
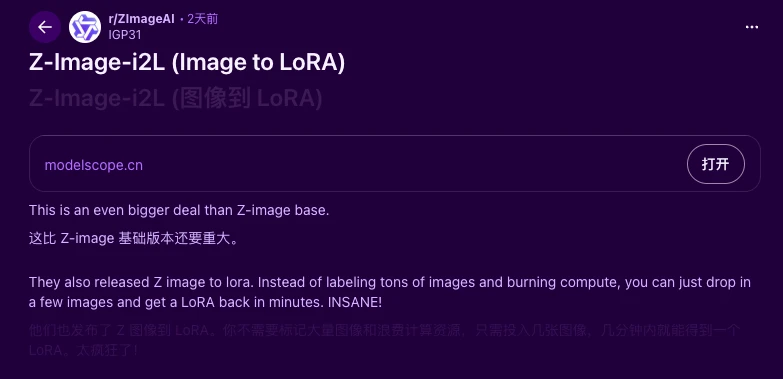
Alibaba lança Z-Image i2L: Geração de LoRA em segundos com uma única imagem, mais disruptivo que o modelo Base?
O novo modelo lançado pela Alibaba é realmente mais importante que o Z-Image Base?
Em 27 de janeiro de 2026, o laboratório Tongyi da Alibaba oficialmente lançou um novo modelo - Z-Image i2L
A equipe oficial afirma que este modelo Image to LoRA baseado na arquitetura Z-Image é mais disruptivo do que o Z-Image Base lançado anteriormente. Com 1,61B de parâmetros, o que há de tão especial nele para ousar dizer que é mais importante que o melhor modelo de código aberto do mundo?
Primeiro, vamos aos pontos principais (para os preguiçosos, leiam aqui diretamente):
-
✅ Data de lançamento: 27 de janeiro de 2026, produzido pelo laboratório Tongyi da Alibaba, código aberto e comercialmente disponível (licença Apache 2.0);
-
✅ Quebra de paradigma: geração instantânea de LoRA a partir de uma única imagem, sem necessidade de grandes volumes de dados ou horas de treinamento;
-
✅ Melhoria de desempenho: melhor captura de estilos e restauração de detalhes em comparação com a geração anterior Qwen-Image i2L (lançado em dezembro de 2025);
-
✅ Valor prático: aumento de 20% na taxa de preservação de detalhes na migração de estilos, adequado para múltiplos cenários como criação artística e design de e-commerce;
-
⚠️ Pequeno inconveniente: pode ocorrer sobreajuste com entrada de uma única imagem, conteúdo complexo requer várias imagens para otimização auxiliar.
-
⚠️ Experiência online gratuita: Z-Image i2L
Se você é um designer, entusiasta de pintura com IA ou um profissional de marketing que precisa gerar materiais visuais rapidamente, este modelo provavelmente se tornará seu novo favorito - afinal, quem não quer economizar as tediosas etapas de treinamento e replicar com um clique o estilo que ama?
Primeiro, vamos entender: o que é o Z-Image i2L? Que problemas ele resolve realmente?
Muitas pessoas podem perguntar, a geração de LoRA não existe há muito tempo? O que há de tão especial neste modelo?
Vamos explicar de forma simples: LoRA, em termos simples, é um "modelo de estilo". Depois de treinar um LoRA, a IA pode gerar continuamente imagens no mesmo estilo (por exemplo, estilo aquarela exclusivo ou estilo de logotipo corporativo).
Mas o treinamento tradicional de LoRA é uma operação "desencorajadora": requer a preparação de dezenas ou até centenas de imagens no mesmo estilo, leva várias horas ou mais para treinar, e ainda exige conhecimento de parâmetros técnicos, algo que a maioria das pessoas comuns não consegue manusear.
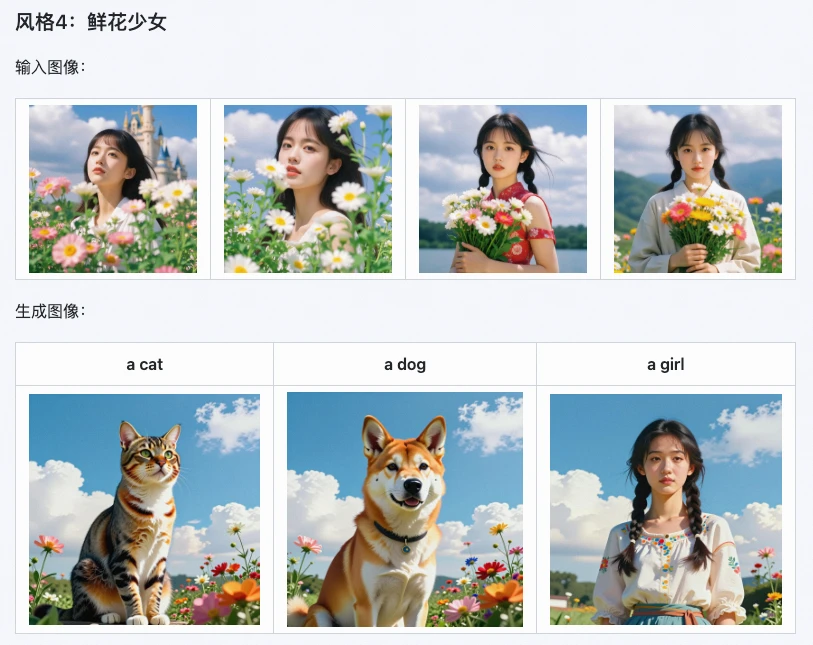
O Z-Image i2L da Tongyi resolve exatamente esse problema - ele se concentra em "Image to LoRA" (imagem para LoRA), sem operações complexas ou grandes volumes de dados, basta uma imagem para gerar pesos de LoRA utilizáveis de ponta a ponta.
O que é mais amigável é que ele suporta o framework PyTorch e pode ser executado em GPUs de consumo (com mínimo de 16GB de VRAM). Durante a inferência, configurando apenas dois parâmetros, cfg_scale=4 e sigma_shift=8, o LoRA pode ser gerado em menos de 10 segundos, permitindo que iniciantes comecem rapidamente.
A equipe oficial da Alibaba até afirma que este modelo é "mais significativo" do que o Z-Image Base (na frase original, 'even bigger deal') - porque ele não apenas melhora a qualidade das imagens geradas, mas também reduz ao mínimo o limiar para a geração personalizada de IA.
O i2L não foi lançado há muito tempo?
Na verdade, o que foi lançado anteriormente foi o Qwen-Image i2L, e muitas pessoas os confundem, afinal são muito semelhantes.
Vamos esclarecer para todos: o Z-Image i2L é uma versão evolutiva do Qwen-Image i2L, não um substituto. Ambos têm seus focos específicos, e uma tabela pode deixar claro:
| Dimensão de comparação | Qwen-Image i2L | Z-Image i2L | Aviso importante |
|---|---|---|---|
| Base arquitetônica | Qwen-Image (20B MMDiT) | Z-Image (6B DiT) | A arquitetura Z-Image foca mais na preservação de estilos |
| Escala de parâmetros | 2.4B-7.9B (múltiplas versões) | 1.61B (versão única) | Parâmetros não representam poder, o Z-Image i2L é mais eficiente |
| Extração de estilo | Fraco em detalhes, forte em estilos gerais | Melhora preservação de estilos, redução de 20% na perda de detalhes | Para precisão de estilo, escolha Z-Image i2L |
| Preservação de conteúdo | Necessita de múltiplas imagens para evitar viés | Mais estável, único imagem pode causar sobreajuste | Conteúdo complexo requer múltiplas imagens |
| Velocidade de geração | Média, depende de iteração multiestágio | Mais rápida, ponta a ponta <10s | Para pressa, priorize Z-Image i2L |
| Cenários aplicáveis | Experimentação inicial de estilos, popularização da arte com IA | Design profissional, integração rápida de LoRA | Escolha conforme necessidade, sem seguir cegamente o novo |
Resumindo simplesmente: se você só quer experimentar extração de estilos ou é um iniciante, o Qwen-Image i2L é suficiente; se precisar de preservação de estilos mais precisa e geração mais rápida para criação profissional ou cenários comerciais, o Z-Image i2L é a escolha certa.
Vantagens principais testadas: 20% de melhoria nos detalhes, esses cenários são simplesmente divinos
Qual é o desempenho real do Z-Image i2L? Combinando testes oficiais e feedback de usuários, compilamos algumas vantagens principais, especialmente adequadas para estes cenários:
1. Preservação de estilos no máximo, taxa de perda de detalhes reduzida em 20%
Esta é a vantagem mais proeminente do Z-Image i2L. Os testes oficiais mostram que ele alcança uma taxa de preservação de estilos de 85% em múltiplos estilos artísticos como aquarela, realismo e minimalismo em preto e branco,
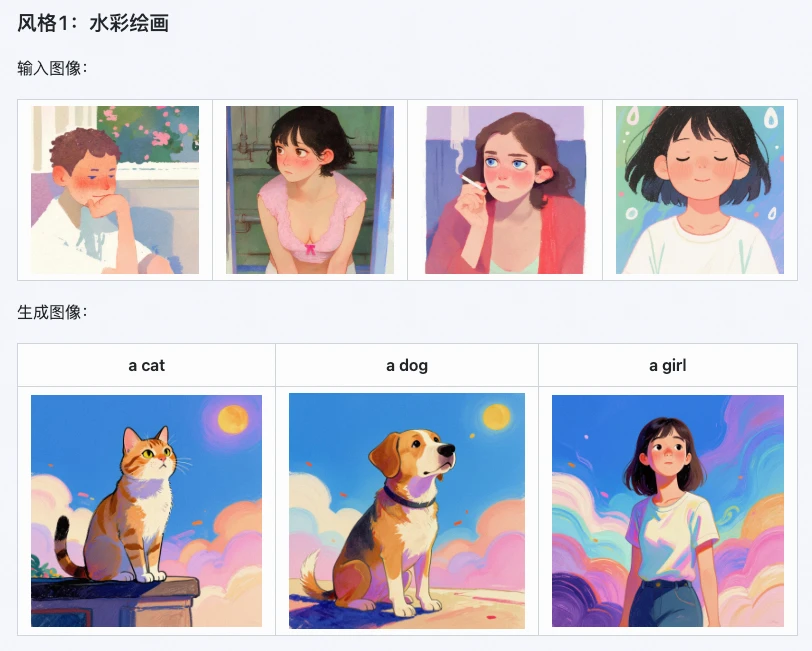
Por exemplo, usar uma imagem de estilo mundo fantástico para gerar um LoRA, e depois usar esse LoRA para gerar novas imagens, pode reduzir a taxa de perda de detalhes em 15% - desde as camadas de luz e sombra na imagem até o tom geral da atmosfera, tudo pode ser replicado com precisão, sem o problema de "tentar pintar um tigre e acabar com um cão".

2. Velocidade de geração duplicada, LoRA em 10 segundos, pode ser executado em dispositivos de consumo
O treinamento tradicional de LoRA leva várias horas, enquanto o Z-Image i2L gera LoRA de ponta a ponta em menos de 10 segundos, com um aumento de velocidade de 30% em comparação com a geração anterior Qwen-Image i2L.
Além disso, seus requisitos de dispositivo não são altos; com uma GPU de consumo de apenas 16GB de VRAM, pode ser executado suavemente, sem necessidade de configurar servidores de alto nível. Pessoas comuns podem operá-lo facilmente em casa, realizando verdadeiramente "geração instantânea, uso instantâneo".
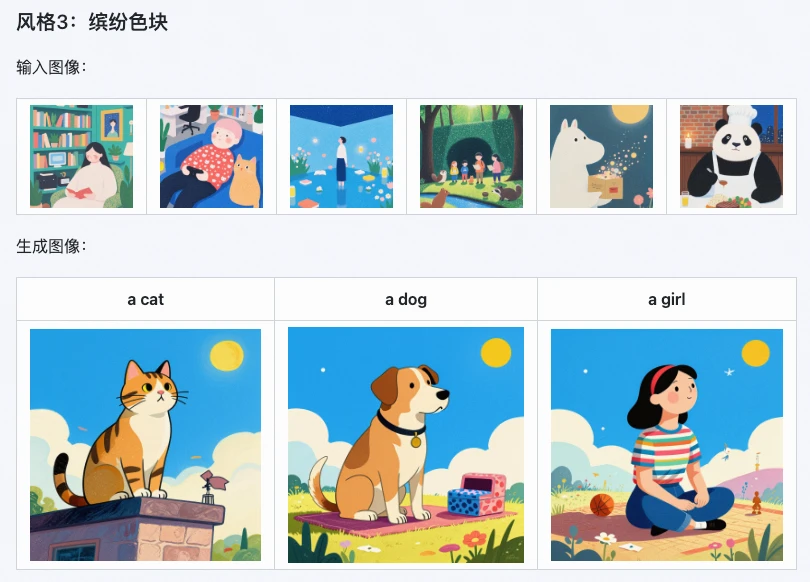
3. Aplicações extremamente amplas, economizando muito tempo
Seja para criação pessoal ou cenários comerciais, o Z-Image i2L pode ser muito útil, especialmente para estas categorias de pessoas:
- Artistas digitais: gerar rapidamente LoRA de estilo exclusivo para criar em lote ilustrações e conceitos no mesmo estilo;
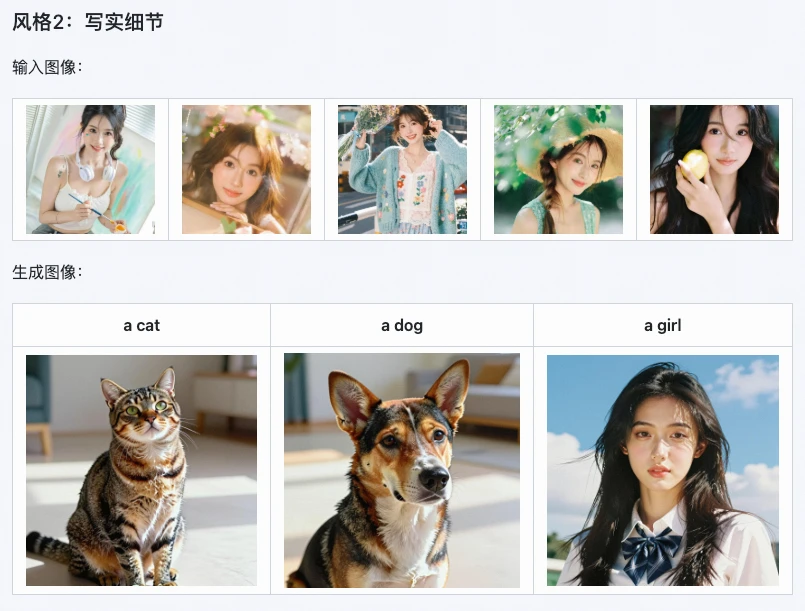
- Designers de e-commerce: replicar estilos de embalagens de produtos e pôsteres, gerar rapidamente múltiplos protótipos de design, encurtando o ciclo de criação;
- Criadores de conteúdo/operadores: gerar estilos de imagens exclusivos para unificar a identidade visual da conta, sem precisar mais procurar materiais ou editar imagens;
- Desenvolvedores: código aberto para desenvolvimento secundário, integração em frameworks como Stable Diffusion para expandir mais funcionalidades.
Relatórios oficiais da Alibaba mostram que o uso do Z-Image i2L pode encurtar o ciclo de design de produtos em 30%-50%, o que é indiscutivelmente uma "ferramenta de eficiência" para cenários comerciais que exigem rápida iteração.
Pequenos inconvenientes: estes problemas precisam de atenção
Claro, não há modelos perfeitos, e o Z-Image i2L também tem alguns aspectos que podem ser otimizados:
Desenvolvedores relataram que com entrada de uma única imagem, o modelo pode apresentar sobreajuste (em termos simples, "muito rígido", as imagens geradas são quase idênticas à imagem de entrada, sem diversidade); além disso, ao lidar com conteúdo complexo (como múltiplas pessoas ou sobreposição de múltiplos cenários), ainda há espaço para melhoria na captura de detalhes.
No entanto, a equipe oficial da Alibaba também respondeu que já mitigou o problema de sobreajuste através de treinamento diferencial, e as iterações futuras otimizarão ainda mais a capacidade de captura de detalhes, o que vale a pena esperar.
Finalmente: vale a pena adquirir este modelo?
De forma geral, embora o Z-Image i2L da Tongyi tenha pequenas falhas, é absolutamente um modelo "cujas falhas não ofuscam suas qualidades".
Seu maior valor não está nos parâmetros de ponta, mas em ser "prático" - tornar o complexo treinamento de LoRA simples e eficiente, permitindo que pessoas comuns também realizem facilmente geração personalizada de IA, e permitindo que criadores profissionais economizem mais tempo focando na criatividade em si.
Além disso, sendo de código aberto e comercializável, sem preocupações com direitos autorais, é amigável tanto para uso pessoal quanto para desenvolvimento comercial, o que demonstra a boa vontade do laboratório Tongyi da Alibaba para desenvolvedores e criadores.
Se você frequentemente precisa gerar materiais visuais no mesmo estilo ou tem interesse na geração de imagens com IA, não hesite em baixar e experimentar no ModelScope ou GitHub. Em 10 segundos você pode obter seu LoRA exclusivo, quem sabe isso não abrirá as portas para um novo mundo~
Portal de download oficial: modelscope
Conclusão do autor
Com o lançamento oficial do Z-Image i2L, ele efetivamente compensa as desvantagens do Z-Image, como o número relativamente pequeno de parâmetros e a limitação de estilos adaptáveis, ampliando significativamente os limites de aplicação desta série de modelos. Ele tem grandes perspectivas para verdadeiramente quebrar a limitação de "apenas efeitos realistas proeminentes" e realizar adaptação eficiente de múltiplos estilos e cenários completos.
Atualmente, o layout de toda a linha de produtos Z-Image tornou-se cada vez mais claro. O esforço desta vez da Alibaba obviamente não se satisfaz em ocupar a posição de liderança em modelos de código aberto, mas visa quebrar completamente o dilema inerente de "potência computacional e qualidade" na geração de IA, permitindo que o direito de criação personalizada realmente chegue às mãos dos consumidores comuns. Com o lançamento contínuo de mais novas variantes no futuro, os modelos de código aberto nacionais têm a potencialidade de realmente possuir a capacidade de competir com os modelos relacionados do Google, e até mesmo realizar uma ultrapassagem em curva.
Portanto, quando a Alibaba oficialmente afirma que o Z-Image é mais importante que o Z-Image Base, talvez não seja simplesmente uma exageração, mas sim um planejamento de longo prazo para a linha de produtos Z-Image e uma profunda compreensão sobre o desenvolvimento futuro do campo da geração de IA.