
阿里重磅發布 Z-Image i2L:單張圖秒出 LoRA,比 Base 模型更顛覆?
阿里發布的新模型竟然比Z-Image Base更重要?
2026年1月27日,阿里通義實驗室正式推出全新模型——Z-Image i2L
官方直言,這款基於Z-Image架構的Image to LoRA模型,比此前發布的Z-Image Base更具顛覆性。1.61B參數規模,到底有什麼過人之處,竟然敢說出比全球第一的開源模型還要重要?
先給大家劃重點(懶人直接看這裡):
-
✅ 發布時間:2026年1月27日,阿里通義實驗室出品,開源可商用(Apache 2.0許可);
-
✅ 核心突破:單張圖像就能即時生成LoRA,不用大量數據,不用熬幾小時訓練;
-
✅ 性能升級:比前代Qwen-Image i2L(2025年12月發布)更會抓風格、還原細節;
-
✅ 實用價值:風格遷移細節保存率提升20%,適配藝術創作、電商設計等多個場景;
-
⚠️ 小遺憾:單張圖輸入時可能出現過擬合,複雜內容需多幾張圖輔助優化。
-
⚠️ 免費在線體驗:Z-Image i2L
如果你是設計師、AI繪畫愛好者,或是需要快速出視覺素材的運營者,這款模型大概率會成為你的新寵——畢竟,誰不想省去繁瑣的訓練步驟,一鍵複刻自己喜歡的風格呢?
先搞懂:什麼是Z-Image i2L?它到底解決了什麼痛點?
很多人可能會問,LoRA生成不是早就有了嗎?這款模型到底特別在哪?
先通俗解釋下:LoRA簡單說就是"風格模板",訓練好一個LoRA,就能讓AI一直生成同一種風格的圖(比如專屬水彩風、企業LOGO風)。
但傳統LoRA訓練,簡直是"勸退級"操作:需要準備幾十上百張同風格圖片,再花幾小時甚至更久訓練,還得懂點技術參數,普通人根本玩不轉。
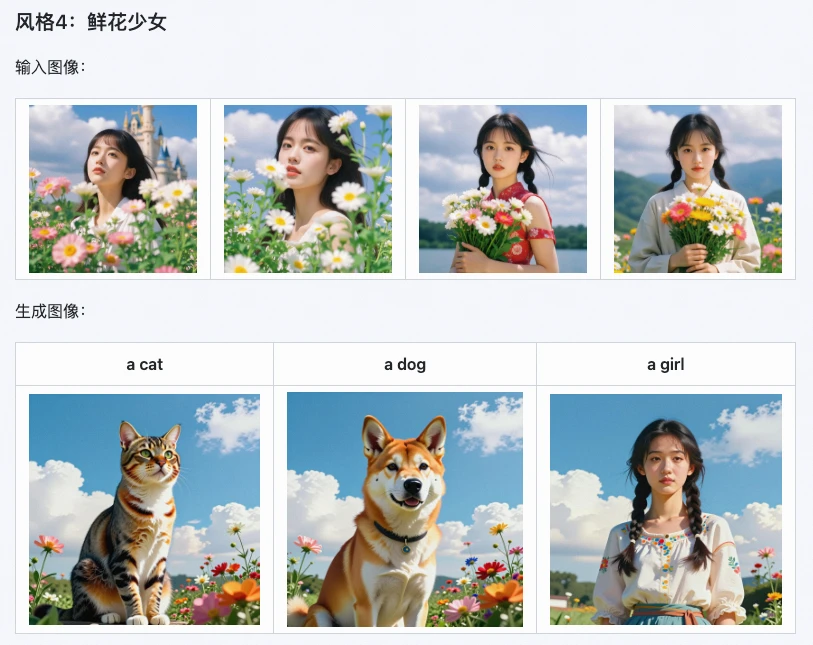
而通義Z-Image i2L,剛好解決了這個痛點——它專注於"Image to LoRA"(圖像轉LoRA),不用複雜操作,不用大量數據,只要一張圖,就能端到端生成可用的LoRA權重。
更友好的是,它支持PyTorch框架,消費級GPU(最低16GB顯存)就能跑,推理時設置cfg_scale=4、sigma_shift=8兩個參數,10秒內就能生成LoRA,新手也能快速上手。
阿里官方甚至直言,這款模型比Z-Image Base"更重磅"(原話even bigger deal)——因為它不是單純提升生成畫質,而是把個性化AI生成的門檻,拉到了最低。
i2L不是早就發布了麼?
其實之前發布的是Qwen-Image i2L,很多人會混淆,畢竟兩者實在太像了。
這裡給大家說清楚:Z-Image i2L是Qwen-Image i2L的演進版,不是替代版,兩者各有側重,一張表就能分清:
| 對比維度 | Qwen-Image i2L | Z-Image i2L | 關鍵提醒 |
|---|---|---|---|
| 架構基礎 | Qwen-Image(20B MMDiT) | Z-Image(6B DiT) | Z-Image架構更側重風格保存 |
| 參數規模 | 2.4B-7.9B(多版本) | 1.61B(單版本) | 參數不代表實力,Z-Image i2L更高效 |
| 風格提取 | 弱於細節,強於通用風格 | 增強風格保存,細節丟失率降20% | 追求精準風格選Z-Image i2L |
| 內容保留 | 需多圖像避免偏差 | 更穩定,單張易過擬合 | 複雜內容建議多圖輸入 |
| 生成速度 | 中等,依賴多階段迭代 | 更快,端到端<10秒 | 趕時間優先選Z-Image i2L |
| 適用場景 | 初期風格試錯、AI藝術平民化 | 專業設計、快速LoRA集成 | 按需選擇,不用盲目追新 |
簡單總結:如果只是想試試風格提取,新手入門,Qwen-Image i2L足夠用;如果需要更精準的風格保存、更快的生成速度,用於專業創作或商業場景,直接衝Z-Image i2L就對了。
核心優勢實測:20%細節提升,這些場景直接封神
Z-Image i2L的實際表現到底怎麼樣?我們結合官方基準測試和用戶反饋,整理了幾個核心優勢,尤其適合這些場景:
1. 風格保存拉滿,細節丟失率直降20%
這是Z-Image i2L最突出的優勢。官方測試顯示,它在水彩、現實主義、黑白極簡等多種藝術風格上,風格保存率高達85%,
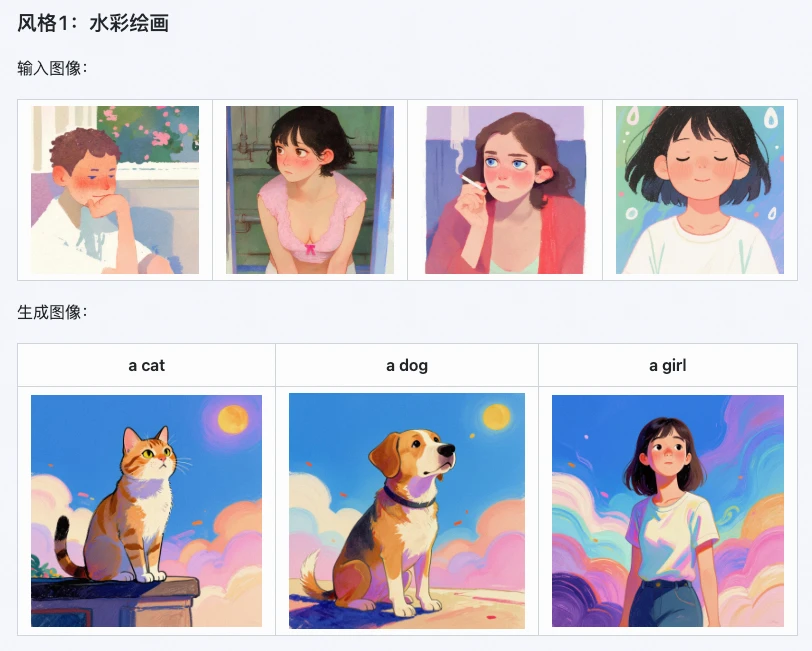
比如用一張幻想世界風格的圖生成LoRA,再用這個LoRA生成新圖,細節丟失率能降低15%——小到畫面的光影層次,大到整體的色調氛圍,都能精準複刻,不會出現"畫虎不成反類犬"的情況。

2. 生成速度翻倍,10秒出LoRA,消費級設備也能跑
傳統LoRA訓練要幾小時,而Z-Image i2L端到端生成LoRA,時間不到10秒,速度比前代Qwen-Image i2L提升了30%。
而且它對設備要求不高,只要有16GB顯存的消費級GPU,就能流暢運行,不用配置高端服務器,普通人在家也能輕鬆操作,真正實現"即時生成、即時使用"。
3. 應用場景極廣,幫你省出大量時間
不管是個人創作還是商業場景,Z-Image i2L都能派上大用場,尤其適合這幾類人:
- 數字藝術家:快速生成專屬風格LoRA,批量創作同風格插畫、概念圖;
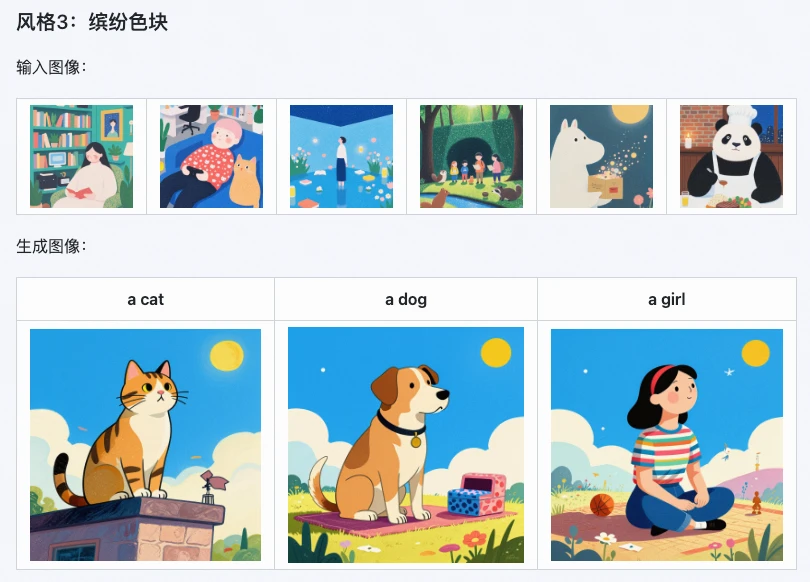
- 電商設計師:複刻產品包裝、海報風格,快速出多款設計原型,縮短創作周期;
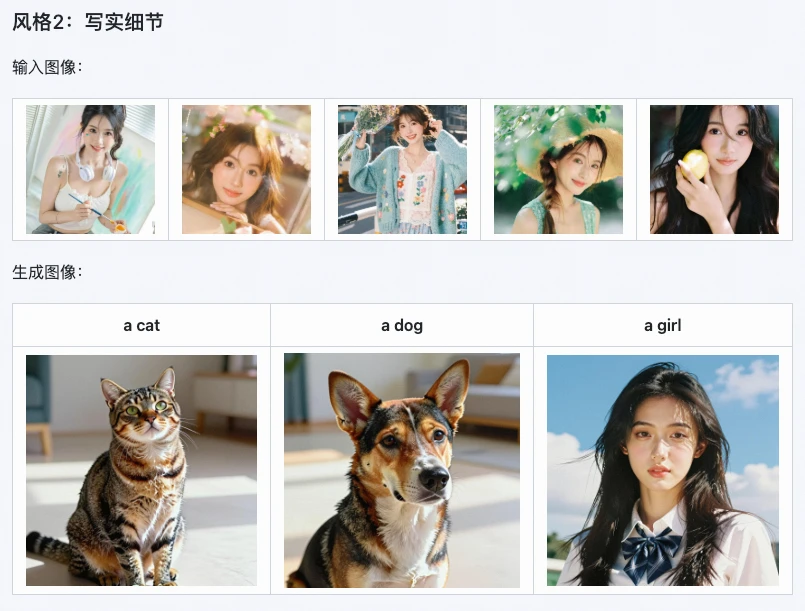
- 自媒體/運營者:生成專屬配圖風格,統一賬號視覺調性,不用再找素材、修圖;
- 開發者:開源可二次開發,集成到Stable Diffusion等框架中,拓展更多功能。
阿里官方報告顯示,用Z-Image i2L,能將產品設計周期縮短30%-50%,對於需要快速迭代的商業場景來說,無疑是"效率神器"。
小遺憾:這些問題需要注意
當然,沒有完美的模型,Z-Image i2L也有一些可優化的地方:
有開發者反饋,單張圖像輸入時,模型可能會出現過擬合(簡單說就是"太死板",生成的圖和輸入圖幾乎一樣,缺乏多樣性);另外,在處理複雜內容(比如多人、多場景疊加)時,細節捕捉還有提升空間。
不過阿里官方也回應,目前已經通過差分訓練緩解了過擬合問題,後續迭代會進一步優化細節捕捉能力,值得期待。
最後:這款模型,值得入手嗎?
綜合來看,通義Z-Image i2L雖然有小瑕疵,但絕對是一款"瑕不掩瑜"的模型。
它最大的價值,不是參數多頂尖,而是"接地氣"——把複雜的LoRA訓練變得簡單、高效,讓普通人也能輕鬆實現個性化AI生成,讓專業創作者省出更多時間專注於創意本身。
而且它開源可商用,沒有版權顧慮,不管是個人使用還是商業開發,都很友好,這也是阿里通義實驗室給開發者和創作者的誠意。
如果你經常需要生成同風格視覺素材,或對於AI圖像生成感興趣,不妨去ModelScope或GitHub下載試試,10秒就能get專屬LoRA,說不定會打開新世界的大門~
官方下載傳送門:modelscope
作者總結
隨著Z-Image i2L的正式發布,其有效彌補了Z-Image參數量偏小、適配風格有限的弊端,大幅拓寬了該系列模型的應用邊界,更有望真正打破"僅寫實效果突出"的局限,實現多風格、全場景的高效適配。
目前,Z-Image整條產品線的佈局已愈發清晰,阿里此次的發力,顯然不滿足於佔據開源模型的頭部位置,更旨在徹底打破當前AI生成中「算力與質量」的固有配比困境,讓個性化創作權真正下沉到普通消費者手中。隨著後續更多新變體的持續發布,國產開源模型未來有望真正具備與谷歌相關模型抗衡的實力,甚至實現彎道超車。
所以阿里官方說出它比Z-Image Base更加重要的言論,或許並不是簡誇大其詞,而是對Z-Image 產品線的長遠規劃,以及對AI生成领域未來發展的深刻洞察。