
Alibaba Releases Z-Image i2L: Instant LoRA from a Single Image—More Revolutionary than the Base Model?
Is Alibaba's New Model Even More Revolutionary than Z-Image Base?
On January 27, 2026, Alibaba Tongyi Lab officially launched a brand-new model—Z-Image i2L.
Official statements claim that this Image-to-LoRA model, built on the Z-Image architecture, is even more disruptive than the previously popular Z-Image Base. With a 1.61B parameter scale, what exactly makes it "more important" than the world's leading open-source models?
Key highlights (TL;DR):
- ✅ Release Date: Jan 27, 2026, by Alibaba Tongyi Lab, open-source and commercially usable (Apache 2.0 license).
- ✅ Core Breakthrough: Instant LoRA generation from a single image; no massive datasets or hours of training required.
- ✅ Performance Upgrade: Significantly better style capturing and detail restoration compared to the predecessor Qwen-Image i2L (Dec 2025).
- ✅ Practical Value: 20% improvement in detail retention for style transfer, perfect for artistic creation and e-commerce design.
- ⚠️ Minor Drawback: Single-image input may lead to overfitting; complex content might require a few more images for optimization.
- ⚠️ Free online experience: Z-Image i2L
If you are a designer, AI art enthusiast, or a content creator needing fast visual assets, this model will likely become your new favorite—after all, who wouldn't want to skip tedious training and replicate their preferred style with one click?
Understanding Z-Image i2L: What Pain Point Does It Solve?
Many might ask: "Haven't we had LoRA generation for a while? What makes this model special?"
In simple terms: LoRA is a "style template." Once a LoRA is trained, the AI can consistently generate images in that specific style (e.g., a specific watercolor style or a corporate logo aesthetic).
However, traditional LoRA training is a "deal-breaker" for many: it requires preparing dozens or hundreds of consistent images, spending hours training, and understanding technical parameters. It's simply not accessible to everyone.
Alibaba Z-Image i2L solves this exact pain point. It focuses on "Image to LoRA," allowing users to generate usable LoRA weights end-to-end from just one image, without complex operations or large datasets.
Even better, it supports the PyTorch framework and can run on consumer-grade GPUs (minimum 16GB VRAM). By setting cfg_scale=4 and sigma_shift=8, you can generate a LoRA in under 10 seconds.
Alibaba officials have even stated that this model is an "even bigger deal" than Z-Image Base—because it doesn't just improve image quality; it lowers the barrier to personalized AI generation to its minimum.
Wait, Wasn't i2L Already Released?
Actually, what was released earlier was Qwen-Image i2L. Many people confuse the two because they share similar names.
To be clear: Z-Image i2L is an evolution of Qwen-Image i2L, not a replacement. Both have different focuses, as shown in the table below:
| Metric | Qwen-Image i2L | Z-Image i2L | Key Note |
|---|---|---|---|
| Architecture | Qwen-Image (20B MMDiT) | Z-Image (6B DiT) | Z-Image architecture specializes in style retention |
| Parameters | 2.4B - 7.9B (multiple versions) | 1.61B (single version) | Fewer parameters, but more efficient |
| Style Extraction | Weaker on details, stronger for general styles | Enhanced style preservation, 20% less detail loss | Choose Z-Image i2L for precision |
| Content Retention | Needs multiple images to avoid bias | More stable; single-image input may overfit | Use multiple images for complex content |
| Generation Speed | Medium (multi-stage iteration) | Faster (end-to-end < 10s) | Choose Z-Image i2L for speed |
| Best For | Initial style exploration | Professional design & rapid integration | Choose based on your needs |
Summary: If you're a beginner just testing style extraction, Qwen-Image i2L is sufficient. If you need precise style preservation and faster generation for professional or commercial use, go straight for Z-Image i2L.
Core Advantages Tested: 20% Detail Improvement
How does Z-Image i2L actually perform? Based on official benchmarks and user feedback, here are its standout features:
1. Superior Style Preservation
This is the model's biggest strength. Official tests show an 85% style retention rate across various artistic styles like watercolor, realism, and monochrome minimalism.
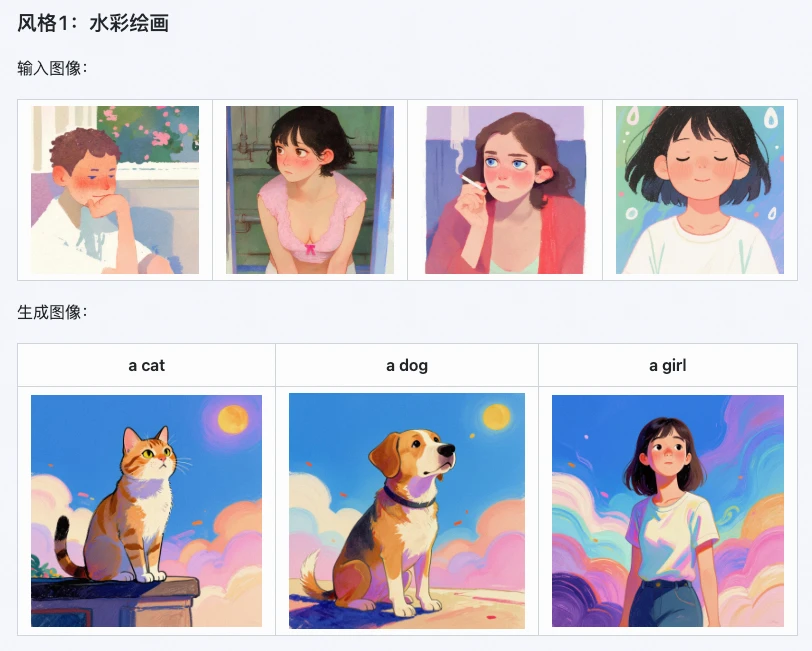
For instance, if you generate a LoRA from a single fantasy-world image, the detail loss is reduced by 15%—everything from lighting layers to the overall color palette is replicated accurately.

2. Doubled Generation Speed (LoRA in 10s)
Traditional training takes hours, but Z-Image i2L generates a LoRA end-to-end in less than 10 seconds. This is a 30% speed increase over Qwen-Image i2L. It runs smoothly on consumer-grade 16GB VRAM GPUs, making "instant generation, instant use" a reality for home users.
3. Broad Application Scenarios
Z-Image i2L is an efficiency powerhouse for:
- Digital Artists: Quickly generate style-specific LoRAs for batch-creating consistent illustrations.
- E-commerce Designers: Replicate product packaging or poster styles to create multiple design prototypes quickly.
- Content Creators: Create a unique brand style for social media accounts without manually editing every image.
- Developers: Open-source and ready for integration into frameworks like Stable Diffusion.
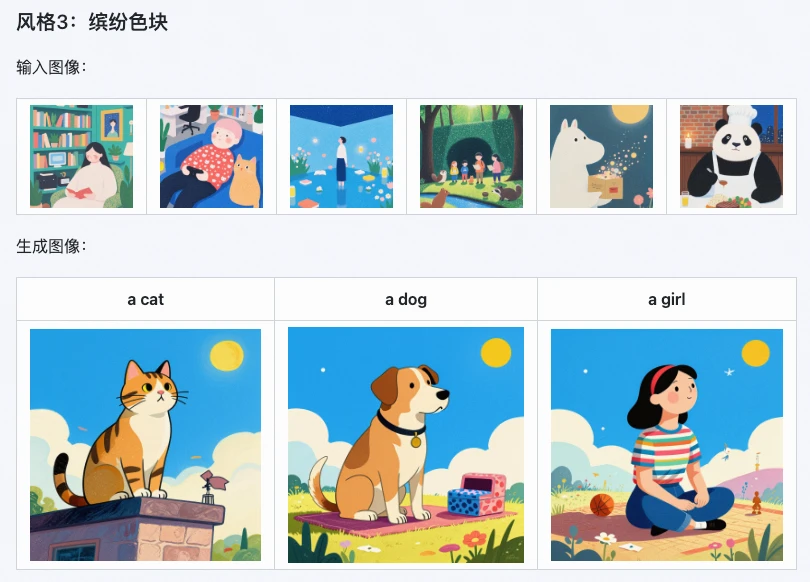
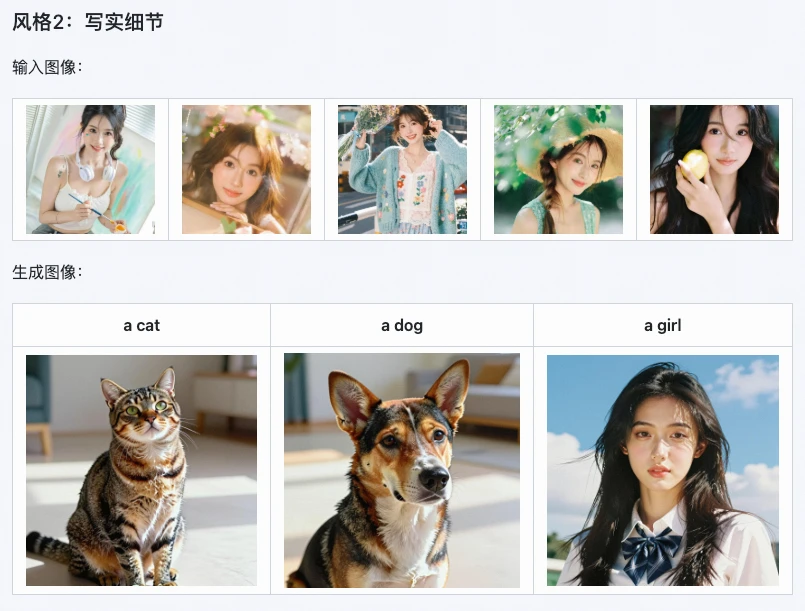
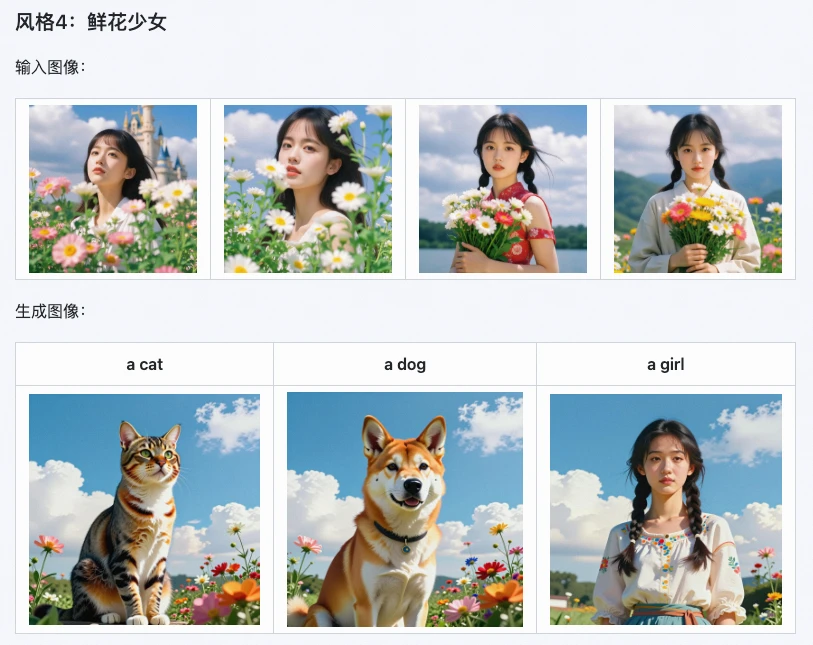
Alibaba reports that using Z-Image i2L can shorten the product design cycle by 30%-50%.
Minor Drawbacks: What to Keep in Mind
No model is perfect. Some developers have noted that single-image input can lead to overfitting (making the generated images too similar to the original). Capturing intricate details in complex scenes (like multiple people or crowded backgrounds) also has room for improvement.
However, Alibaba has already mitigated overfitting issues through differential training and plans further optimizations for detail capture in future iterations.
Final Verdict: Is It Worth Using?
Despite minor flaws, Z-Image i2L is a game-changer. Its greatest value isn't just technical superiority—it's its accessibility. By making complex LoRA training simple and efficient, it empowers both hobbyists and professionals to focus on creativity rather than technical hurdles.
Since it is open-source and commercially usable, it's a friendly tool for anyone looking to build or create with AI.
Check it out on ModelScope or GitHub to get your first custom LoRA in 10 seconds!
Official Download: ModelScope
Author's Summary
The release of Z-Image i2L effectively addresses the limitations of the previous Z-Image series, such as small parameter sizes and limited style adaptation. It moves beyond just "realistic" output to achieving high-efficiency adaptation across all styles and scenarios.
Alibaba's strategy is clear: they are aiming to break the "compute-vs-quality" bottleneck, bringing personalized creation to everyday users. As more variants are released, Chinese open-source models are poised to compete directly with global leaders like Google.
Perhaps Alibaba's claim that this is "more important than Z-Image Base" isn't just marketing hype, but a deep insight into the long-term future of AI-driven creative tools.