
Alibaba、Z-Image i2Lを大規模発表:1枚の画像からLoRAを秒単位で生成、Baseモデルよりより破壊的か?
アリババが発表した新モデルが、なぜZ-Image Baseより重要なのか?
2026年1月27日、アリババの通義研究所が新モデル「Z-Image i2L」を正式に発表しました。
公式発表によると、このZ-Imageアーキテクチャに基づくImage to LoRAモデルは、以前に発表されたZ-Image Baseよりもより破壊的です。1.61Bのパラメータ規模ですが、一体どのような優れた点があり、世界一のオープンソースモデルよりも重要だと敢えて言えるのでしょうか?
まず要点をまとめます(面倒な人はここだけ見てください):
-
✅ 発表日:2026年1月27日、アリババ通義研究所製、オープンソースで商用利用可能(Apache 2.0ライセンス);
-
✅ 核心的なブレークスルー:単一の画像から即座にLoRAを生成でき、大量のデータや数時間のトレーニングは不要;
-
✅ 性能向上:前世代のQwen-Image i2L(2025年12月発表)よりもスタイルを捉え、細部を再現する能力が向上;
-
✅ 実用的価値:スタイル移行時の細部保存率が20%向上し、アート創作、ECデザインなど多様なシーンに適応;
-
⚠️ 小さな欠点:単一画像入力時に過適合が発生する可能性があり、複雑なコンテンツでは複数の画像で補助的な最適化が必要。
-
⚠️ 無料オンライン体験:Z-Image i2L
デザイナー、AI绘画の愛好家、あるいは迅速にビジュアル素材を必要とする運営者であれば、このモデルはあなたの新しいお気に入りになる可能性が高いでしょう。誰が面倒なトレーニング手順を省き、ワンクリックで好きなスタイルを複製したくないと言えるでしょう?
まず理解しよう:Z-Image i2Lとは何か?一体どのような問題点を解決するのか?
多くの人が尋ねるかもしれませんが、LoRA生成は以前から存在しませんでしたか?このモデルは一体どこが特別なのでしょうか?
まず平易に説明します:LoRAとは簡単に言えば「スタイルテンプレート」です。LoRAを訓練すれば、AIは常に同じスタイルの画像を生成できます(例えば、専用水彩スタイル、企業ロゴスタイルなど)。
しかし、従来のLoRAトレーニングは、まるで「諦めさせるレベル」の操作です:数十枚から数百枚の同じスタイルの画像を準備し、数時間あるいはそれ以上かけてトレーニングし、さらにいくつかの技術パラメータを理解する必要があり、一般人には到底手に負えません。
通義Z-Image i2Lはまさにこの問題点を解決します。それは「Image to LoRA」(画像からLoRAへ)に特化しており、複雑な操作や大量のデータは不要で、単一の画像からエンドツーエンドで利用可能なLoRA重みを生成できます。
さらに親切なことに、PyTorchフレームワークをサポートし、消費者向けGPU(最低16GBメモリ)で動作します。推論時にcfg_scale=4、sigma_shift=8の2つのパラメータを設定するだけで、10秒以内にLoRAを生成でき、初心者でもすぐに使いこなせます。
アリババ公式はさえ、このモデルがZ-Image Baseより「より重要」(原文ではeven bigger deal)だと直言しています。なぜなら、単に生成画質を向上させるだけでなく、パーソナライズされたAI生成の敷居を最低レベルまで引き下げるからです。
i2Lは以前から発表されていませんでしたか?
実は以前に発表されたのはQwen-Image i2Lで、多くの人が混同します。なぜなら、両者は非常に似ているからです。
ここで明確にしておきます:Z-Image i2LはQwen-Image i2Lの進化版であり、代替版ではありません。両者はそれぞれ異なる重点を置いており、以下の表で区別できます:
| 対比次元 | Qwen-Image i2L | Z-Image i2L | キーポイント |
|---|---|---|---|
| アーキテクチャ基盤 | Qwen-Image(20B MMDiT) | Z-Image(6B DiT) | Z-Imageアーキテクチャはスタイル保存により重点を置いている |
| パラメータ規模 | 2.4B-7.9B(多バージョン) | 1.61B(単一バージョン) | パラメータ数が実力を表すわけではなく、Z-Image i2Lはより効率的 |
| スタイル抽出 | 細部より弱いが、一般的なスタイルが強い | スタイル保存を強化、細部損失率を20%低下 | 精確なスタイルを求めるならZ-Image i2Lを選択 |
| 内容保持 | 偏差を避けるため複数画像が必要 | より安定、単一画像で過適合しやすい | 複雑なコンテンツでは複数画像入力を推奨 |
| 生成速度 | 中程度、多段階イテレーションに依存 | より高速、エンドツーエンド<10秒 | 時間がかかる場合はZ-Image i2Lを優先 |
| 適用シーン | 初期スタイル試行、AI芸術の大衆化 | 専門デザイン、高速LoRA統合 | 必要に応じて選択、新しいものを追う必要なし |
簡潔にまとめます:スタイル抽出を試してみたい、初心者向けであれば、Qwen-Image i2Lで十分です。より精確なスタイル保存、より高速な生成速度が必要で、専門的な創作や商用シーンで使用する場合は、直接Z-Image i2Lを選ぶべきです。
核心的な利点の実測:20%の細部向上、これらのシーンで即効性を発揮
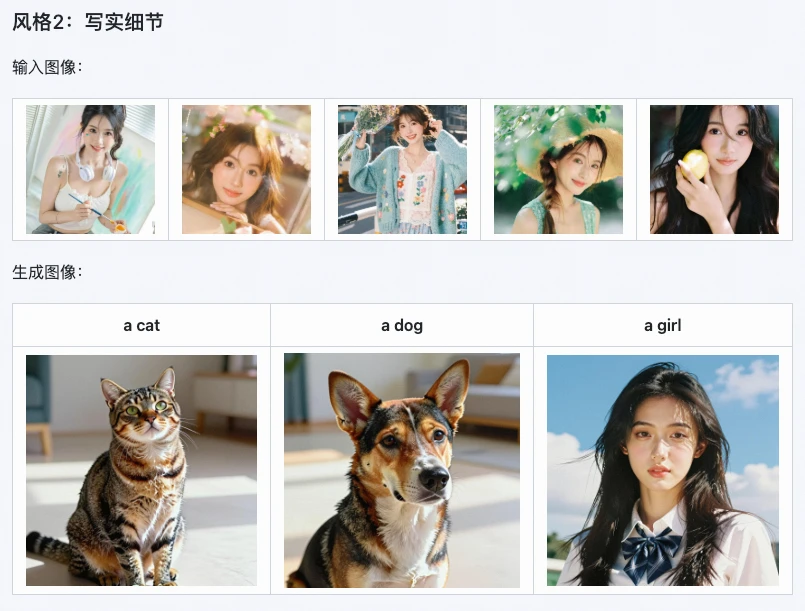
Z-Image i2Lの実際の性能はどうなのでしょうか。公式ベンチマークテストとユーザーフィードバックを組み合わせて、いくつかの核心的な利点を整理し、特にこれらのシーンに適しています:
1. スタイル保存を最大限に、細部損失率を20%直接低下
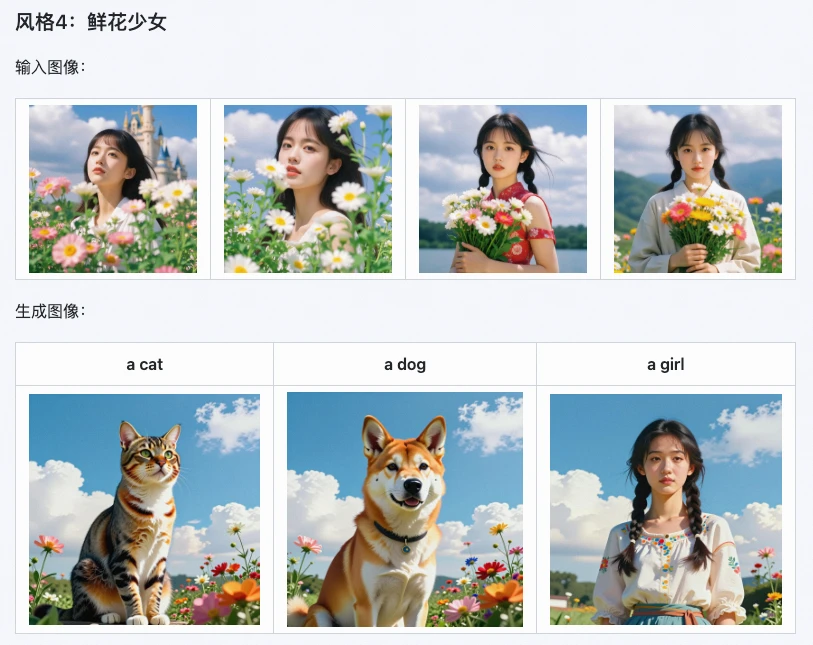
これがZ-Image i2Lの最も際立った利点です。公式テストによると、水彩、リアリズム、白黒ミニマルなど多様なアートスタイルにおいて、スタイル保存率は85%に達します。
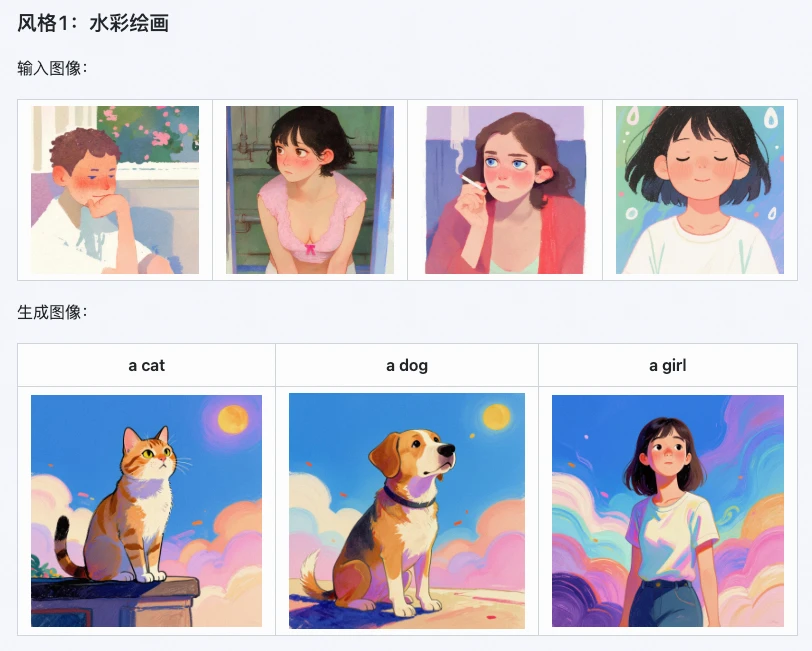
例えば、幻想世界スタイルの画像からLoRAを生成し、そのLoRAを使用して新しい画像を生成すると、細部損失率を15%低下できます。画面の光と影のレベルから全体のトーン雰囲気まで、正確に複製でき、「虎を描いて犬のようになる」という状況になりません。

2. 生成速度を2倍に、10秒でLoRAを出力、消費者向けデバイスでも動作
従来のLoRAトレーニングには数時間かかりますが、Z-Image i2LはエンドツーエンドでLoRAを生成し、時間は10秒未満で、前世代のQwen-Image i2Lより30%高速です。
さらに、デバイスの要求が高くなく、16GBメモリの消費者向けGPUがあればスムーズに動作し、高級サーバーの設定は不要です。一般家庭でも簡単に操作でき、本当に「即時生成、即時使用」を実現します。
3. アプリケーションシーンが非常に広く、大量の時間を節約してくれます
個人の創作から商用シーンまで、Z-Image i2Lは大きな役割を果たし、特にこれらの人々に適しています:
- デジタルアーティスト:専用スタイルのLoRAを迅速に生成し、同じスタイルのイラスト、コンセプトアートを一括で制作;
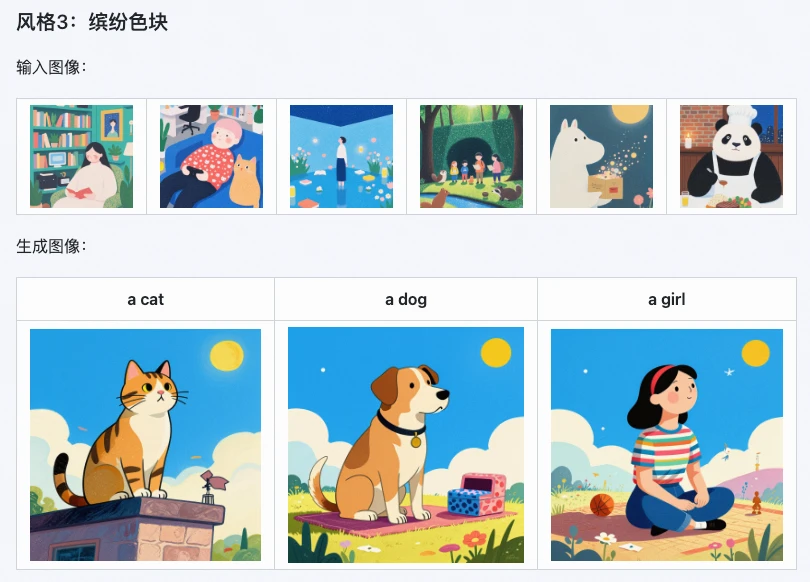
- ECデザイナー:製品パッケージ、ポスターのスタイルを複製し、迅速に多種類のデザインプロトタイプを作成し、創作サイクルを短縮;
- マスメディア/運営者:専用の画像スタイルを生成し、アカウントの視覚的トーンを統一し、素材を探したり画像を編集したりする必要がなくなります;
- 開発者:オープンソースで二次開発可能、Stable Diffusionなどのフレームワークに統合し、さらなる機能を拡張。
アリババ公式の報告によると、Z-Image i2Lを使用すると、製品デザインサイクルを30%-50%短縮でき、迅速なイテレーションが必要な商用シーンにとって、間違いなく「効率の神器」です。
小さな残念:これらの問題点に注意が必要
もちろん、完璧なモデルはなく、Z-Image i2Lにもいくつか改善できる点があります:
開発者からフィードバックがあり、単一画像入力時にモデルが過適合を起こす可能性がある(簡単に言えば「硬すぎる」ことで、生成された画像が入力画像とほぼ同じで多様性に欠ける)ことがあります。また、複雑なコンテンツ(例えば、複数の人物、複数のシーンの重なり)を処理する際には、細部捕捉にはまだ改善の余地があります。
しかし、アリババ公式も応答し、現在は差分トレーニングによって過適合問題を緩和しており、今後のイテレーションでさらに細部捕捉能力を最適化する予定で、期待できます。
最後に:このモデル、入手する価値はありますか?
総合的に見て、通義Z-Image i2Lには小さな欠点がありますが、確かに「欠点が長所を隠さない」モデルです。
その最大の価値は、パラメータがトップクラスであることではなく、「実用的」であることです。複雑なLoRAトレーニングを簡単で効率的にし、一般人でも簡単にパーソナライズされたAI生成を実現させ、専門的なクリエイターがより多くの時間を創作そのものに集中できるようにします。
さらに、オープンソースで商用利用可能で、著作権の心配もなく、個人の使用から商用開発まで非常に親切で、これはアリババ通義研究所が開発者とクリエイターに示した誠意です。
もしこれと同じスタイルのビジュアル素材を頻繁に生成する必要がある、あるいはAI画像生成に興味があるなら、ModelScopeやGitHubからダウンロードして試してみてください。10秒で専用LoRAを手に入れ、新しい世界の扉が開くかもしれません~
公式ダウンロード伝送門:modelscope
著者まとめ
Z-Image i2Lの正式発表に伴い、それはZ-Imageのパラメータ量が少なく、適応可能なスタイルが限られているという欠点を効果的に補い、このシリーズモデルの応用境界を大幅に広げ、「リアルな効果のみが際立つ」という限界を本当に打破し、多様なスタイル、全シーンでの効率的な適応を実現する見込みがあります。
現在、Z-Image製品全体のレイアウトはますます明確になっています。今回のアリババの取り組みは、オープンソースモデルのトップポジションを占めることに満足しておらず、むしろ現在のAI生成における「計算能力と品質」の固定的なジレンマを完全に打ち破り、パーソナライズされた創作権を本当に一般消費者の手中に届けることを目的としています。今後、より多くの新しいバリエーションが継続的にリリースされるにつれて、国内のオープンソースモデルは将来的にグーグルの関連モデルと対抗できる実力を持ち、さらには追い越すことも実現できるでしょう。
したがって、アリババの公式が「Z-Image Baseよりも重要である」と発言したのは、単なる誇大広告ではなく、Z-Image製品ラインの長期的な計画と、AI生成分野の将来発展に対する深い洞察である可能性があります。