
Z-Image GGUF 实战指南:用消费级显卡解锁顶尖 AI 绘画(浅出版)
Z-Image GGUF 实战指南:用消费级显卡解锁顶尖 AI 绘画(浅出版)
1. 引言:打破“显卡焦虑”,6GB 也能跑大模型
在 AI 绘画的世界里,画质越好、理解能力越强的模型,往往体积也越庞大。Z-Image Turbo 凭借其惊人的 60 亿参数(6B)和卓越的中文理解能力,被誉为“目前最佳开源图像生成器”之一。但随之而来的是对硬件的严苛要求——满血版模型通常需要 20GB 以上的显存,这让大多数持有 RTX 3060 或 4060 等消费级显卡的用户望而却步。
好消息是,“算力门槛”已经被打破了。
通过 GGUF 量化技术,原本庞大的模型被成功“瘦身”。现在,即使你只有一块 6GB 显存 的入门级显卡,也能在本地流畅运行这款顶尖模型,享受专业级的 AI 创作体验。本文将避开晦涩的数学公式,手把手教你如何实现这一“魔法”。
2. 核心揭秘:把“大象”装进“冰箱”的魔法

为什么性能顶尖的模型能在普通显卡上运行?这得益于 GGUF 格式 和 量化技术。
你可以把这想象成一种极致的“压缩术”:
-
GGUF 格式(智能集装箱):
传统的模型加载像是一次性把整个房子搬进内存。而 GGUF 就像一个设计精妙的集装箱系统,它支持“按需取用”。系统不需要一次性把整个模型读入显存,而是像查字典一样,用到哪部分就读取哪部分。配合“内存映射”技术,它还能灵活地利用系统内存(RAM)来辅助显存。 -
量化技术(把百科全书变成口袋书):
原始模型使用高精度数字(FP16)存储,就像一本厚重的全彩百科全书,精准但占地儿。量化技术(如 4-bit 量化)通过复杂的算法,将这些数字压缩成整数。这好比把百科全书压缩成了黑白的“口袋精华版”。虽然丢失了极其微小的精度(肉眼几乎不可见),但体积直接缩小了 70%!
效果对比:
- 原始模型:需要 ~20GB 显存。
- GGUF (Q4) 版本:仅需 ~6GB 显存。
3. 硬件自检:我的电脑能跑哪个版本?
GGUF 版本提供了多种“压缩等级”(量化级别),你需要根据自己的显存大小“看菜吃饭”。请对照下表选择最适合你的版本:
| 显存 (VRAM) | 推荐量化版本 | 文件名示例 | 体验预期 |
|---|---|---|---|
| 6 GB (入门) | Q3_K_S | z-image-turbo-q3_k_s.gguf |
可玩。画质略有折损,但能流畅运行。这是这一档位的最优解。 |
| 8 GB (主流) | Q4_K_M | z-image-turbo-q4_k_m.gguf |
完美平衡。画质与原始模型肉眼几乎无异,速度适中,强烈推荐。 |
| 12 GB+ (进阶) | Q6_K 或 Q8_0 | z-image-turbo-q8_0.gguf |
极致画质。追求无损细节的发烧友选择。 |
💡 避坑指南:
- 系统内存 (RAM):建议至少 16GB,最好 32GB。当显存不够时,系统内存会来“救急”,如果内存也小,电脑会卡死。
- 硬盘:必须放在 SSD (固态硬盘) 上。模型需要在内存和显存间频繁搬运,机械硬盘的速度会让你等到地老天荒。
4. 保姆级部署教程(ComfyUI 篇)
我们推荐使用 ComfyUI,它是目前对 GGUF 支持最好、通过性最高的工具。
第一步:准备“三个神器”
要运行 Z-Image,你需要下载三个核心文件。请前往 HuggingFace 或国内镜像站下载:
-
大模型主体 (UNet):
- GGUF模型下载地址:
- 根据上表下载对应的
.gguf文件(例如z-image-turbo-q4_k_m.gguf)。 - 📂 存放位置:
ComfyUI/models/unet/
-
文本编码器 (Text Encoder):
Z-Image 听得懂中文,因为它挂载了强大的 Qwen3 (通义千问) 语言模型。请务必下载 Qwen3-4B 的 GGUF 版本(推荐Q4_K_M),否则光这个语言模型就会撑爆你的显存!- 下载地址:https://huggingface.co/unsloth/Qwen3-4B-GGUF/
- 📂 存放位置:
ComfyUI/models/text_encoders/
-
解码器 (VAE):
这是把数据变成图片的最后一步。使用通用的 Flux VAE (ae.safetensors) 即可。- 📂 存放位置:
ComfyUI/models/vae/
- 📂 存放位置:
第二步:安装关键插件
ComfyUI 原生不支持 GGUF,你需要安装 ComfyUI-GGUF 插件。
- 打开
ComfyUI Manager-> 点击Install Custom Nodes-> 搜索GGUF-> 安装作者为city96的插件 -> 重启 ComfyUI。
第三步:连接工作流

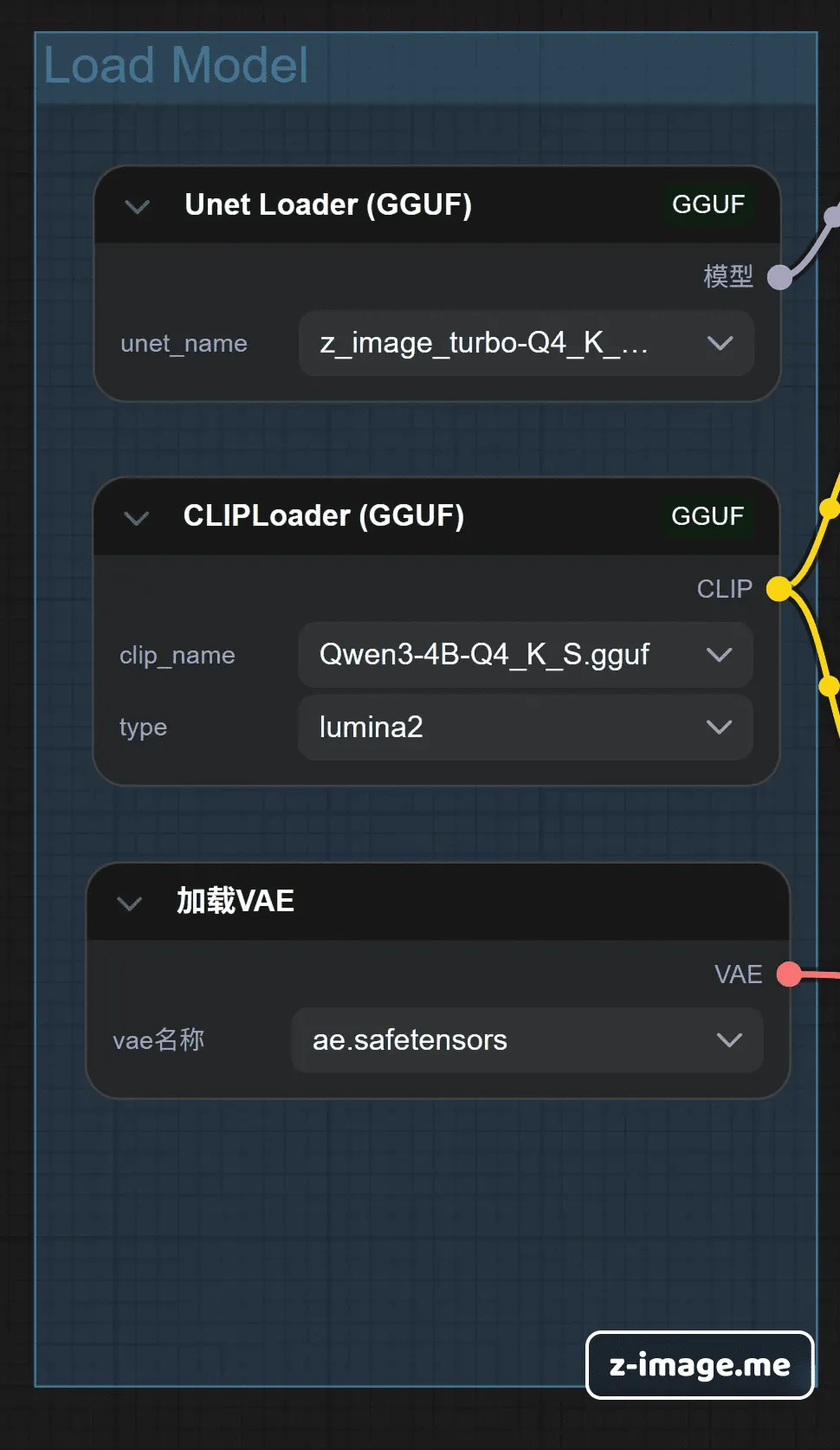
不像以前只有一个 "Checkpoint Loader",我们需要像搭积木一样分别加载这三个部分。
- 加载 UNet:使用
Unet Loader (GGUF)节点,选择你下载的 main model。 - 加载 CLIP:使用
ClipLoader (GGUF)节点,选择你下载的 Qwen3 模型。注意:不要用普通的 CLIP Loader,否则会报错! - 加载 VAE:使用标准的
Load VAE节点。 - 最后:将它们分别连入
KSampler(采样器) 对应的插孔。
5. 实战技巧:如何画出好图且不爆显存
配置好了?这里有几个独家秘籍,能帮你少走弯路:
🔧 核心参数设置 (抄作业)
Z-Image Turbo 是个急性子,不需要画很久。
- Steps (步数):设置为 8 - 10 步。千万别设 20 或 30,画多了反而会画崩(出现伪影)。
- CFG (提示词相关性):锁死在 1.0。Turbo 模型不需要高 CFG,高了画面会过饱和、发灰。
- Sampler (采样器):推荐
euler。简单、快、顺滑。
🇨🇳 中文提示词怎么玩?
Z-Image 的一大杀手锏是原生支持中文,甚至能理解成语和古诗。
- 尝试输入:“一位身穿汉服的少女,站在烟雨江南的桥头,背景是水墨山水,cinematic lighting(电影感光效)”。

- 想生成文字? 用引号包起来:“一个木质招牌,上面写着 "龙井茶庄"”。它真的能写对汉字!

🆘 救命!爆显存了 (OOM) 怎么办?
如果进度条走到一半报错 "Out Of Memory":
- 降分辨率:从
1024x1024降到896x896或768x1024。这能立竿见影地省显存。 - 启动项优化:在 ComfyUI 的启动脚本中加上
--lowvram参数。它会牺牲一点速度,强制每一步都清空显存,但能保证让你跑起来。 - 关闭浏览器:Chrome 可是吃内存大户,生成图片时,试着把那几十个标签页关了吧。