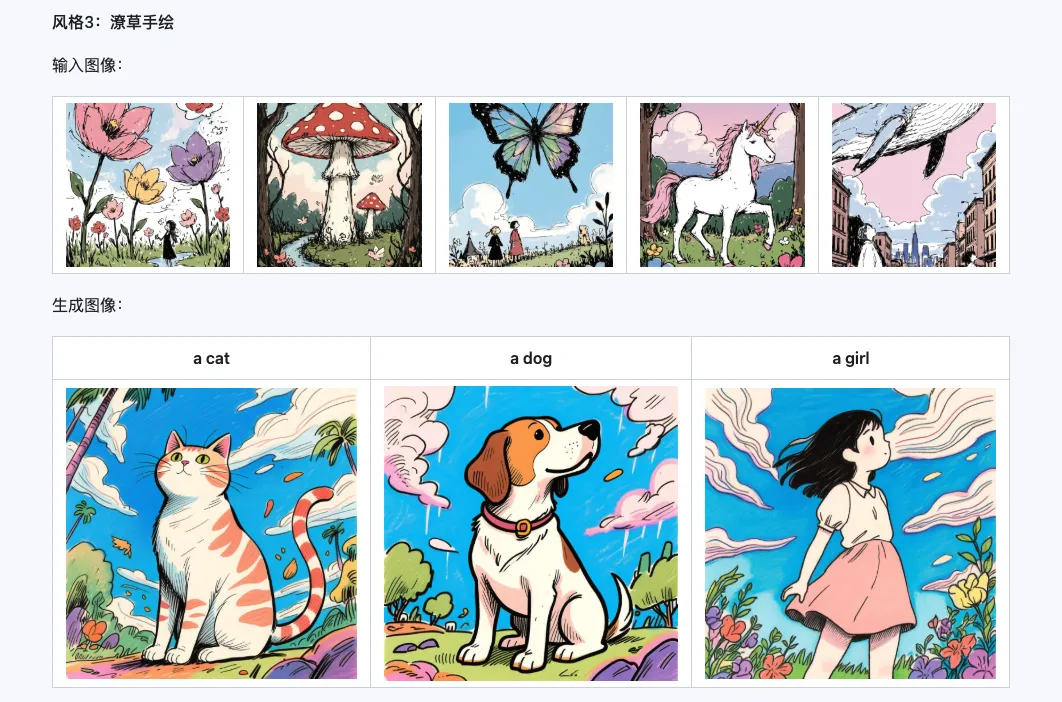
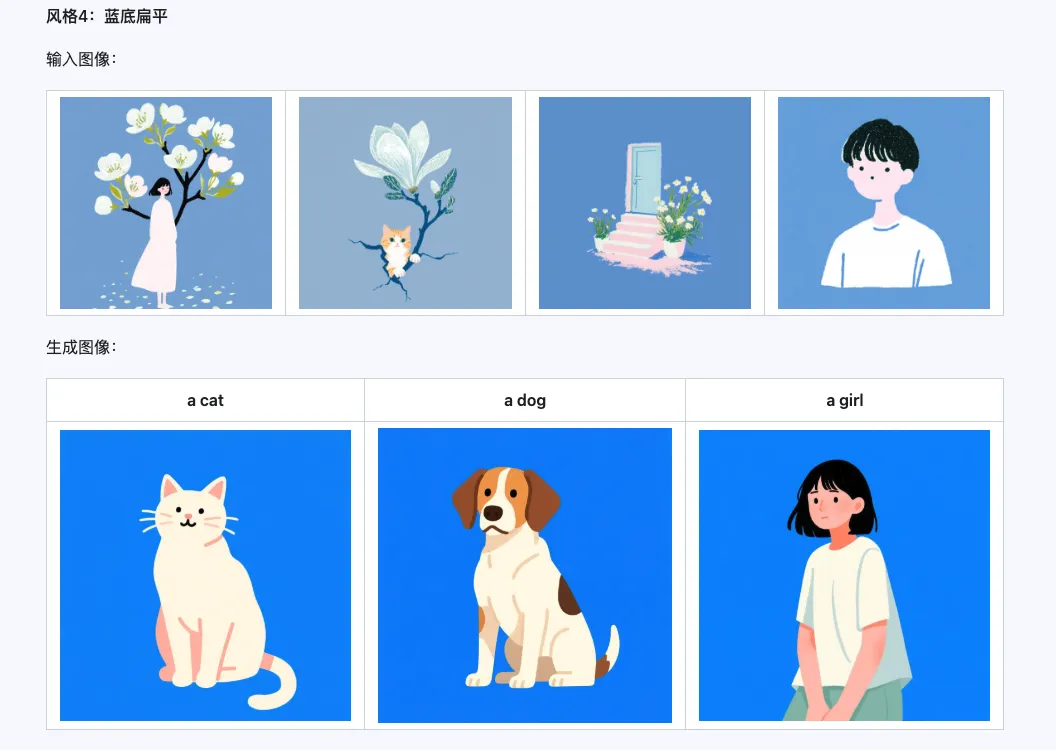
Coarse + Fine + Bias
Комбинация Qwen-Image-i2L-Coarse, Qwen-Image-i2L-Fine и Qwen-Image-i2L-Bias позволяет генерировать веса LoRA, сохраняющие содержимое и детали изображения. Этот набор весов в качестве начальных весов для обучения LoRA может ускорить скорость сходимости.
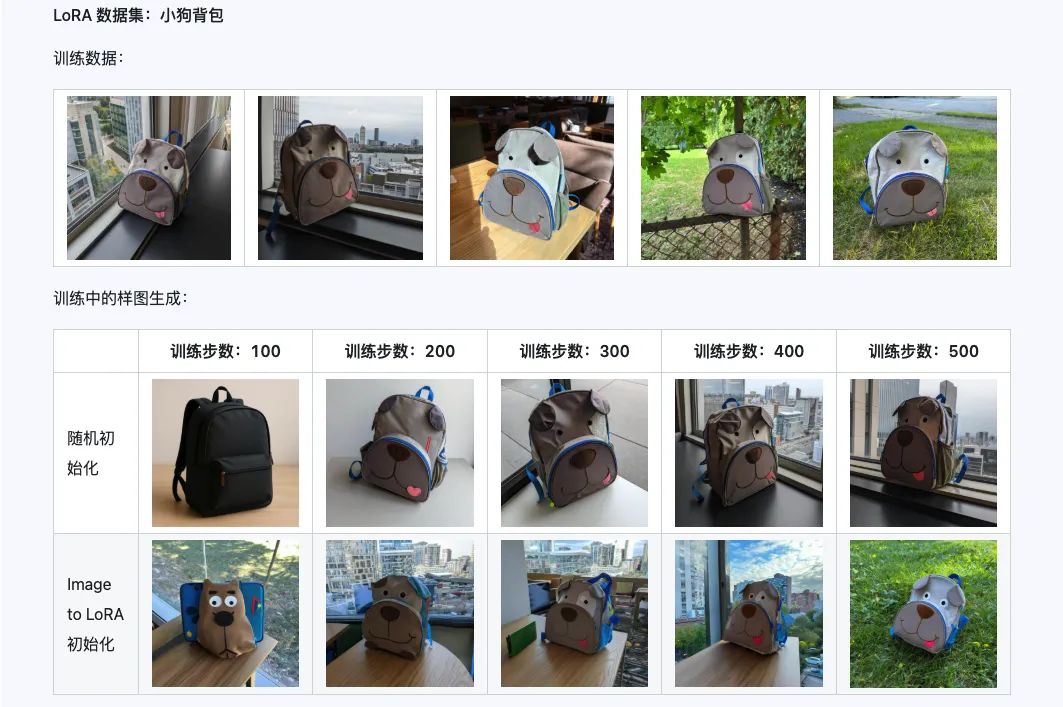
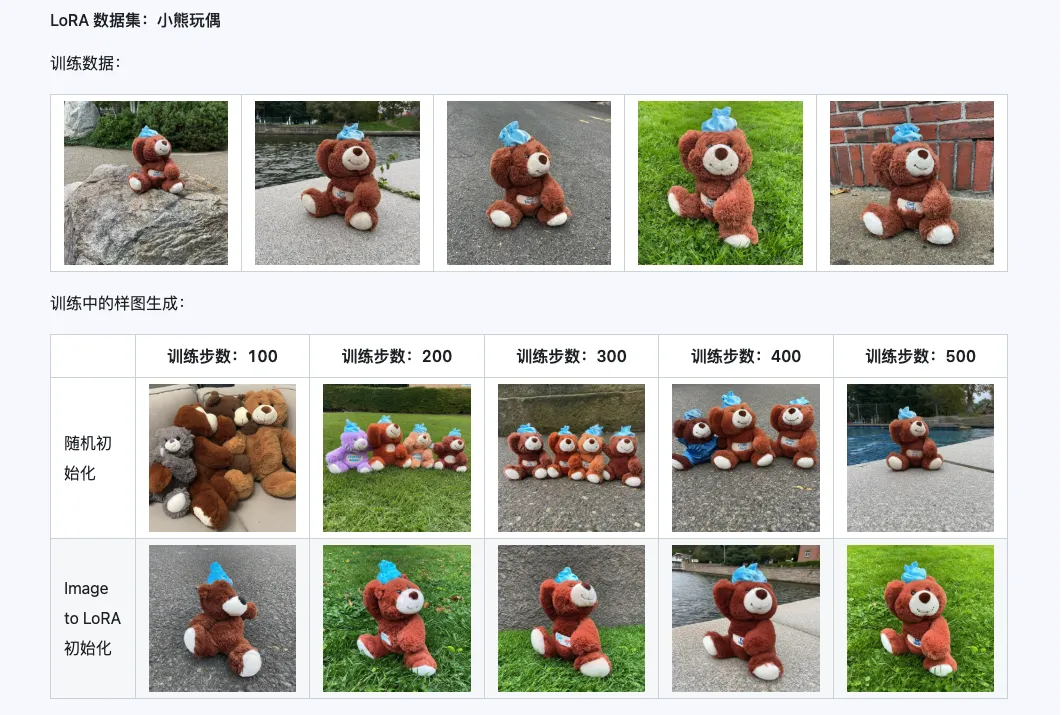

III. Сценарии применения: ваш ускоритель творчества
- Персональное творчество: быстро пробуйте различные стили известных мастеров или создавайте единый стиль для своего портфолио.
- E-commerce и маркетинг: быстро создавайте рекламные изображения с единым стилем, но разным содержанием для различных продуктов, значительно снижая расходы на фотосъемку и дизайн.
- Концепции для игр и кино: быстро переносите стиль одного концепт-арта на множество сцен и дизайнов персонажей, эффективно создавая концепт-арт.
- Управление брендингом: используйте "режим предвзятости" (bias mode), чтобы гарантировать, что все сгенерированные ИИ маркетинговые материалы строго соответствуют фирменному стилю.
IV. Важные замечания и будущее
- Текущие ограничения: вывод 3D-логики из одного 2D-изображения представляет собой вызов. Например, при обучении на изображении "кошка на диване", сгенерированные изображения могут показывать объекты парящими в воздухе или деформированными при других ракурсах. Для сложных 3D-стилей подготовка изображений с разных ракурсов остается лучшим выбором.
- Будущее развитие: i2L标志着 вступление генерации изображений ИИ в "эпоху мгновенной кастомизации". Можно ожидать, что в будущем появятся такие приложения, как "однокнопочное создание раскадровки комиксов", "однокнопочный дизайн персонажей" и другие, что сделает персонализированное творчество с помощью ИИ более доступным.
Теперь найдите изображение, которое лучше всего отражает ваше эстетическое видение, и начните создавать своего персонального ИИ-художника!
В данном руководстве по использованию основано на технической документации с открытым исходным кодом Qwen-Image-i2L и практике сообщества. Конкретные методы использования модели могут обновляться, рекомендуется также обращаться к главной странице проекта на z-image.me, Hugging Face или ModelScope для получения самой актуальной информации.